 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved DDIM Sampling with Moment Matching Gaussian Mixtures
Nov 08, 2023We propose using a Gaussian Mixture Model (GMM) as reverse transition operator (kernel) within the Denoising Diffusion Implicit Models (DDIM) framework, which is one of the most widely used approaches for accelerated sampling from pre-trained Denoising Diffusion Probabilistic Models (DDPM). Specifically we match the first and second order central moments of the DDPM forward marginals by constraining the parameters of the GMM. We see that moment matching is sufficient to obtain samples with equal or better quality than the original DDIM with Gaussian kernels. We provide experimental results with unconditional models trained on CelebAHQ and FFHQ and class-conditional models trained on ImageNet datasets respectively. Our results suggest that using the GMM kernel leads to significant improvements in the quality of the generated samples when the number of sampling steps is small, as measured by FID and IS metrics. For example on ImageNet 256x256, using 10 sampling steps, we achieve a FID of 6.94 and IS of 207.85 with a GMM kernel compared to 10.15 and 196.73 respectively with a Gaussian kernel.
Probabilistic Attention for Interactive Segmentation
Jul 02, 2021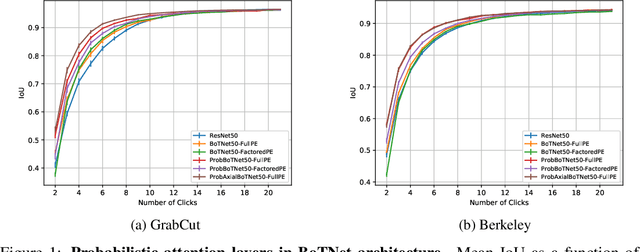
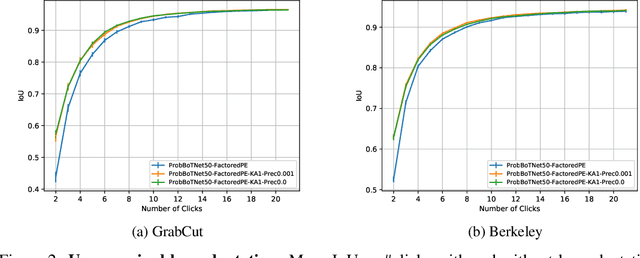
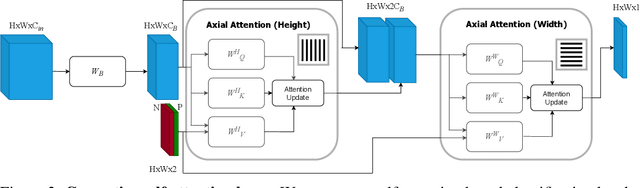
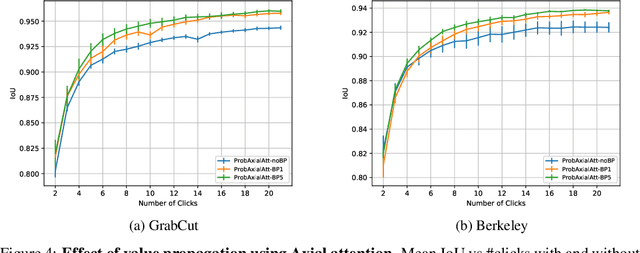
We provide a probabilistic interpretation of attention and show that the standard dot-product attention in transformers is a special case of Maximum A Posteriori (MAP) inference. The proposed approach suggests the use of Expectation Maximization algorithms for online adaptation of key and value model parameters. This approach is useful for cases in which external agents, e.g., annotators, provide inference-time information about the correct values of some tokens, e.g, the semantic category of some pixels, and we need for this new information to propagate to other tokens in a principled manner. We illustrate the approach on an interactive semantic segmentation task in which annotators and models collaborate online to improve annotation efficiency. Using standard benchmarks, we observe that key adaptation boosts model performance ($\sim10\%$ mIoU) in the low feedback regime and value propagation improves model responsiveness in the high feedback regime. A PyTorch layer implementation of our probabilistic attention model will be made publicly available here: https://github.com/apple/ml-probabilistic-attention.