 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRooms from Motion: Un-posed Indoor 3D Object Detection as Localization and Mapping
May 29, 2025We revisit scene-level 3D object detection as the output of an object-centric framework capable of both localization and mapping using 3D oriented boxes as the underlying geometric primitive. While existing 3D object detection approaches operate globally and implicitly rely on the a priori existence of metric camera poses, our method, Rooms from Motion (RfM) operates on a collection of un-posed images. By replacing the standard 2D keypoint-based matcher of structure-from-motion with an object-centric matcher based on image-derived 3D boxes, we estimate metric camera poses, object tracks, and finally produce a global, semantic 3D object map. When a priori pose is available, we can significantly improve map quality through optimization of global 3D boxes against individual observations. RfM shows strong localization performance and subsequently produces maps of higher quality than leading point-based and multi-view 3D object detection methods on CA-1M and ScanNet++, despite these global methods relying on overparameterization through point clouds or dense volumes. Rooms from Motion achieves a general, object-centric representation which not only extends the work of Cubify Anything to full scenes but also allows for inherently sparse localization and parametric mapping proportional to the number of objects in a scene.
MM-Spatial: Exploring 3D Spatial Understanding in Multimodal LLMs
Mar 17, 2025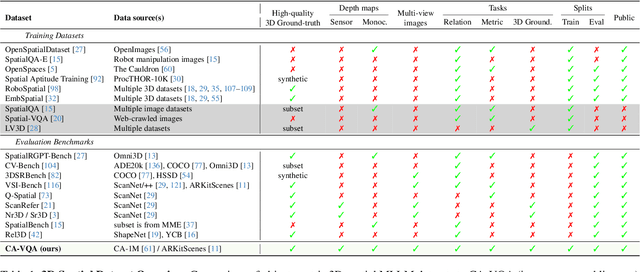

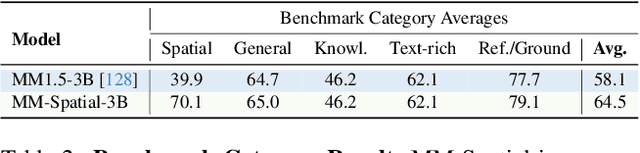

Multimodal large language models (MLLMs) excel at 2D visual understanding but remain limited in their ability to reason about 3D space. In this work, we leverage large-scale high-quality 3D scene data with open-set annotations to introduce 1) a novel supervised fine-tuning dataset and 2) a new evaluation benchmark, focused on indoor scenes. Our Cubify Anything VQA (CA-VQA) data covers diverse spatial tasks including spatial relationship prediction, metric size and distance estimation, and 3D grounding. We show that CA-VQA enables us to train MM-Spatial, a strong generalist MLLM that also achieves state-of-the-art performance on 3D spatial understanding benchmarks, including our own. We show how incorporating metric depth and multi-view inputs (provided in CA-VQA) can further improve 3D understanding, and demonstrate that data alone allows our model to achieve depth perception capabilities comparable to dedicated monocular depth estimation models. We will publish our SFT dataset and benchmark.
Cubify Anything: Scaling Indoor 3D Object Detection
Dec 05, 2024



We consider indoor 3D object detection with respect to a single RGB(-D) frame acquired from a commodity handheld device. We seek to significantly advance the status quo with respect to both data and modeling. First, we establish that existing datasets have significant limitations to scale, accuracy, and diversity of objects. As a result, we introduce the Cubify-Anything 1M (CA-1M) dataset, which exhaustively labels over 400K 3D objects on over 1K highly accurate laser-scanned scenes with near-perfect registration to over 3.5K handheld, egocentric captures. Next, we establish Cubify Transformer (CuTR), a fully Transformer 3D object detection baseline which rather than operating in 3D on point or voxel-based representations, predicts 3D boxes directly from 2D features derived from RGB(-D) inputs. While this approach lacks any 3D inductive biases, we show that paired with CA-1M, CuTR outperforms point-based methods - accurately recalling over 62% of objects in 3D, and is significantly more capable at handling noise and uncertainty present in commodity LiDAR-derived depth maps while also providing promising RGB only performance without architecture changes. Furthermore, by pre-training on CA-1M, CuTR can outperform point-based methods on a more diverse variant of SUN RGB-D - supporting the notion that while inductive biases in 3D are useful at the smaller sizes of existing datasets, they fail to scale to the data-rich regime of CA-1M. Overall, this dataset and baseline model provide strong evidence that we are moving towards models which can effectively Cubify Anything.
Layout Generation and Completion with Self-attention
Jun 25, 2020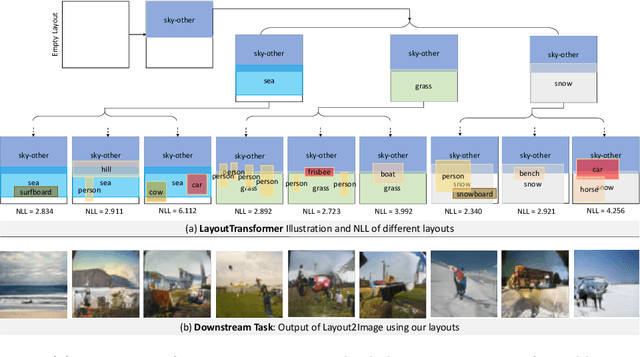
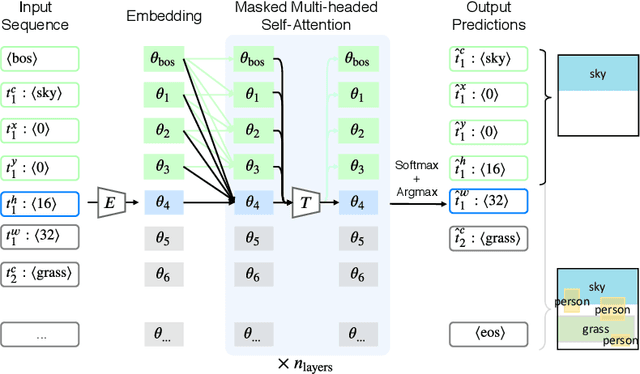


We address the problem of layout generation for diverse domains such as images, documents, and mobile applications. A layout is a set of graphical elements, belonging to one or more categories, placed together in a meaningful way. Generating a new layout or extending an existing layout requires understanding the relationships between these graphical elements. To do this, we propose a novel framework, LayoutTransformer, that leverages a self-attention based approach to learn contextual relationships between layout elements and generate layouts in a given domain. The proposed model improves upon the state-of-the-art approaches in layout generation in four ways. First, our model can generate a new layout either from an empty set or add more elements to a partial layout starting from an initial set of elements. Second, as the approach is attention-based, we can visualize which previous elements the model is attending to predict the next element, thereby providing an interpretable sequence of layout elements. Third, our model can easily scale to support both a large number of element categories and a large number of elements per layout. Finally, the model also produces an embedding for various element categories, which can be used to explore the relationships between the categories. We demonstrate with experiments that our model can produce meaningful layouts in diverse settings such as object bounding boxes in scenes (COCO bounding boxes), documents (PubLayNet), and mobile applications (RICO dataset).
Unaligned Image-to-Sequence Transformation with Loop Consistency
Oct 09, 2019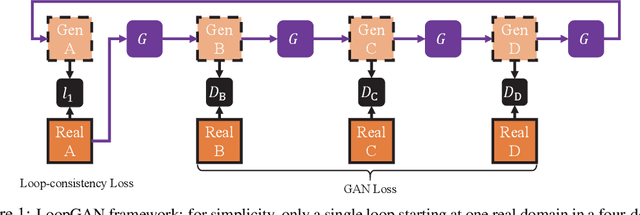
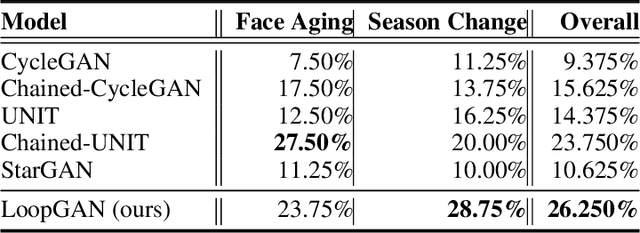
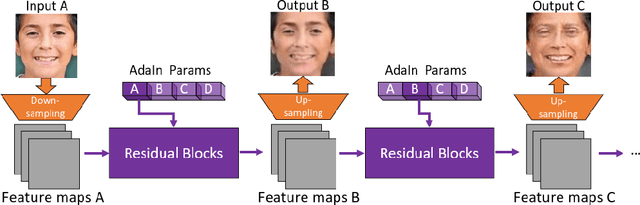

We tackle the problem of modeling sequential visual phenomena. Given examples of a phenomena that can be divided into discrete time steps, we aim to take an input from any such time and realize this input at all other time steps in the sequence. Furthermore, we aim to do this without ground-truth aligned sequences -- avoiding the difficulties needed for gathering aligned data. This generalizes the unpaired image-to-image problem from generating pairs to generating sequences. We extend cycle consistency to loop consistency and alleviate difficulties associated with learning in the resulting long chains of computation. We show competitive results compared to existing image-to-image techniques when modeling several different data sets including the Earth's seasons and aging of human faces.
Learning Instance Occlusion for Panoptic Segmentation
Jun 13, 2019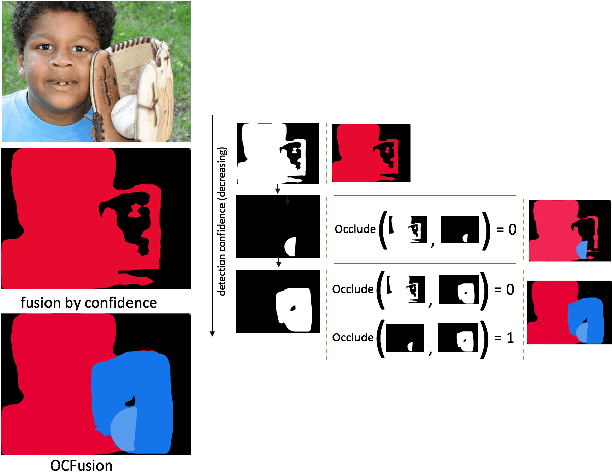
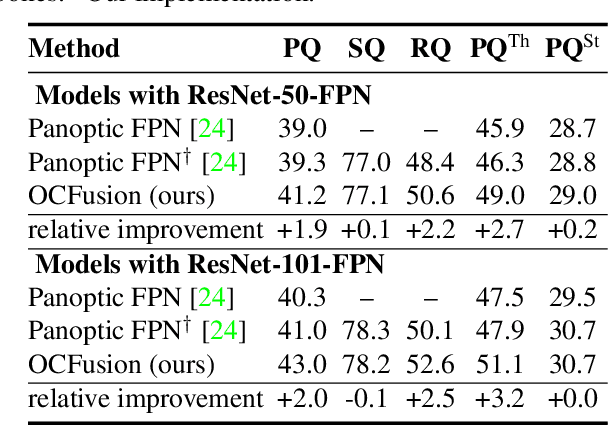

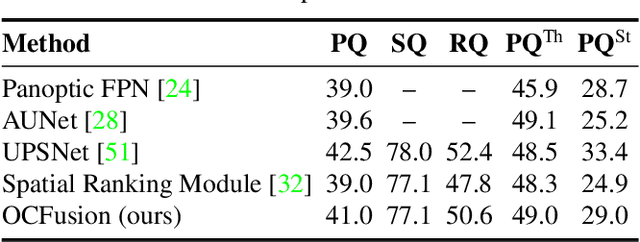
Recently, the vision community has shown renewed interest in the effort of panoptic segmentation --- previously known as image parsing. While a large amount of progress has been made within both the instance and semantic segmentation tasks separately, panoptic segmentation implies knowledge of both (countable) "things" and semantic "stuff" within a single output. A common approach involves the fusion of respective instance and semantic segmentations proposals, however, this method has not explicitly addressed the jump from instance segmentation to non-overlapping placement within a single output and often fails to layout overlapping instances adequately. We propose a straightforward extension to the Mask R-CNN framework that is tasked with resolving how two instance masks should overlap one another in the fused output as a binary relation. We show competitive increases in overall panoptic quality (PQ) and particular gains in the "things" portion of the standard panoptic segmentation benchmark, reaching state-of-the-art against methods with comparable architectures.
Introspective Classification with Convolutional Nets
Jan 05, 2018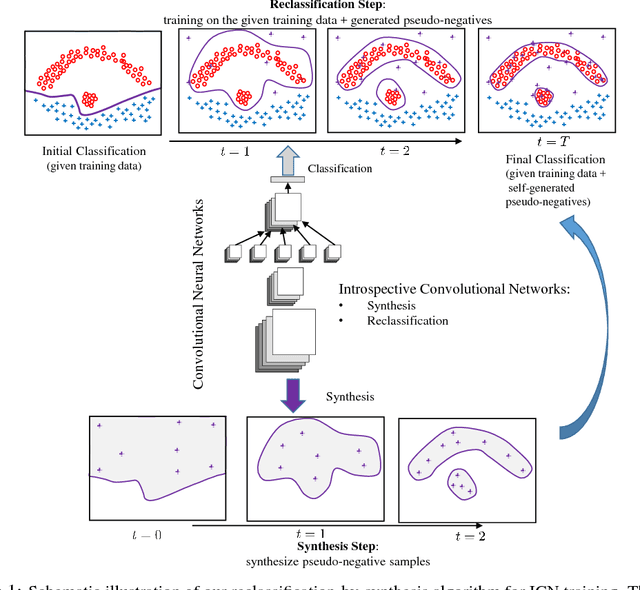
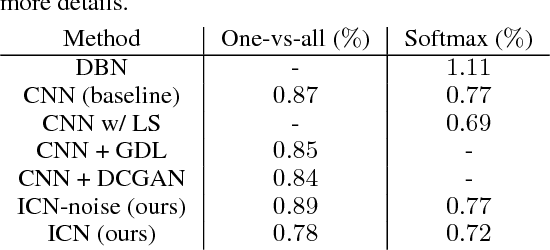

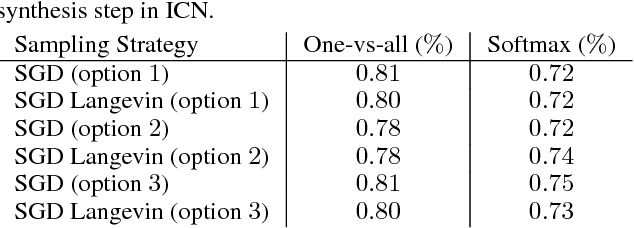
We propose introspective convolutional networks (ICN) that emphasize the importance of having convolutional neural networks empowered with generative capabilities. We employ a reclassification-by-synthesis algorithm to perform training using a formulation stemmed from the Bayes theory. Our ICN tries to iteratively: (1) synthesize pseudo-negative samples; and (2) enhance itself by improving the classification. The single CNN classifier learned is at the same time generative --- being able to directly synthesize new samples within its own discriminative model. We conduct experiments on benchmark datasets including MNIST, CIFAR-10, and SVHN using state-of-the-art CNN architectures, and observe improved classification results.
Introspective Generative Modeling: Decide Discriminatively
Apr 25, 2017

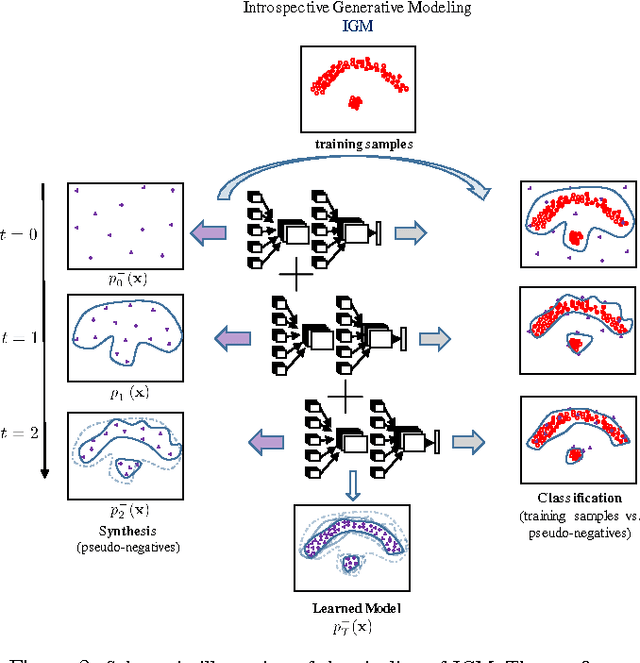

We study unsupervised learning by developing introspective generative modeling (IGM) that attains a generator using progressively learned deep convolutional neural networks. The generator is itself a discriminator, capable of introspection: being able to self-evaluate the difference between its generated samples and the given training data. When followed by repeated discriminative learning, desirable properties of modern discriminative classifiers are directly inherited by the generator. IGM learns a cascade of CNN classifiers using a synthesis-by-classification algorithm. In the experiments, we observe encouraging results on a number of applications including texture modeling, artistic style transferring, face modeling, and semi-supervised learning.