 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRooms from Motion: Un-posed Indoor 3D Object Detection as Localization and Mapping
May 29, 2025We revisit scene-level 3D object detection as the output of an object-centric framework capable of both localization and mapping using 3D oriented boxes as the underlying geometric primitive. While existing 3D object detection approaches operate globally and implicitly rely on the a priori existence of metric camera poses, our method, Rooms from Motion (RfM) operates on a collection of un-posed images. By replacing the standard 2D keypoint-based matcher of structure-from-motion with an object-centric matcher based on image-derived 3D boxes, we estimate metric camera poses, object tracks, and finally produce a global, semantic 3D object map. When a priori pose is available, we can significantly improve map quality through optimization of global 3D boxes against individual observations. RfM shows strong localization performance and subsequently produces maps of higher quality than leading point-based and multi-view 3D object detection methods on CA-1M and ScanNet++, despite these global methods relying on overparameterization through point clouds or dense volumes. Rooms from Motion achieves a general, object-centric representation which not only extends the work of Cubify Anything to full scenes but also allows for inherently sparse localization and parametric mapping proportional to the number of objects in a scene.
SlowFast-LLaVA-1.5: A Family of Token-Efficient Video Large Language Models for Long-Form Video Understanding
Mar 27, 2025We introduce SlowFast-LLaVA-1.5 (abbreviated as SF-LLaVA-1.5), a family of video large language models (LLMs) offering a token-efficient solution for long-form video understanding. We incorporate the two-stream SlowFast mechanism into a streamlined training pipeline, and perform joint video-image training on a carefully curated data mixture of only publicly available datasets. Our primary focus is on highly efficient model scales (1B and 3B), demonstrating that even relatively small Video LLMs can achieve state-of-the-art performance on video understanding, meeting the demand for mobile-friendly models. Experimental results demonstrate that SF-LLaVA-1.5 achieves superior performance on a wide range of video and image tasks, with robust results at all model sizes (ranging from 1B to 7B). Notably, SF-LLaVA-1.5 achieves state-of-the-art results in long-form video understanding (e.g., LongVideoBench and MLVU) and excels at small scales across various video benchmarks.
MM-Spatial: Exploring 3D Spatial Understanding in Multimodal LLMs
Mar 17, 2025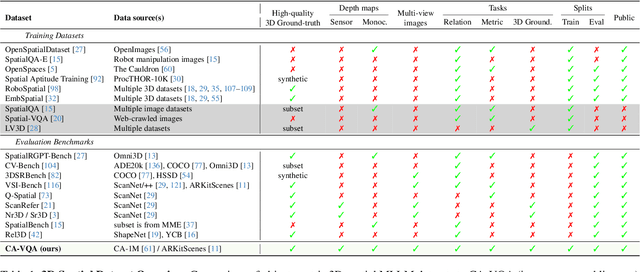

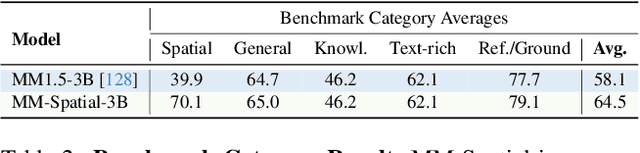

Multimodal large language models (MLLMs) excel at 2D visual understanding but remain limited in their ability to reason about 3D space. In this work, we leverage large-scale high-quality 3D scene data with open-set annotations to introduce 1) a novel supervised fine-tuning dataset and 2) a new evaluation benchmark, focused on indoor scenes. Our Cubify Anything VQA (CA-VQA) data covers diverse spatial tasks including spatial relationship prediction, metric size and distance estimation, and 3D grounding. We show that CA-VQA enables us to train MM-Spatial, a strong generalist MLLM that also achieves state-of-the-art performance on 3D spatial understanding benchmarks, including our own. We show how incorporating metric depth and multi-view inputs (provided in CA-VQA) can further improve 3D understanding, and demonstrate that data alone allows our model to achieve depth perception capabilities comparable to dedicated monocular depth estimation models. We will publish our SFT dataset and benchmark.
Using Drone Swarm to Stop Wildfire: A Predict-then-optimize Approach
Nov 25, 2024Drone swarms coupled with data intelligence can be the future of wildfire fighting. However, drone swarm firefighting faces enormous challenges, such as the highly complex environmental conditions in wildfire scenes, the highly dynamic nature of wildfire spread, and the significant computational complexity of drone swarm operations. We develop a predict-then-optimize approach to address these challenges to enable effective drone swarm firefighting. First, we construct wildfire spread prediction convex neural network (Convex-NN) models based on real wildfire data. Then, we propose a mixed-integer programming (MIP) model coupled with dynamic programming (DP) to enable efficient drone swarm task planning. We further use chance-constrained robust optimization (CCRO) to ensure robust firefighting performances under varying situations. The formulated model is solved efficiently using Benders Decomposition and Branch-and-Cut algorithms. After 75 simulated wildfire environments training, the MIP+CCRO approach shows the best performance among several testing sets, reducing movements by 37.3\% compared to the plain MIP. It also significantly outperformed the GA baseline, which often failed to fully extinguish the fire. Eventually, we will conduct real-world fire spread and quenching experiments in the next stage for further validation.
SlowFast-LLaVA: A Strong Training-Free Baseline for Video Large Language Models
Jul 22, 2024



We propose SlowFast-LLaVA (or SF-LLaVA for short), a training-free video large language model (LLM) that can jointly capture the detailed spatial semantics and long-range temporal context without exceeding the token budget of commonly used LLMs. This is realized by using a two-stream SlowFast design of inputs for Video LLMs to aggregate features from sampled video frames in an effective way. Specifically, the Slow pathway extracts features at a low frame rate while keeping as many spatial details as possible (e.g., with 24x24 tokens), and the Fast pathway operates on a high frame rate but uses a larger spatial pooling stride (e.g., downsampling 6x) to focus on the motion cues. As a result, this design allows us to adequately capture both spatial and temporal features that are beneficial for understanding details along the video. Experimental results show that SF-LLaVA outperforms existing training-free methods on a wide range of video tasks. On some benchmarks, it achieves comparable or even better performance compared to state-of-the-art Video LLMs that are fine-tuned on video datasets.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
LMDX: Language Model-based Document Information Extraction and Localization
Sep 19, 2023


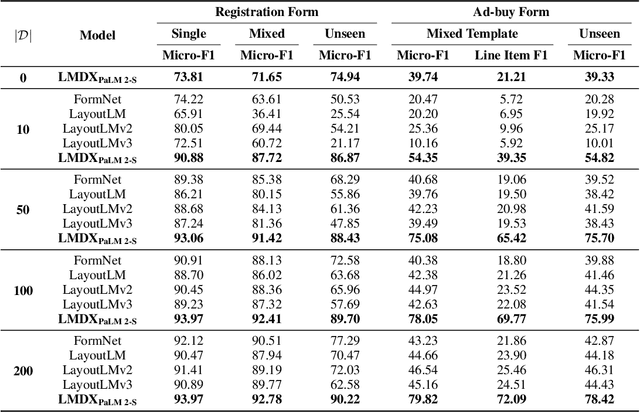
Large Language Models (LLM) have revolutionized Natural Language Processing (NLP), improving state-of-the-art on many existing tasks and exhibiting emergent capabilities. However, LLMs have not yet been successfully applied on semi-structured document information extraction, which is at the core of many document processing workflows and consists of extracting key entities from a visually rich document (VRD) given a predefined target schema. The main obstacles to LLM adoption in that task have been the absence of layout encoding within LLMs, critical for a high quality extraction, and the lack of a grounding mechanism ensuring the answer is not hallucinated. In this paper, we introduce Language Model-based Document Information Extraction and Localization (LMDX), a methodology to adapt arbitrary LLMs for document information extraction. LMDX can do extraction of singular, repeated, and hierarchical entities, both with and without training data, while providing grounding guarantees and localizing the entities within the document. In particular, we apply LMDX to the PaLM 2-S LLM and evaluate it on VRDU and CORD benchmarks, setting a new state-of-the-art and showing how LMDX enables the creation of high quality, data-efficient parsers.
One-shot Learning for Channel Estimation in Massive MIMO Systems
Jun 09, 2023



In conventional supervised deep learning based channel estimation algorithms, a large number of training samples are required for offline training. However, in practical communication systems, it is difficult to obtain channel samples for every signal-to-noise ratio (SNR). Furthermore, the generalization ability of these deep neural networks (DNN) is typically poor. In this work, we propose a one-shot self-supervised learning framework for channel estimation in multi-input multi-output (MIMO) systems. The required number of samples for offline training is small and our approach can be directly deployed to adapt to variable channels. Our framework consists of a traditional channel estimation module and a denoising module. The denoising module is designed based on the one-shot learning method Self2Self and employs Bernoulli sampling to generate training labels. Besides,we further utilize a blind spot strategy and dropout technique to avoid overfitting. Simulation results show that the performance of the proposed one-shot self-supervised learning method is very close to the supervised learning approach while obtaining improved generalization ability for different channel environments.
RoomDreamer: Text-Driven 3D Indoor Scene Synthesis with Coherent Geometry and Texture
May 18, 2023



The techniques for 3D indoor scene capturing are widely used, but the meshes produced leave much to be desired. In this paper, we propose "RoomDreamer", which leverages powerful natural language to synthesize a new room with a different style. Unlike existing image synthesis methods, our work addresses the challenge of synthesizing both geometry and texture aligned to the input scene structure and prompt simultaneously. The key insight is that a scene should be treated as a whole, taking into account both scene texture and geometry. The proposed framework consists of two significant components: Geometry Guided Diffusion and Mesh Optimization. Geometry Guided Diffusion for 3D Scene guarantees the consistency of the scene style by applying the 2D prior to the entire scene simultaneously. Mesh Optimization improves the geometry and texture jointly and eliminates the artifacts in the scanned scene. To validate the proposed method, real indoor scenes scanned with smartphones are used for extensive experiments, through which the effectiveness of our method is demonstrated.
Mixed-Timescale Deep-Unfolding for Joint Channel Estimation and Hybrid Beamforming
Jun 08, 2022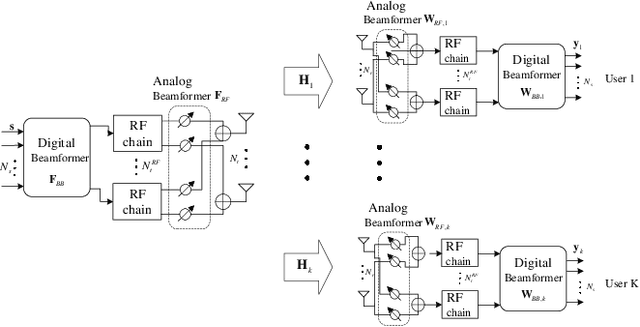
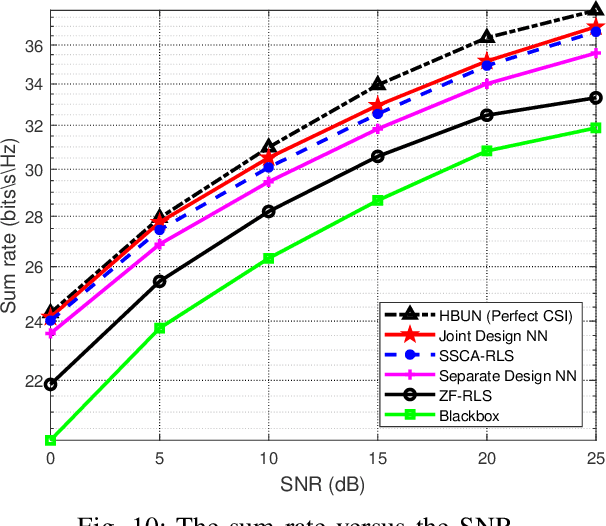
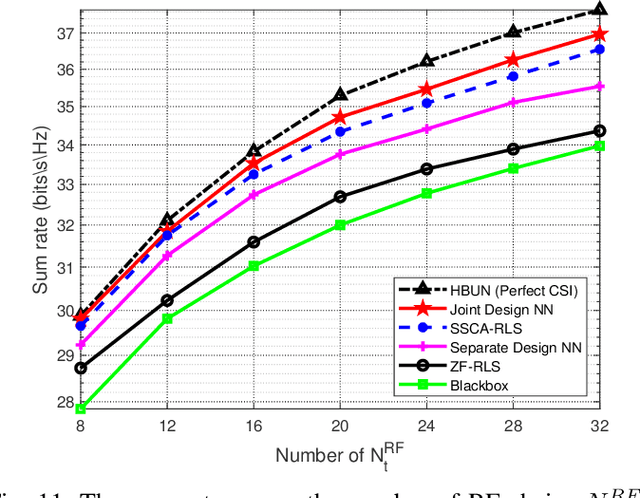
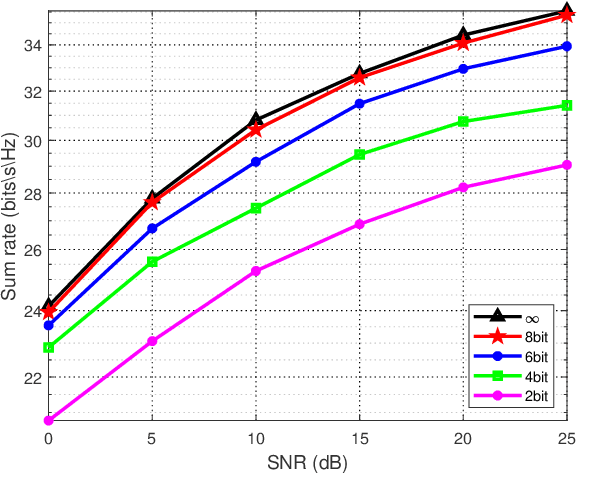
In massive multiple-input multiple-output (MIMO) systems, hybrid analog-digital beamforming is an essential technique for exploiting the potential array gain without using a dedicated radio frequency chain for each antenna. However, due to the large number of antennas, the conventional channel estimation and hybrid beamforming algorithms generally require high computational complexity and signaling overhead. In this work, we propose an end-to-end deep-unfolding neural network (NN) joint channel estimation and hybrid beamforming (JCEHB) algorithm to maximize the system sum rate in time-division duplex (TDD) massive MIMO. Specifically, the recursive least-squares (RLS) algorithm and stochastic successive convex approximation (SSCA) algorithm are unfolded for channel estimation and hybrid beamforming, respectively. In order to reduce the signaling overhead, we consider a mixed-timescale hybrid beamforming scheme, where the analog beamforming matrices are optimized based on the channel state information (CSI) statistics offline, while the digital beamforming matrices are designed at each time slot based on the estimated low-dimensional equivalent CSI matrices. We jointly train the analog beamformers together with the trainable parameters of the RLS and SSCA induced deep-unfolding NNs based on the CSI statistics offline. During data transmission, we estimate the low-dimensional equivalent CSI by the RLS induced deep-unfolding NN and update the digital beamformers. In addition, we propose a mixed-timescale deep-unfolding NN where the analog beamformers are optimized online, and extend the framework to frequency-division duplex (FDD) systems where channel feedback is considered. Simulation results show that the proposed algorithm can significantly outperform conventional algorithms with reduced computational complexity and signaling overhead.