 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking Down Video LLM Benchmarks: Knowledge, Spatial Perception, or True Temporal Understanding?
May 20, 2025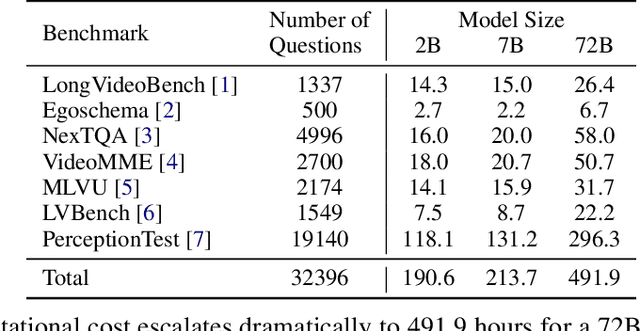

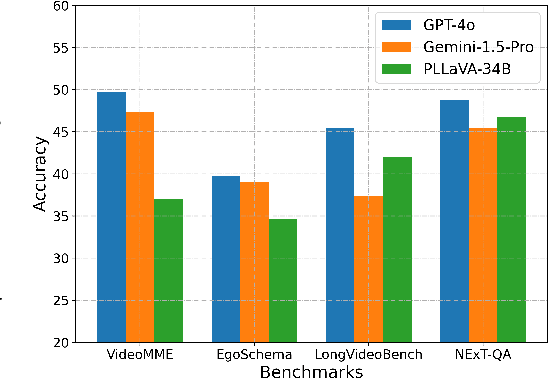
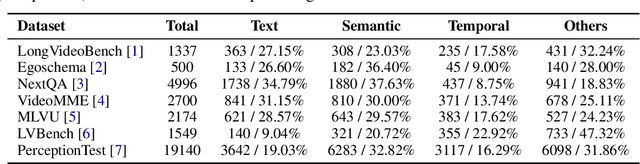
Existing video understanding benchmarks often conflate knowledge-based and purely image-based questions, rather than clearly isolating a model's temporal reasoning ability, which is the key aspect that distinguishes video understanding from other modalities. We identify two major limitations that obscure whether higher scores truly indicate stronger understanding of the dynamic content in videos: (1) strong language priors, where models can answer questions without watching the video; and (2) shuffling invariance, where models maintain similar performance on certain questions even when video frames are temporally shuffled. To alleviate these issues, we propose VBenchComp, an automated pipeline that categorizes questions into different domains: LLM-Answerable, Semantic, and Temporal. Specifically, LLM-Answerable questions can be answered without viewing the video; Semantic questions remain answerable even when the video frames are shuffled; and Temporal questions require understanding the correct temporal order of frames. The rest of the questions are labeled as Others. This can enable fine-grained evaluation of different capabilities of a video LLM. Our analysis reveals nuanced model weaknesses that are hidden by traditional overall scores, and we offer insights and recommendations for designing future benchmarks that more accurately assess video LLMs.
StreamBridge: Turning Your Offline Video Large Language Model into a Proactive Streaming Assistant
May 08, 2025We present StreamBridge, a simple yet effective framework that seamlessly transforms offline Video-LLMs into streaming-capable models. It addresses two fundamental challenges in adapting existing models into online scenarios: (1) limited capability for multi-turn real-time understanding, and (2) lack of proactive response mechanisms. Specifically, StreamBridge incorporates (1) a memory buffer combined with a round-decayed compression strategy, supporting long-context multi-turn interactions, and (2) a decoupled, lightweight activation model that can be effortlessly integrated into existing Video-LLMs, enabling continuous proactive responses. To further support StreamBridge, we construct Stream-IT, a large-scale dataset tailored for streaming video understanding, featuring interleaved video-text sequences and diverse instruction formats. Extensive experiments show that StreamBridge significantly improves the streaming understanding capabilities of offline Video-LLMs across various tasks, outperforming even proprietary models such as GPT-4o and Gemini 1.5 Pro. Simultaneously, it achieves competitive or superior performance on standard video understanding benchmarks.
SlowFast-LLaVA-1.5: A Family of Token-Efficient Video Large Language Models for Long-Form Video Understanding
Mar 27, 2025We introduce SlowFast-LLaVA-1.5 (abbreviated as SF-LLaVA-1.5), a family of video large language models (LLMs) offering a token-efficient solution for long-form video understanding. We incorporate the two-stream SlowFast mechanism into a streamlined training pipeline, and perform joint video-image training on a carefully curated data mixture of only publicly available datasets. Our primary focus is on highly efficient model scales (1B and 3B), demonstrating that even relatively small Video LLMs can achieve state-of-the-art performance on video understanding, meeting the demand for mobile-friendly models. Experimental results demonstrate that SF-LLaVA-1.5 achieves superior performance on a wide range of video and image tasks, with robust results at all model sizes (ranging from 1B to 7B). Notably, SF-LLaVA-1.5 achieves state-of-the-art results in long-form video understanding (e.g., LongVideoBench and MLVU) and excels at small scales across various video benchmarks.
STIV: Scalable Text and Image Conditioned Video Generation
Dec 10, 2024The field of video generation has made remarkable advancements, yet there remains a pressing need for a clear, systematic recipe that can guide the development of robust and scalable models. In this work, we present a comprehensive study that systematically explores the interplay of model architectures, training recipes, and data curation strategies, culminating in a simple and scalable text-image-conditioned video generation method, named STIV. Our framework integrates image condition into a Diffusion Transformer (DiT) through frame replacement, while incorporating text conditioning via a joint image-text conditional classifier-free guidance. This design enables STIV to perform both text-to-video (T2V) and text-image-to-video (TI2V) tasks simultaneously. Additionally, STIV can be easily extended to various applications, such as video prediction, frame interpolation, multi-view generation, and long video generation, etc. With comprehensive ablation studies on T2I, T2V, and TI2V, STIV demonstrate strong performance, despite its simple design. An 8.7B model with 512 resolution achieves 83.1 on VBench T2V, surpassing both leading open and closed-source models like CogVideoX-5B, Pika, Kling, and Gen-3. The same-sized model also achieves a state-of-the-art result of 90.1 on VBench I2V task at 512 resolution. By providing a transparent and extensible recipe for building cutting-edge video generation models, we aim to empower future research and accelerate progress toward more versatile and reliable video generation solutions.
Revisit Large-Scale Image-Caption Data in Pre-training Multimodal Foundation Models
Oct 03, 2024Recent advancements in multimodal models highlight the value of rewritten captions for improving performance, yet key challenges remain. For example, while synthetic captions often provide superior quality and image-text alignment, it is not clear whether they can fully replace AltTexts: the role of synthetic captions and their interaction with original web-crawled AltTexts in pre-training is still not well understood. Moreover, different multimodal foundation models may have unique preferences for specific caption formats, but efforts to identify the optimal captions for each model remain limited. In this work, we propose a novel, controllable, and scalable captioning pipeline designed to generate diverse caption formats tailored to various multimodal models. By examining Short Synthetic Captions (SSC) towards Dense Synthetic Captions (DSC+) as case studies, we systematically explore their effects and interactions with AltTexts across models such as CLIP, multimodal LLMs, and diffusion models. Our findings reveal that a hybrid approach that keeps both synthetic captions and AltTexts can outperform the use of synthetic captions alone, improving both alignment and performance, with each model demonstrating preferences for particular caption formats. This comprehensive analysis provides valuable insights into optimizing captioning strategies, thereby advancing the pre-training of multimodal foundation models.
Contrastive Localized Language-Image Pre-Training
Oct 03, 2024



Contrastive Language-Image Pre-training (CLIP) has been a celebrated method for training vision encoders to generate image/text representations facilitating various applications. Recently, CLIP has been widely adopted as the vision backbone of multimodal large language models (MLLMs) to connect image inputs for language interactions. The success of CLIP as a vision-language foundation model relies on aligning web-crawled noisy text annotations at image levels. Nevertheless, such criteria may become insufficient for downstream tasks in need of fine-grained vision representations, especially when region-level understanding is demanding for MLLMs. In this paper, we improve the localization capability of CLIP with several advances. We propose a pre-training method called Contrastive Localized Language-Image Pre-training (CLOC) by complementing CLIP with region-text contrastive loss and modules. We formulate a new concept, promptable embeddings, of which the encoder produces image embeddings easy to transform into region representations given spatial hints. To support large-scale pre-training, we design a visually-enriched and spatially-localized captioning framework to effectively generate region-text pseudo-labels at scale. By scaling up to billions of annotated images, CLOC enables high-quality regional embeddings for image region recognition and retrieval tasks, and can be a drop-in replacement of CLIP to enhance MLLMs, especially on referring and grounding tasks.
MM1.5: Methods, Analysis & Insights from Multimodal LLM Fine-tuning
Sep 30, 2024
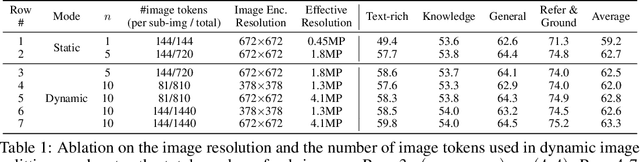

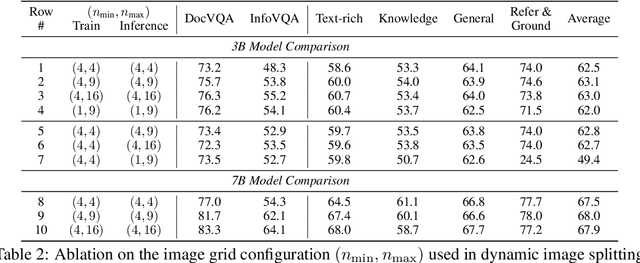
We present MM1.5, a new family of multimodal large language models (MLLMs) designed to enhance capabilities in text-rich image understanding, visual referring and grounding, and multi-image reasoning. Building upon the MM1 architecture, MM1.5 adopts a data-centric approach to model training, systematically exploring the impact of diverse data mixtures across the entire model training lifecycle. This includes high-quality OCR data and synthetic captions for continual pre-training, as well as an optimized visual instruction-tuning data mixture for supervised fine-tuning. Our models range from 1B to 30B parameters, encompassing both dense and mixture-of-experts (MoE) variants, and demonstrate that careful data curation and training strategies can yield strong performance even at small scales (1B and 3B). Additionally, we introduce two specialized variants: MM1.5-Video, designed for video understanding, and MM1.5-UI, tailored for mobile UI understanding. Through extensive empirical studies and ablations, we provide detailed insights into the training processes and decisions that inform our final designs, offering valuable guidance for future research in MLLM development.
SlowFast-LLaVA: A Strong Training-Free Baseline for Video Large Language Models
Jul 22, 2024



We propose SlowFast-LLaVA (or SF-LLaVA for short), a training-free video large language model (LLM) that can jointly capture the detailed spatial semantics and long-range temporal context without exceeding the token budget of commonly used LLMs. This is realized by using a two-stream SlowFast design of inputs for Video LLMs to aggregate features from sampled video frames in an effective way. Specifically, the Slow pathway extracts features at a low frame rate while keeping as many spatial details as possible (e.g., with 24x24 tokens), and the Fast pathway operates on a high frame rate but uses a larger spatial pooling stride (e.g., downsampling 6x) to focus on the motion cues. As a result, this design allows us to adequately capture both spatial and temporal features that are beneficial for understanding details along the video. Experimental results show that SF-LLaVA outperforms existing training-free methods on a wide range of video tasks. On some benchmarks, it achieves comparable or even better performance compared to state-of-the-art Video LLMs that are fine-tuned on video datasets.
Empowering Source-Free Domain Adaptation with MLLM-driven Curriculum Learning
May 28, 2024Source-Free Domain Adaptation (SFDA) aims to adapt a pre-trained source model to a target domain using only unlabeled target data. Current SFDA methods face challenges in effectively leveraging pre-trained knowledge and exploiting target domain data. Multimodal Large Language Models (MLLMs) offer remarkable capabilities in understanding visual and textual information, but their applicability to SFDA poses challenges such as instruction-following failures, intensive computational demands, and difficulties in performance measurement prior to adaptation. To alleviate these issues, we propose Reliability-based Curriculum Learning (RCL), a novel framework that integrates multiple MLLMs for knowledge exploitation via pseudo-labeling in SFDA. Our framework incorporates proposed Reliable Knowledge Transfer, Self-correcting and MLLM-guided Knowledge Expansion, and Multi-hot Masking Refinement to progressively exploit unlabeled data in the target domain. RCL achieves state-of-the-art (SOTA) performance on multiple SFDA benchmarks, e.g., $\textbf{+9.4%}$ on DomainNet, demonstrating its effectiveness in enhancing adaptability and robustness without requiring access to source data. Code: https://github.com/Dong-Jie-Chen/RCL.
MobilityGPT: Enhanced Human Mobility Modeling with a GPT model
Feb 05, 2024



Generative models have shown promising results in capturing human mobility characteristics and generating synthetic trajectories. However, it remains challenging to ensure that the generated geospatial mobility data is semantically realistic, including consistent location sequences, and reflects real-world characteristics, such as constraining on geospatial limits. To address these issues, we reformat human mobility modeling as an autoregressive generation task, leveraging Generative Pre-trained Transformer (GPT). To ensure its controllable generation to alleviate the above challenges, we propose a geospatially-aware generative model, MobilityGPT. We propose a gravity-based sampling method to train a transformer for semantic sequence similarity. Then, we constrained the training process via a road connectivity matrix that provides the connectivity of sequences in trajectory generation, thereby keeping generated trajectories in geospatial limits. Lastly, we constructed a Reinforcement Learning from Trajectory Feedback (RLTF) to minimize the travel distance between training and the synthetically generated trajectories. Our experiments on real-world datasets demonstrate that MobilityGPT outperforms state-of-the-art methods in generating high-quality mobility trajectories that are closest to real data in terms of origin-destination similarity, trip length, travel radius, link, and gravity distributions.