 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Multimodal LLMs to Generalist Embodied Agents: Methods and Lessons
Dec 11, 2024We examine the capability of Multimodal Large Language Models (MLLMs) to tackle diverse domains that extend beyond the traditional language and vision tasks these models are typically trained on. Specifically, our focus lies in areas such as Embodied AI, Games, UI Control, and Planning. To this end, we introduce a process of adapting an MLLM to a Generalist Embodied Agent (GEA). GEA is a single unified model capable of grounding itself across these varied domains through a multi-embodiment action tokenizer. GEA is trained with supervised learning on a large dataset of embodied experiences and with online RL in interactive simulators. We explore the data and algorithmic choices necessary to develop such a model. Our findings reveal the importance of training with cross-domain data and online RL for building generalist agents. The final GEA model achieves strong generalization performance to unseen tasks across diverse benchmarks compared to other generalist models and benchmark-specific approaches.
MM1.5: Methods, Analysis & Insights from Multimodal LLM Fine-tuning
Sep 30, 2024
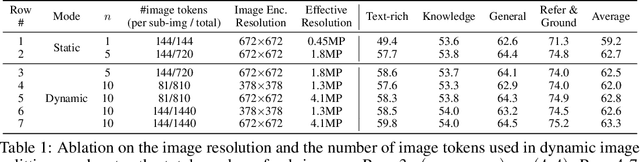

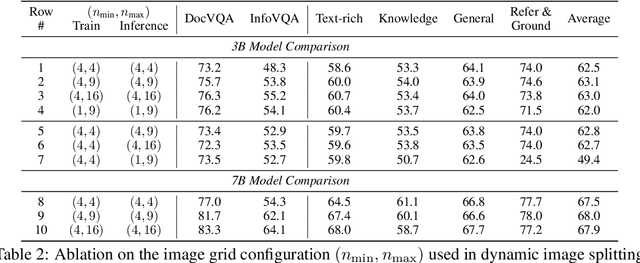
We present MM1.5, a new family of multimodal large language models (MLLMs) designed to enhance capabilities in text-rich image understanding, visual referring and grounding, and multi-image reasoning. Building upon the MM1 architecture, MM1.5 adopts a data-centric approach to model training, systematically exploring the impact of diverse data mixtures across the entire model training lifecycle. This includes high-quality OCR data and synthetic captions for continual pre-training, as well as an optimized visual instruction-tuning data mixture for supervised fine-tuning. Our models range from 1B to 30B parameters, encompassing both dense and mixture-of-experts (MoE) variants, and demonstrate that careful data curation and training strategies can yield strong performance even at small scales (1B and 3B). Additionally, we introduce two specialized variants: MM1.5-Video, designed for video understanding, and MM1.5-UI, tailored for mobile UI understanding. Through extensive empirical studies and ablations, we provide detailed insights into the training processes and decisions that inform our final designs, offering valuable guidance for future research in MLLM development.
From Scarcity to Efficiency: Improving CLIP Training via Visual-enriched Captions
Oct 11, 2023Web-crawled datasets are pivotal to the success of pre-training vision-language models, exemplified by CLIP. However, web-crawled AltTexts can be noisy and potentially irrelevant to images, thereby undermining the crucial image-text alignment. Existing methods for rewriting captions using large language models (LLMs) have shown promise on small, curated datasets like CC3M and CC12M. Nevertheless, their efficacy on massive web-captured captions is constrained by the inherent noise and randomness in such data. In this study, we address this limitation by focusing on two key aspects: data quality and data variety. Unlike recent LLM rewriting techniques, we emphasize exploiting visual concepts and their integration into the captions to improve data quality. For data variety, we propose a novel mixed training scheme that optimally leverages AltTexts alongside newly generated Visual-enriched Captions (VeC). We use CLIP as one example and adapt the method for CLIP training on large-scale web-crawled datasets, named VeCLIP. We conduct a comprehensive evaluation of VeCLIP across small, medium, and large scales of raw data. Our results show significant advantages in image-text alignment and overall model performance, underscoring the effectiveness of VeCLIP in improving CLIP training. For example, VeCLIP achieves a remarkable over 20% improvement in COCO and Flickr30k retrieval tasks under the 12M setting. For data efficiency, we also achieve a notable over 3% improvement while using only 14% of the data employed in the vanilla CLIP and 11% in ALIGN.
MOFI: Learning Image Representations from Noisy Entity Annotated Images
Jun 24, 2023We present MOFI, a new vision foundation model designed to learn image representations from noisy entity annotated images. MOFI differs from previous work in two key aspects: ($i$) pre-training data, and ($ii$) training recipe. Regarding data, we introduce a new approach to automatically assign entity labels to images from noisy image-text pairs. Our approach involves employing a named entity recognition model to extract entities from the alt-text, and then using a CLIP model to select the correct entities as labels of the paired image. The approach is simple, does not require costly human annotation, and can be readily scaled up to billions of image-text pairs mined from the web. Through this method, we have created Image-to-Entities (I2E), a new large-scale dataset with 1 billion images and 2 million distinct entities, covering rich visual concepts in the wild. Building upon the I2E dataset, we study different training recipes, including supervised pre-training, contrastive pre-training, and multi-task learning. For constrastive pre-training, we treat entity names as free-form text, and further enrich them with entity descriptions. Experiments show that supervised pre-training with large-scale fine-grained entity labels is highly effective for image retrieval tasks, and multi-task training further improves the performance. The final MOFI model achieves 86.66% mAP on the challenging GPR1200 dataset, surpassing the previous state-of-the-art performance of 72.19% from OpenAI's CLIP model. Further experiments on zero-shot and linear probe image classification also show that MOFI outperforms a CLIP model trained on the original image-text data, demonstrating the effectiveness of the I2E dataset in learning strong image representations.
Scalability in Perception for Autonomous Driving: Waymo Open Dataset
Dec 18, 2019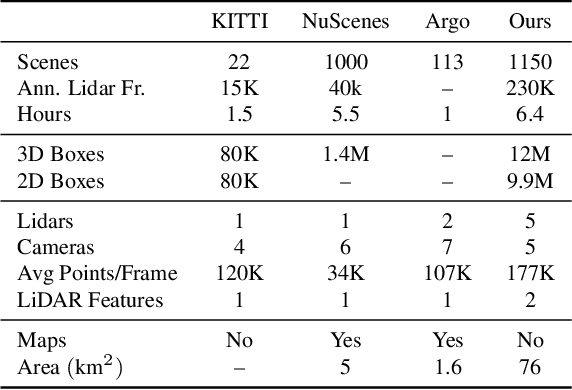



The research community has increasing interest in autonomous driving research, despite the resource intensity of obtaining representative real world data. Existing self-driving datasets are limited in the scale and variation of the environments they capture, even though generalization within and between operating regions is crucial to the overall viability of the technology. In an effort to help align the research community's contributions with real-world self-driving problems, we introduce a new large scale, high quality, diverse dataset. Our new dataset consists of 1150 scenes that each span 20 seconds, consisting of well synchronized and calibrated high quality LiDAR and camera data captured across a range of urban and suburban geographies. It is 15x more diverse than the largest camera+LiDAR dataset available based on our proposed diversity metric. We exhaustively annotated this data with 2D (camera image) and 3D (LiDAR) bounding boxes, with consistent identifiers across frames. Finally, we provide strong baselines for 2D as well as 3D detection and tracking tasks. We further study the effects of dataset size and generalization across geographies on 3D detection methods. Find data, code and more up-to-date information at http://www.waymo.com/open.
Graph-RISE: Graph-Regularized Image Semantic Embedding
Feb 14, 2019
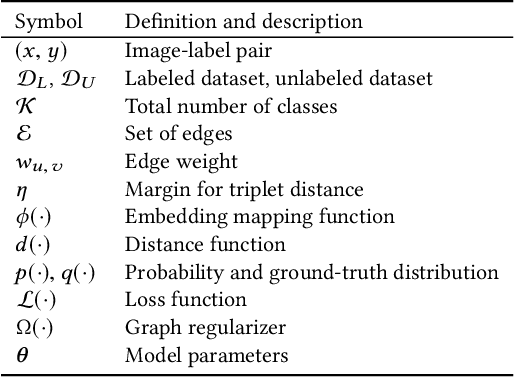

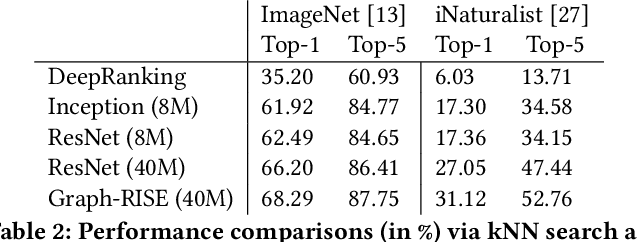
Learning image representations to capture fine-grained semantics has been a challenging and important task enabling many applications such as image search and clustering. In this paper, we present Graph-Regularized Image Semantic Embedding (Graph-RISE), a large-scale neural graph learning framework that allows us to train embeddings to discriminate an unprecedented O(40M) ultra-fine-grained semantic labels. Graph-RISE outperforms state-of-the-art image embedding algorithms on several evaluation tasks, including image classification and triplet ranking. We provide case studies to demonstrate that, qualitatively, image retrieval based on Graph-RISE effectively captures semantics and, compared to the state-of-the-art, differentiates nuances at levels that are closer to human-perception.
Detecting Cancer Metastases on Gigapixel Pathology Images
Mar 08, 2017

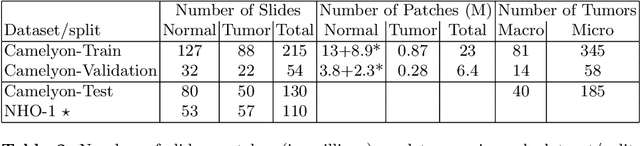
Each year, the treatment decisions for more than 230,000 breast cancer patients in the U.S. hinge on whether the cancer has metastasized away from the breast. Metastasis detection is currently performed by pathologists reviewing large expanses of biological tissues. This process is labor intensive and error-prone. We present a framework to automatically detect and localize tumors as small as 100 x 100 pixels in gigapixel microscopy images sized 100,000 x 100,000 pixels. Our method leverages a convolutional neural network (CNN) architecture and obtains state-of-the-art results on the Camelyon16 dataset in the challenging lesion-level tumor detection task. At 8 false positives per image, we detect 92.4% of the tumors, relative to 82.7% by the previous best automated approach. For comparison, a human pathologist attempting exhaustive search achieved 73.2% sensitivity. We achieve image-level AUC scores above 97% on both the Camelyon16 test set and an independent set of 110 slides. In addition, we discover that two slides in the Camelyon16 training set were erroneously labeled normal. Our approach could considerably reduce false negative rates in metastasis detection.