 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Multinomial Logits in $O(n \log n)$ time
Jan 07, 2026A Multinomial Logit (MNL) model is composed of a finite universe of items $[n]=\{1,..., n\}$, each assigned a positive weight. A query specifies an admissible subset -- called a slate -- and the model chooses one item from that slate with probability proportional to its weight. This query model is also known as the Plackett-Luce model or conditional sampling oracle in the literature. Although MNLs have been studied extensively, a basic computational question remains open: given query access to slates, how efficiently can we learn weights so that, for every slate, the induced choice distribution is within total variation distance $\varepsilon$ of the ground truth? This question is central to MNL learning and has direct implications for modern recommender system interfaces. We provide two algorithms for this task, one with adaptive queries and one with non-adaptive queries. Each algorithm outputs an MNL $M'$ that induces, for each slate $S$, a distribution $M'_S$ on $S$ that is within $\varepsilon$ total variation distance of the true distribution. Our adaptive algorithm makes $O\left(\frac{n}{\varepsilon^{3}}\log n\right)$ queries, while our non-adaptive algorithm makes $O\left(\frac{n^{2}}{\varepsilon^{3}}\log n \log\frac{n}{\varepsilon}\right)$ queries. Both algorithms query only slates of size two and run in time proportional to their query complexity. We complement these upper bounds with lower bounds of $Ω\left(\frac{n}{\varepsilon^{2}}\log n\right)$ for adaptive queries and $Ω\left(\frac{n^{2}}{\varepsilon^{2}}\log n\right)$ for non-adaptive queries, thus proving that our adaptive algorithm is optimal in its dependence on the support size $n$, while the non-adaptive one is tight within a $\log n$ factor.
Substance or Style: What Does Your Image Embedding Know?
Jul 10, 2023Probes are small networks that predict properties of underlying data from embeddings, and they provide a targeted, effective way to illuminate the information contained in embeddings. While analysis through the use of probes has become standard in NLP, there has been much less exploration in vision. Image foundation models have primarily been evaluated for semantic content. Better understanding the non-semantic information in popular embeddings (e.g., MAE, SimCLR, or CLIP) will shed new light both on the training algorithms and on the uses for these foundation models. We design a systematic transformation prediction task and measure the visual content of embeddings along many axes, including image style, quality, and a range of natural and artificial transformations. Surprisingly, six embeddings (including SimCLR) encode enough non-semantic information to identify dozens of transformations. We also consider a generalization task, where we group similar transformations and hold out several for testing. We find that image-text models (CLIP and ALIGN) are better at recognizing new examples of style transfer than masking-based models (CAN and MAE). Overall, our results suggest that the choice of pre-training algorithm impacts the types of information in the embedding, and certain models are better than others for non-semantic downstream tasks.
Approximating a RUM from Distributions on k-Slates
May 22, 2023


In this work we consider the problem of fitting Random Utility Models (RUMs) to user choices. Given the winner distributions of the subsets of size $k$ of a universe, we obtain a polynomial-time algorithm that finds the RUM that best approximates the given distribution on average. Our algorithm is based on a linear program that we solve using the ellipsoid method. Given that its corresponding separation oracle problem is NP-hard, we devise an approximate separation oracle that can be viewed as a generalization of the weighted feedback arc set problem to hypergraphs. Our theoretical result can also be made practical: we obtain a heuristic that is effective and scales to real-world datasets.
CARLS: Cross-platform Asynchronous Representation Learning System
May 26, 2021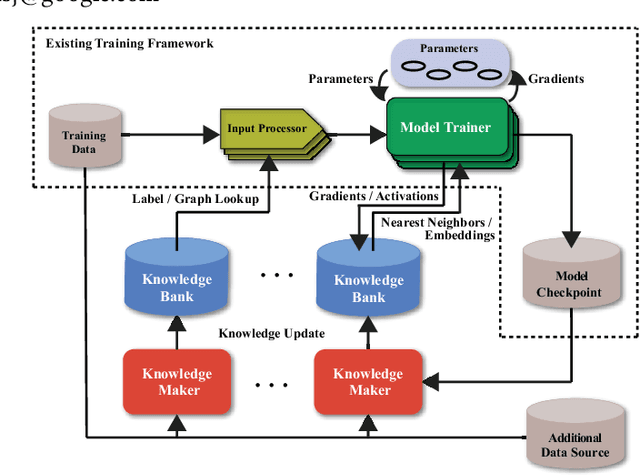
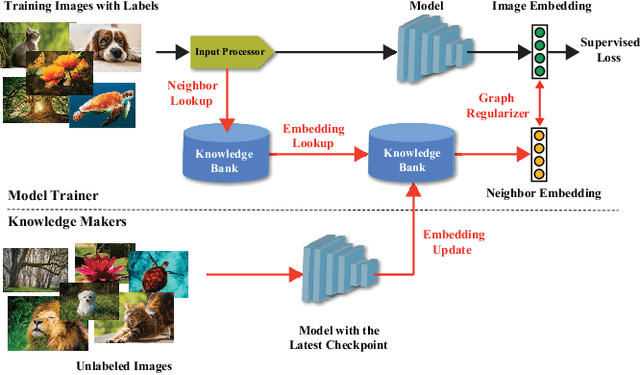
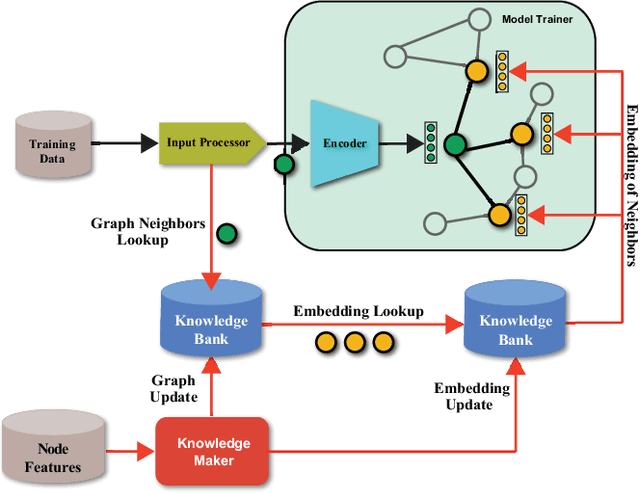
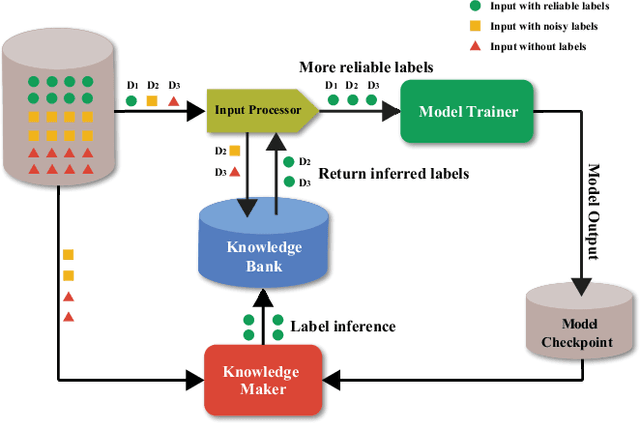
In this work, we propose CARLS, a novel framework for augmenting the capacity of existing deep learning frameworks by enabling multiple components -- model trainers, knowledge makers and knowledge banks -- to concertedly work together in an asynchronous fashion across hardware platforms. The proposed CARLS is particularly suitable for learning paradigms where model training benefits from additional knowledge inferred or discovered during training, such as node embeddings for graph neural networks or reliable pseudo labels from model predictions. We also describe three learning paradigms -- semi-supervised learning, curriculum learning and multimodal learning -- as examples that can be scaled up efficiently by CARLS. One version of CARLS has been open-sourced and available for download at: https://github.com/tensorflow/neural-structured-learning/tree/master/research/carls
Graph Autoencoders with Deconvolutional Networks
Dec 22, 2020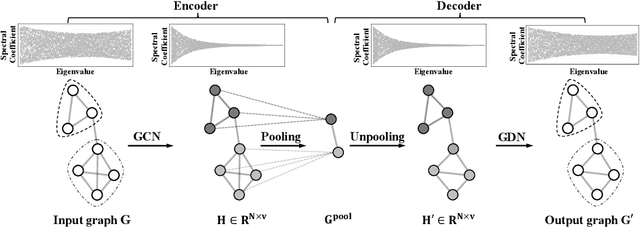
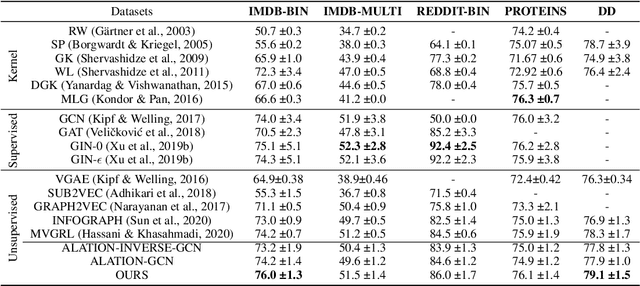
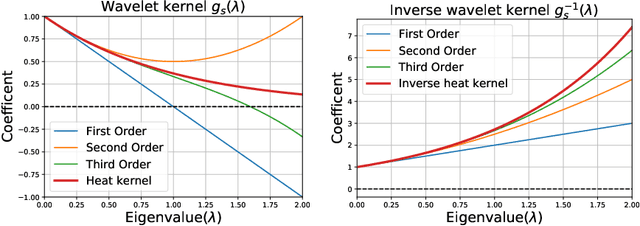
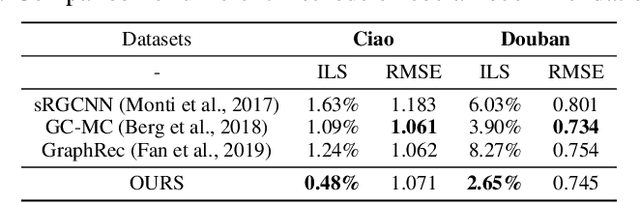
Recent studies have indicated that Graph Convolutional Networks (GCNs) act as a \emph{low pass} filter in spectral domain and encode smoothed node representations. In this paper, we consider their opposite, namely Graph Deconvolutional Networks (GDNs) that reconstruct graph signals from smoothed node representations. We motivate the design of Graph Deconvolutional Networks via a combination of inverse filters in spectral domain and de-noising layers in wavelet domain, as the inverse operation results in a \emph{high pass} filter and may amplify the noise. Based on the proposed GDN, we further propose a graph autoencoder framework that first encodes smoothed graph representations with GCN and then decodes accurate graph signals with GDN. We demonstrate the effectiveness of the proposed method on several tasks including unsupervised graph-level representation , social recommendation and graph generation
Adversarial Robustness Across Representation Spaces
Dec 01, 2020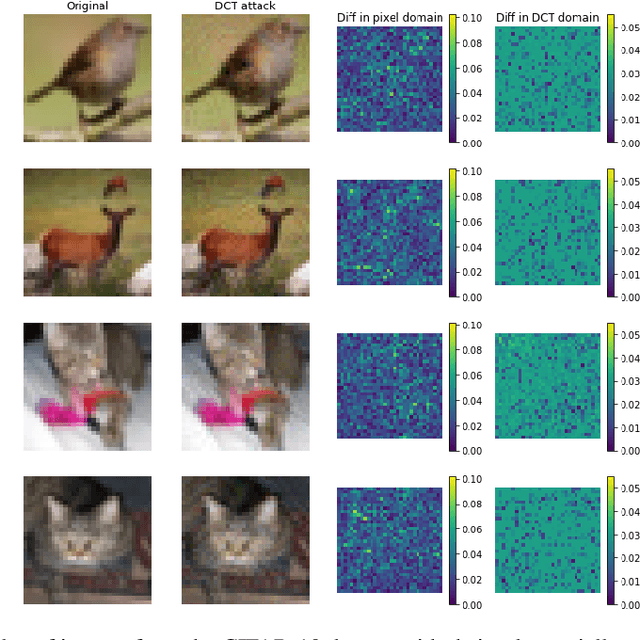
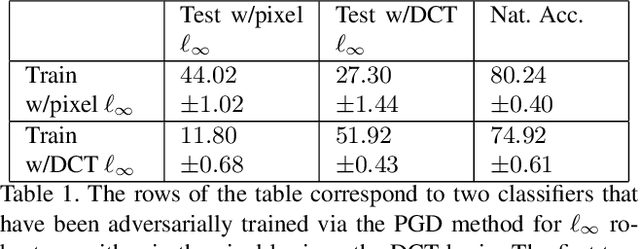

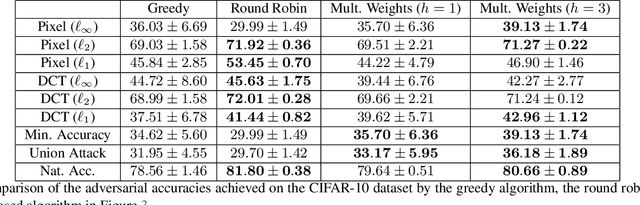
Adversarial robustness corresponds to the susceptibility of deep neural networks to imperceptible perturbations made at test time. In the context of image tasks, many algorithms have been proposed to make neural networks robust to adversarial perturbations made to the input pixels. These perturbations are typically measured in an $\ell_p$ norm. However, robustness often holds only for the specific attack used for training. In this work we extend the above setting to consider the problem of training of deep neural networks that can be made simultaneously robust to perturbations applied in multiple natural representation spaces. For the case of image data, examples include the standard pixel representation as well as the representation in the discrete cosine transform~(DCT) basis. We design a theoretically sound algorithm with formal guarantees for the above problem. Furthermore, our guarantees also hold when the goal is to require robustness with respect to multiple $\ell_p$ norm based attacks. We then derive an efficient practical implementation and demonstrate the effectiveness of our approach on standard datasets for image classification.
Surprise: Result List Truncation via Extreme Value Theory
Oct 19, 2020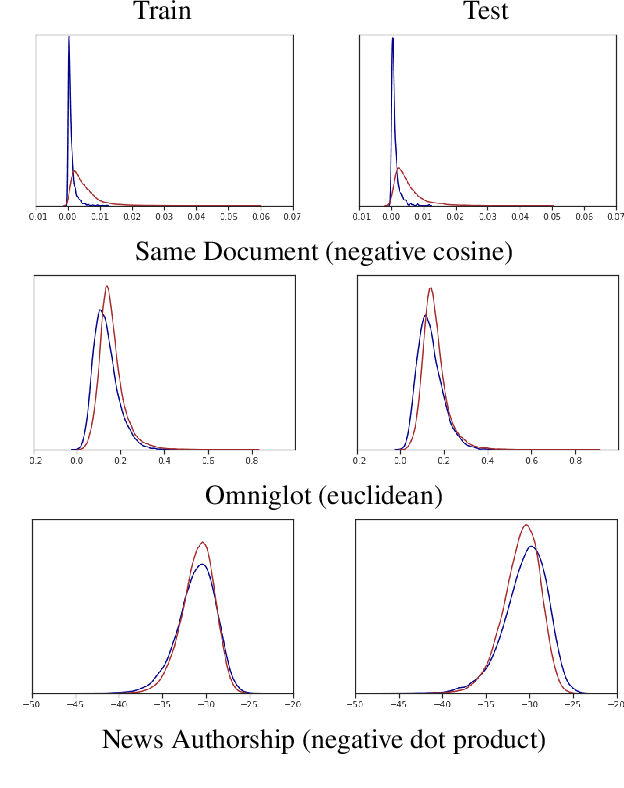
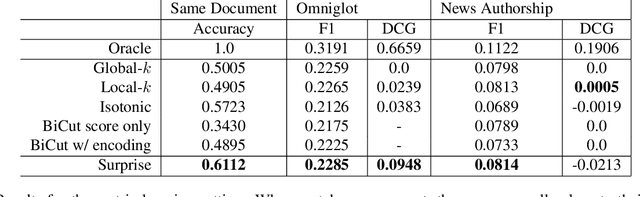
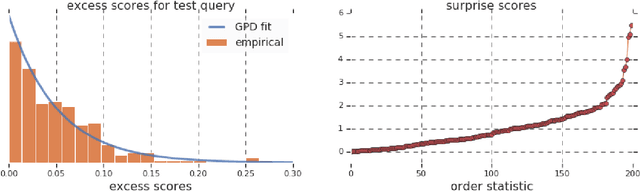
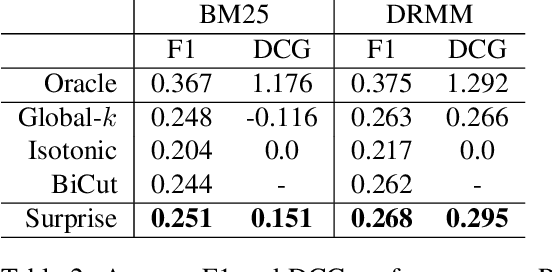
Work in information retrieval has largely been centered around ranking and relevance: given a query, return some number of results ordered by relevance to the user. The problem of result list truncation, or where to truncate the ranked list of results, however, has received less attention despite being crucial in a variety of applications. Such truncation is a balancing act between the overall relevance, or usefulness of the results, with the user cost of processing more results. Result list truncation can be challenging because relevance scores are often not well-calibrated. This is particularly true in large-scale IR systems where documents and queries are embedded in the same metric space and a query's nearest document neighbors are returned during inference. Here, relevance is inversely proportional to the distance between the query and candidate document, but what distance constitutes relevance varies from query to query and changes dynamically as more documents are added to the index. In this work, we propose Surprise scoring, a statistical method that leverages the Generalized Pareto distribution that arises in extreme value theory to produce interpretable and calibrated relevance scores at query time using nothing more than the ranked scores. We demonstrate its effectiveness on the result list truncation task across image, text, and IR datasets and compare it to both classical and recent baselines. We draw connections to hypothesis testing and $p$-values.
Generative Models are Unsupervised Predictors of Page Quality: A Colossal-Scale Study
Aug 17, 2020
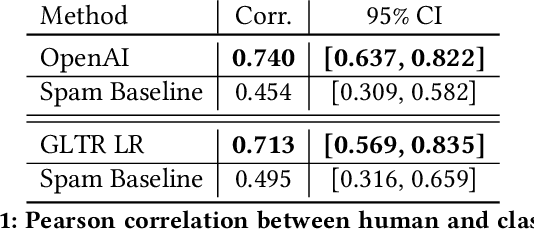
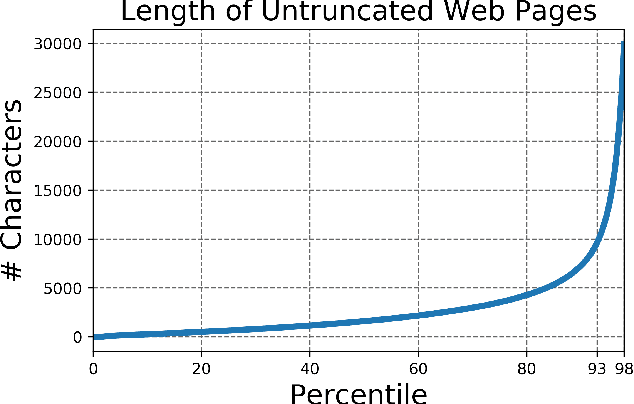

Large generative language models such as GPT-2 are well-known for their ability to generate text as well as their utility in supervised downstream tasks via fine-tuning. Our work is twofold: firstly we demonstrate via human evaluation that classifiers trained to discriminate between human and machine-generated text emerge as unsupervised predictors of "page quality", able to detect low quality content without any training. This enables fast bootstrapping of quality indicators in a low-resource setting. Secondly, curious to understand the prevalence and nature of low quality pages in the wild, we conduct extensive qualitative and quantitative analysis over 500 million web articles, making this the largest-scale study ever conducted on the topic.
BusTr: Predicting Bus Travel Times from Real-Time Traffic
Jul 02, 2020
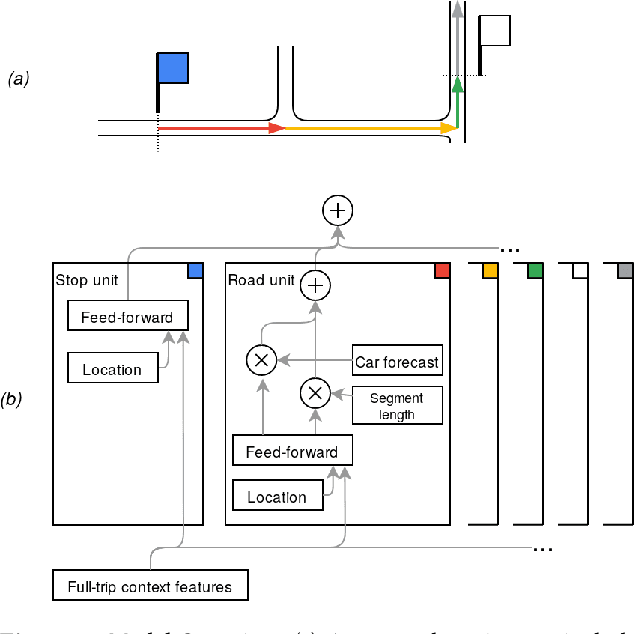

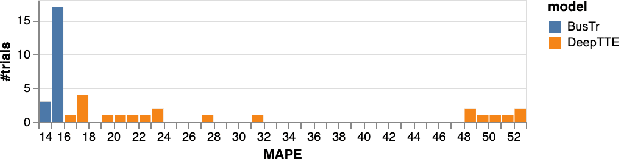
We present BusTr, a machine-learned model for translating road traffic forecasts into predictions of bus delays, used by Google Maps to serve the majority of the world's public transit systems where no official real-time bus tracking is provided. We demonstrate that our neural sequence model improves over DeepTTE, the state-of-the-art baseline, both in performance (-30% MAPE) and training stability. We also demonstrate significant generalization gains over simpler models, evaluated on longitudinal data to cope with a constantly evolving world.
Choppy: Cut Transformer For Ranked List Truncation
Apr 26, 2020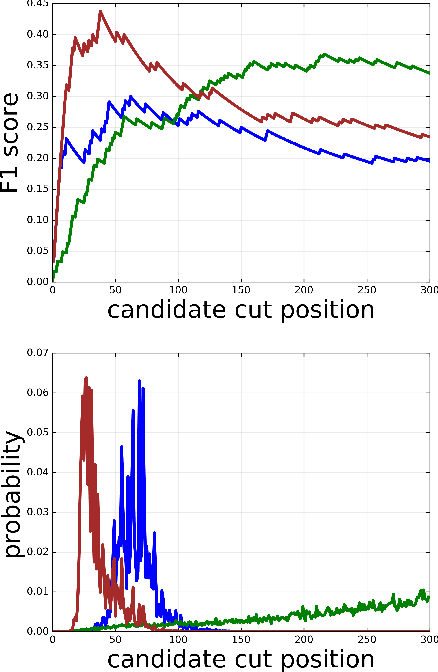
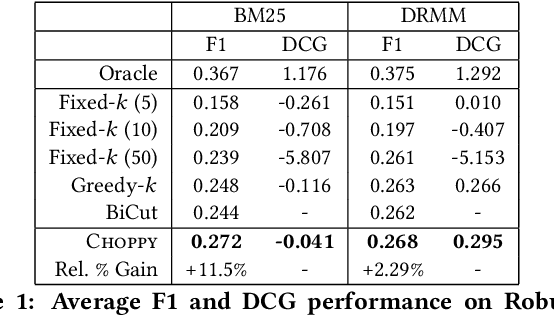
Work in information retrieval has traditionally focused on ranking and relevance: given a query, return some number of results ordered by relevance to the user. However, the problem of determining how many results to return, i.e. how to optimally truncate the ranked result list, has received less attention despite being of critical importance in a range of applications. Such truncation is a balancing act between the overall relevance, or usefulness of the results, with the user cost of processing more results. In this work, we propose Choppy, an assumption-free model based on the widely successful Transformer architecture, to the ranked list truncation problem. Needing nothing more than the relevance scores of the results, the model uses a powerful multi-head attention mechanism to directly optimize any user-defined IR metric. We show Choppy improves upon recent state-of-the-art methods.