 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the LSH Distortion of Ulam and Cayley Similarities
May 12, 2026Locality-sensitive hashing (LSH) has found widespread use as a fundamental primitive, particularly to accelerate nearest neighbor search. An LSH scheme for a similarity function $S:\mathcal{X} \times \mathcal{X} \to [0,1]$ is a distribution over hash functions on $\mathcal{X}$ with the property that the probability of collision of any two elements $x,y\in \mathcal{X}$ is exactly equal to $S(x,y)$. However, not all similarity functions admit exact LSH schemes. The notion of LSH distortion measures how multiplicatively close a similarity function is to having an LSH scheme. In this work, we study the LSH distortion of the Ulam and Cayley similarities, which are popular similarity measures on permutations of $n$ elements. We show that the Ulam similarity admits a sublinear LSH distortion of $O(n / \sqrt{\log n})$; we also prove a lower bound of $Ω(n^{0.12})$ on the best LSH distortion achievable. On the other hand, we show that the LSH distortion of the Cayley similarity is $Θ(n)$.
Learning Multinomial Logits in $O(n \log n)$ time
Jan 07, 2026A Multinomial Logit (MNL) model is composed of a finite universe of items $[n]=\{1,..., n\}$, each assigned a positive weight. A query specifies an admissible subset -- called a slate -- and the model chooses one item from that slate with probability proportional to its weight. This query model is also known as the Plackett-Luce model or conditional sampling oracle in the literature. Although MNLs have been studied extensively, a basic computational question remains open: given query access to slates, how efficiently can we learn weights so that, for every slate, the induced choice distribution is within total variation distance $\varepsilon$ of the ground truth? This question is central to MNL learning and has direct implications for modern recommender system interfaces. We provide two algorithms for this task, one with adaptive queries and one with non-adaptive queries. Each algorithm outputs an MNL $M'$ that induces, for each slate $S$, a distribution $M'_S$ on $S$ that is within $\varepsilon$ total variation distance of the true distribution. Our adaptive algorithm makes $O\left(\frac{n}{\varepsilon^{3}}\log n\right)$ queries, while our non-adaptive algorithm makes $O\left(\frac{n^{2}}{\varepsilon^{3}}\log n \log\frac{n}{\varepsilon}\right)$ queries. Both algorithms query only slates of size two and run in time proportional to their query complexity. We complement these upper bounds with lower bounds of $Ω\left(\frac{n}{\varepsilon^{2}}\log n\right)$ for adaptive queries and $Ω\left(\frac{n^{2}}{\varepsilon^{2}}\log n\right)$ for non-adaptive queries, thus proving that our adaptive algorithm is optimal in its dependence on the support size $n$, while the non-adaptive one is tight within a $\log n$ factor.
Approximating a RUM from Distributions on k-Slates
May 22, 2023


In this work we consider the problem of fitting Random Utility Models (RUMs) to user choices. Given the winner distributions of the subsets of size $k$ of a universe, we obtain a polynomial-time algorithm that finds the RUM that best approximates the given distribution on average. Our algorithm is based on a linear program that we solve using the ellipsoid method. Given that its corresponding separation oracle problem is NP-hard, we devise an approximate separation oracle that can be viewed as a generalization of the weighted feedback arc set problem to hypergraphs. Our theoretical result can also be made practical: we obtain a heuristic that is effective and scales to real-world datasets.
Correlation Clustering Reconstruction in Semi-Adversarial Models
Aug 10, 2021
Correlation Clustering is an important clustering problem with many applications. We study the reconstruction version of this problem in which one is seeking to reconstruct a latent clustering that has been corrupted by random noise and adversarial modifications. Concerning the latter, we study a standard "post-adversarial" model, in which adversarial modifications come after the noise, and also introduce and analyze a "pre-adversarial" model in which adversarial modifications come before the noise. Given an input coming from such a semi-adversarial generative model, the goal is to reconstruct almost perfectly and with high probability the latent clustering. We focus on the case where the hidden clusters have equal size and show the following. In the pre-adversarial setting, spectral algorithms are optimal, in the sense that they reconstruct all the way to the information-theoretic threshold beyond which no reconstruction is possible. In contrast, in the post-adversarial setting their ability to restore the hidden clusters stops before the threshold, but the gap is optimally filled by SDP-based algorithms.
On Additive Approximate Submodularity
Oct 07, 2020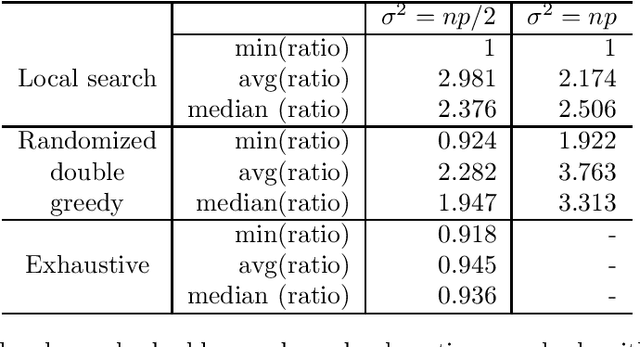
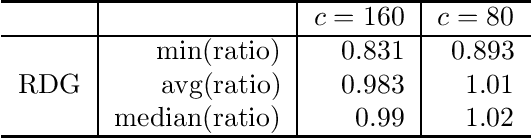
A real-valued set function is (additively) approximately submodular if it satisfies the submodularity conditions with an additive error. Approximate submodularity arises in many settings, especially in machine learning, where the function evaluation might not be exact. In this paper we study how close such approximately submodular functions are to truly submodular functions. We show that an approximately submodular function defined on a ground set of $n$ elements is $O(n^2)$ pointwise-close to a submodular function. This result also provides an algorithmic tool that can be used to adapt existing submodular optimization algorithms to approximately submodular functions. To complement, we show an $\Omega(\sqrt{n})$ lower bound on the distance to submodularity. These results stand in contrast to the case of approximate modularity, where the distance to modularity is a constant, and approximate convexity, where the distance to convexity is logarithmic.
Fair Clustering Through Fairlets
Feb 15, 2018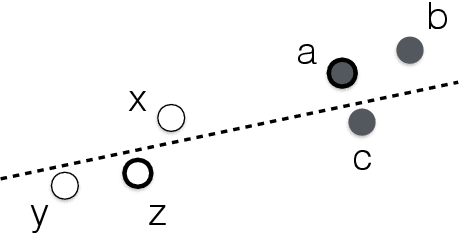
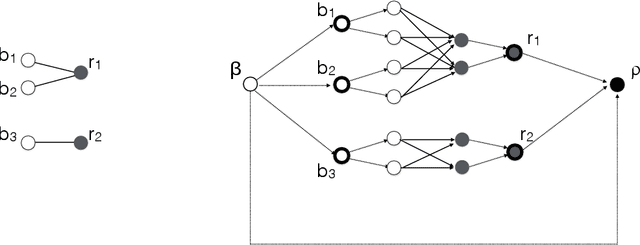
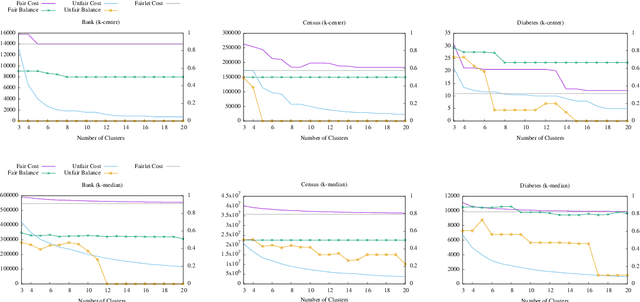
We study the question of fair clustering under the {\em disparate impact} doctrine, where each protected class must have approximately equal representation in every cluster. We formulate the fair clustering problem under both the $k$-center and the $k$-median objectives, and show that even with two protected classes the problem is challenging, as the optimum solution can violate common conventions---for instance a point may no longer be assigned to its nearest cluster center! En route we introduce the concept of fairlets, which are minimal sets that satisfy fair representation while approximately preserving the clustering objective. We show that any fair clustering problem can be decomposed into first finding good fairlets, and then using existing machinery for traditional clustering algorithms. While finding good fairlets can be NP-hard, we proceed to obtain efficient approximation algorithms based on minimum cost flow. We empirically quantify the value of fair clustering on real-world datasets with sensitive attributes.