 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Machine Translation to Localize Task Oriented NLG Output
Jul 09, 2021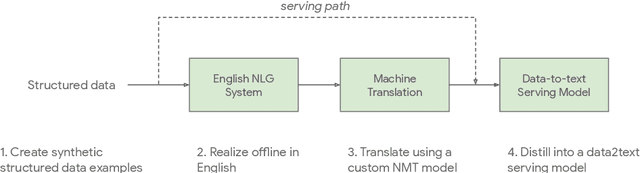
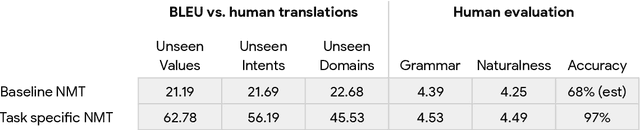
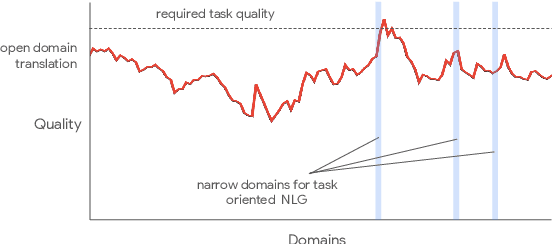
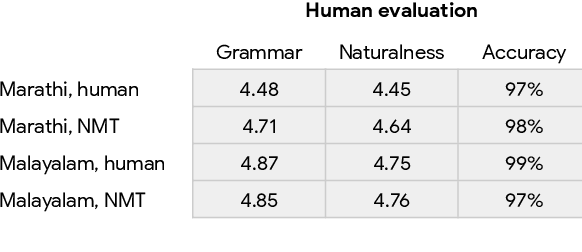
One of the challenges in a task oriented natural language application like the Google Assistant, Siri, or Alexa is to localize the output to many languages. This paper explores doing this by applying machine translation to the English output. Using machine translation is very scalable, as it can work with any English output and can handle dynamic text, but otherwise the problem is a poor fit. The required quality bar is close to perfection, the range of sentences is extremely narrow, and the sentences are often very different than the ones in the machine translation training data. This combination of requirements is novel in the field of domain adaptation for machine translation. We are able to reach the required quality bar by building on existing ideas and adding new ones: finetuning on in-domain translations, adding sentences from the Web, adding semantic annotations, and using automatic error detection. The paper shares our approach and results, together with a distillation model to serve the translation models at scale.
Generative Models are Unsupervised Predictors of Page Quality: A Colossal-Scale Study
Aug 17, 2020
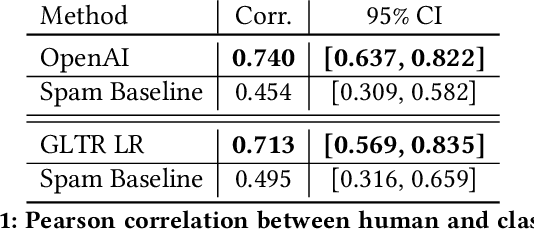
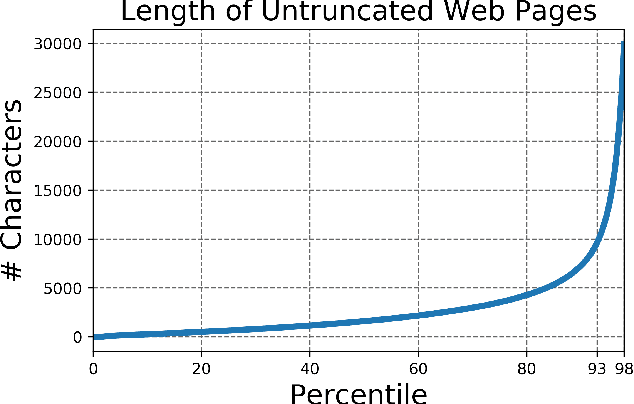

Large generative language models such as GPT-2 are well-known for their ability to generate text as well as their utility in supervised downstream tasks via fine-tuning. Our work is twofold: firstly we demonstrate via human evaluation that classifiers trained to discriminate between human and machine-generated text emerge as unsupervised predictors of "page quality", able to detect low quality content without any training. This enables fast bootstrapping of quality indicators in a low-resource setting. Secondly, curious to understand the prevalence and nature of low quality pages in the wild, we conduct extensive qualitative and quantitative analysis over 500 million web articles, making this the largest-scale study ever conducted on the topic.
Multilingual Language Processing From Bytes
Apr 02, 2016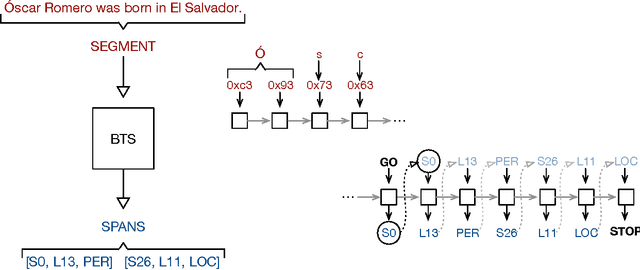
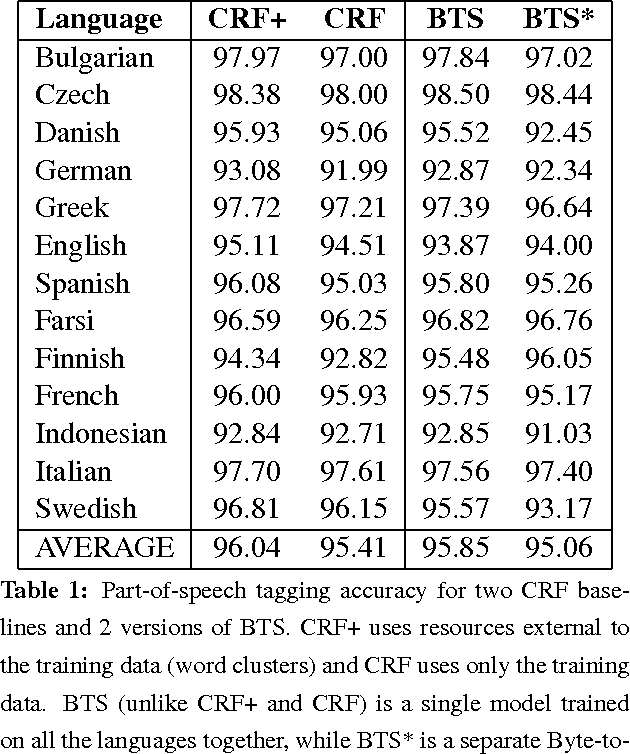
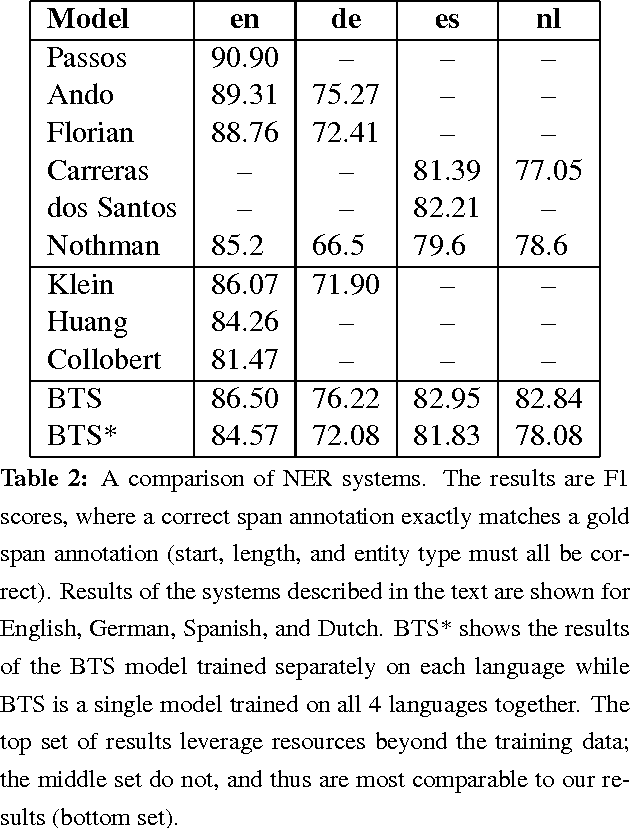

We describe an LSTM-based model which we call Byte-to-Span (BTS) that reads text as bytes and outputs span annotations of the form [start, length, label] where start positions, lengths, and labels are separate entries in our vocabulary. Because we operate directly on unicode bytes rather than language-specific words or characters, we can analyze text in many languages with a single model. Due to the small vocabulary size, these multilingual models are very compact, but produce results similar to or better than the state-of- the-art in Part-of-Speech tagging and Named Entity Recognition that use only the provided training datasets (no external data sources). Our models are learning "from scratch" in that they do not rely on any elements of the standard pipeline in Natural Language Processing (including tokenization), and thus can run in standalone fashion on raw text.