 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVibe-Eval: A hard evaluation suite for measuring progress of multimodal language models
May 03, 2024
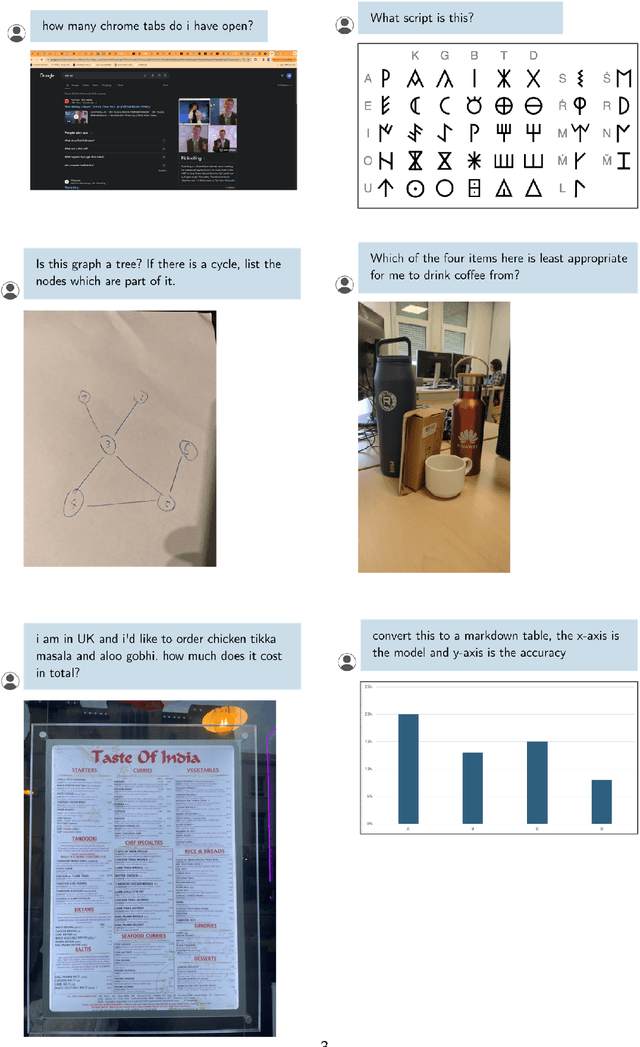
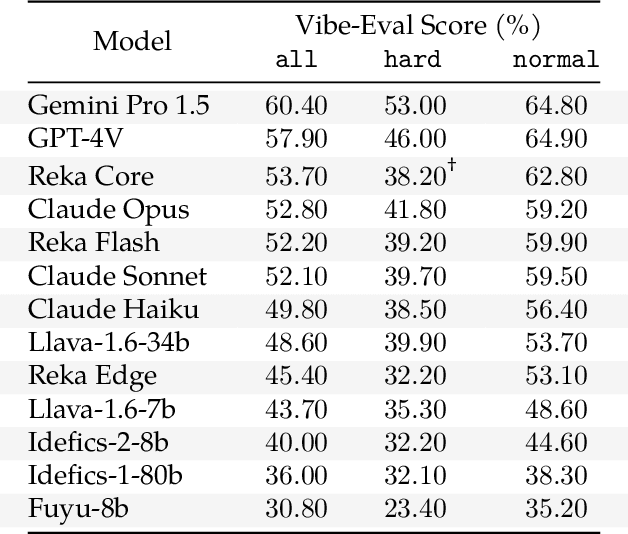
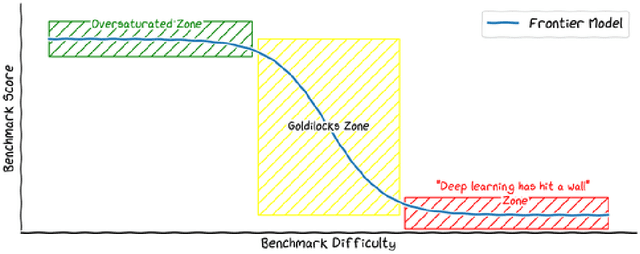
We introduce Vibe-Eval: a new open benchmark and framework for evaluating multimodal chat models. Vibe-Eval consists of 269 visual understanding prompts, including 100 of hard difficulty, complete with gold-standard responses authored by experts. Vibe-Eval is open-ended and challenging with dual objectives: (i) vibe checking multimodal chat models for day-to-day tasks and (ii) rigorously testing and probing the capabilities of present frontier models. Notably, our hard set contains >50% questions that all frontier models answer incorrectly. We explore the nuances of designing, evaluating, and ranking models on ultra challenging prompts. We also discuss trade-offs between human and automatic evaluation, and show that automatic model evaluation using Reka Core roughly correlates to human judgment. We offer free API access for the purpose of lightweight evaluation and plan to conduct formal human evaluations for public models that perform well on the Vibe-Eval's automatic scores. We release the evaluation code and data, see https://github.com/reka-ai/reka-vibe-eval
Reka Core, Flash, and Edge: A Series of Powerful Multimodal Language Models
Apr 18, 2024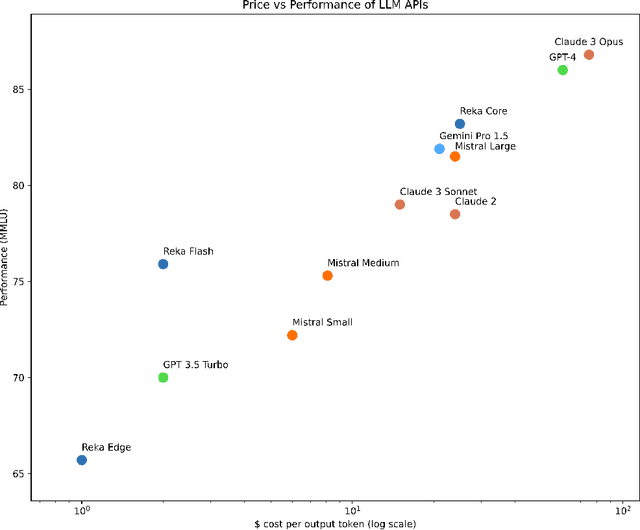


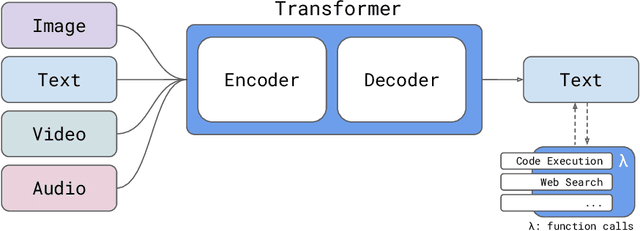
We introduce Reka Core, Flash, and Edge, a series of powerful multimodal language models trained from scratch by Reka. Reka models are able to process and reason with text, images, video, and audio inputs. This technical report discusses details of training some of these models and provides comprehensive evaluation results. We show that Reka Edge and Reka Flash are not only state-of-the-art but also outperform many much larger models, delivering outsized values for their respective compute class. Meanwhile, our most capable and largest model, Reka Core, approaches the best frontier models on both automatic evaluations and blind human evaluations. On image question answering benchmarks (e.g. MMMU, VQAv2), Core performs competitively to GPT4-V. Meanwhile, on multimodal chat, Core ranks as the second most preferred model under a blind third-party human evaluation setup, outperforming other models such as Claude 3 Opus. On text benchmarks, Core not only performs competitively to other frontier models on a set of well-established benchmarks (e.g. MMLU, GSM8K) but also outperforms GPT4-0613 on human evaluation. On video question answering (Perception-Test), Core outperforms Gemini Ultra. Models are shipped in production at http://chat.reka.ai . A showcase of non cherry picked qualitative examples can also be found at http://showcase.reka.ai .
StructFormer: Joint Unsupervised Induction of Dependency and Constituency Structure from Masked Language Modeling
Dec 15, 2020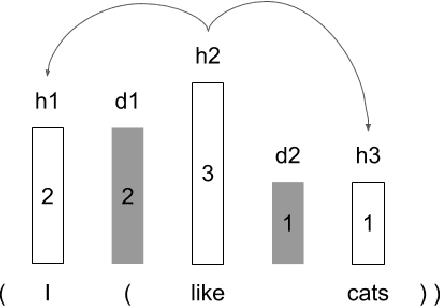

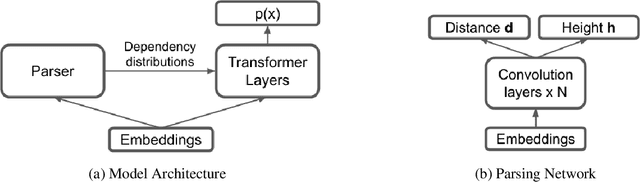
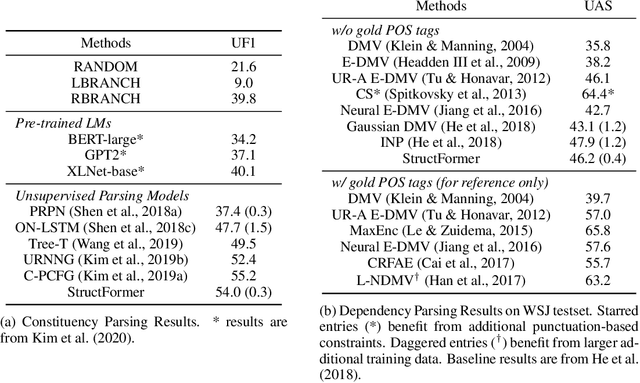
There are two major classes of natural language grammars -- the dependency grammar that models one-to-one correspondences between words and the constituency grammar that models the assembly of one or several corresponded words. While previous unsupervised parsing methods mostly focus on only inducing one class of grammars, we introduce a novel model, StructFormer, that can induce dependency and constituency structure at the same time. To achieve this, we propose a new parsing framework that can jointly generate a constituency tree and dependency graph. Then we integrate the induced dependency relations into the transformer, in a differentiable manner, through a novel dependency-constrained self-attention mechanism. Experimental results show that our model can achieve strong results on unsupervised constituency parsing, unsupervised dependency parsing, and masked language modeling at the same time.
Surprise: Result List Truncation via Extreme Value Theory
Oct 19, 2020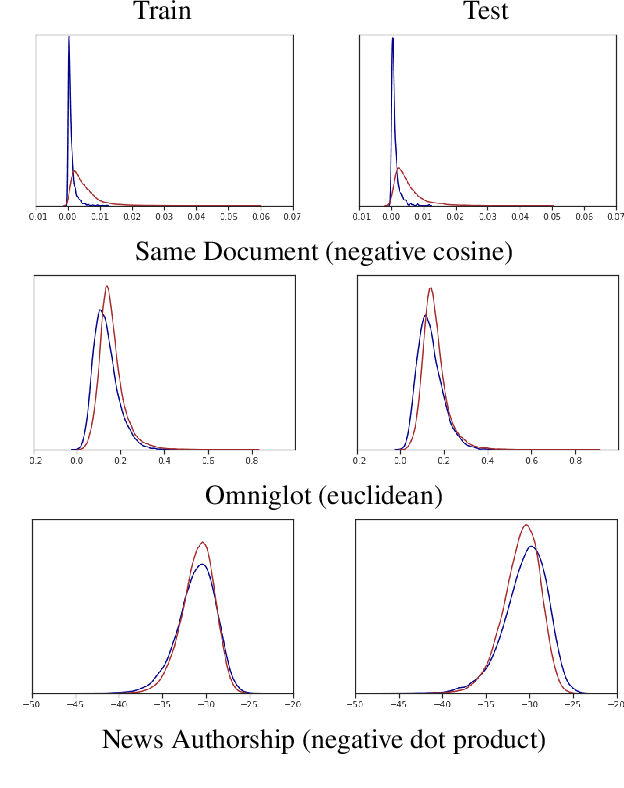
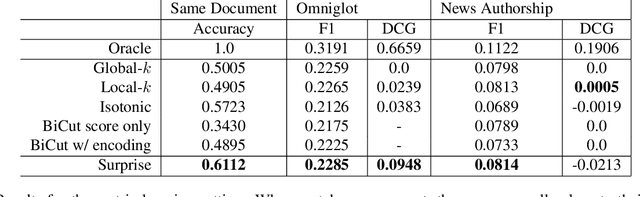
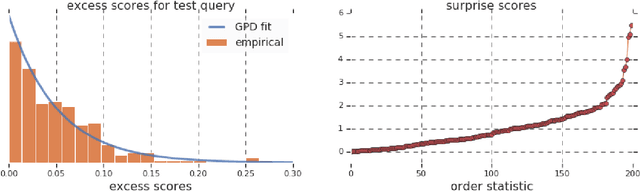
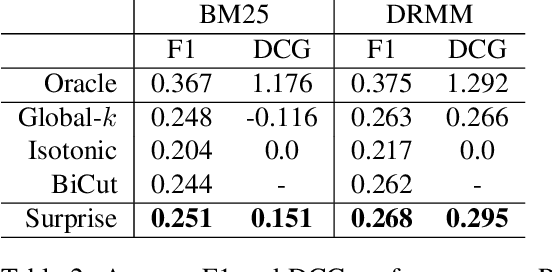
Work in information retrieval has largely been centered around ranking and relevance: given a query, return some number of results ordered by relevance to the user. The problem of result list truncation, or where to truncate the ranked list of results, however, has received less attention despite being crucial in a variety of applications. Such truncation is a balancing act between the overall relevance, or usefulness of the results, with the user cost of processing more results. Result list truncation can be challenging because relevance scores are often not well-calibrated. This is particularly true in large-scale IR systems where documents and queries are embedded in the same metric space and a query's nearest document neighbors are returned during inference. Here, relevance is inversely proportional to the distance between the query and candidate document, but what distance constitutes relevance varies from query to query and changes dynamically as more documents are added to the index. In this work, we propose Surprise scoring, a statistical method that leverages the Generalized Pareto distribution that arises in extreme value theory to produce interpretable and calibrated relevance scores at query time using nothing more than the ranked scores. We demonstrate its effectiveness on the result list truncation task across image, text, and IR datasets and compare it to both classical and recent baselines. We draw connections to hypothesis testing and $p$-values.
Generative Models are Unsupervised Predictors of Page Quality: A Colossal-Scale Study
Aug 17, 2020
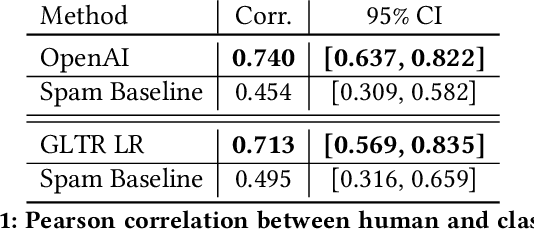
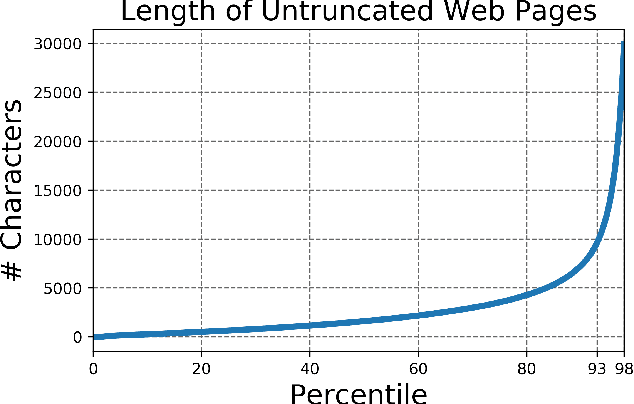

Large generative language models such as GPT-2 are well-known for their ability to generate text as well as their utility in supervised downstream tasks via fine-tuning. Our work is twofold: firstly we demonstrate via human evaluation that classifiers trained to discriminate between human and machine-generated text emerge as unsupervised predictors of "page quality", able to detect low quality content without any training. This enables fast bootstrapping of quality indicators in a low-resource setting. Secondly, curious to understand the prevalence and nature of low quality pages in the wild, we conduct extensive qualitative and quantitative analysis over 500 million web articles, making this the largest-scale study ever conducted on the topic.
Synthesizer: Rethinking Self-Attention in Transformer Models
May 02, 2020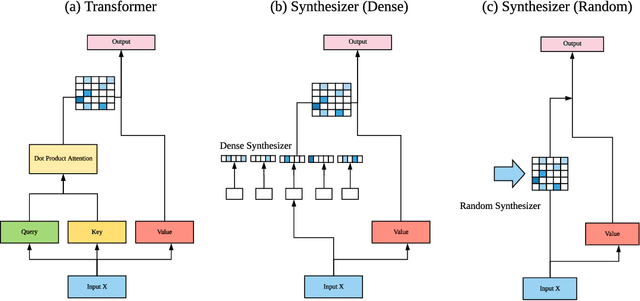

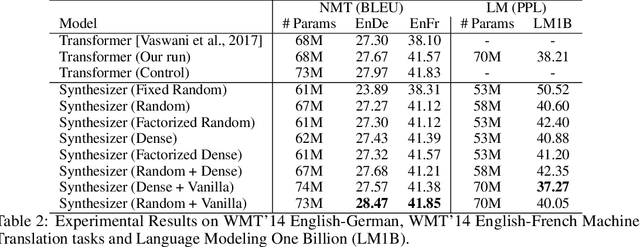

The dot product self-attention is known to be central and indispensable to state-of-the-art Transformer models. But is it really required? This paper investigates the true importance and contribution of the dot product-based self-attention mechanism on the performance of Transformer models. Via extensive experiments, we find that (1) random alignment matrices surprisingly perform quite competitively and (2) learning attention weights from token-token (query-key) interactions is not that important after all. To this end, we propose \textsc{Synthesizer}, a model that learns synthetic attention weights without token-token interactions. Our experimental results show that \textsc{Synthesizer} is competitive against vanilla Transformer models across a range of tasks, including MT (EnDe, EnFr), language modeling (LM1B), abstractive summarization (CNN/Dailymail), dialogue generation (PersonaChat) and Multi-task language understanding (GLUE, SuperGLUE).
Choppy: Cut Transformer For Ranked List Truncation
Apr 26, 2020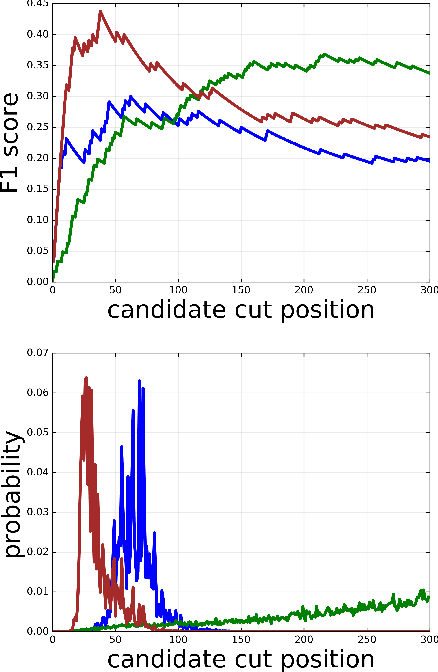
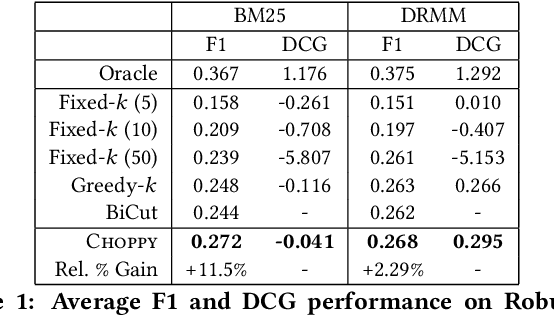
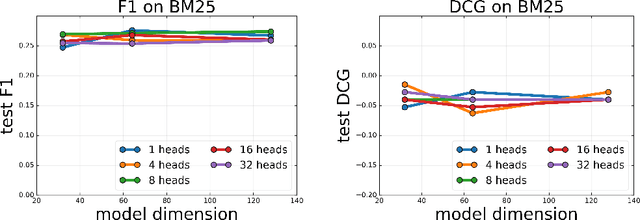
Work in information retrieval has traditionally focused on ranking and relevance: given a query, return some number of results ordered by relevance to the user. However, the problem of determining how many results to return, i.e. how to optimally truncate the ranked result list, has received less attention despite being of critical importance in a range of applications. Such truncation is a balancing act between the overall relevance, or usefulness of the results, with the user cost of processing more results. In this work, we propose Choppy, an assumption-free model based on the widely successful Transformer architecture, to the ranked list truncation problem. Needing nothing more than the relevance scores of the results, the model uses a powerful multi-head attention mechanism to directly optimize any user-defined IR metric. We show Choppy improves upon recent state-of-the-art methods.
Reverse Engineering Configurations of Neural Text Generation Models
Apr 13, 2020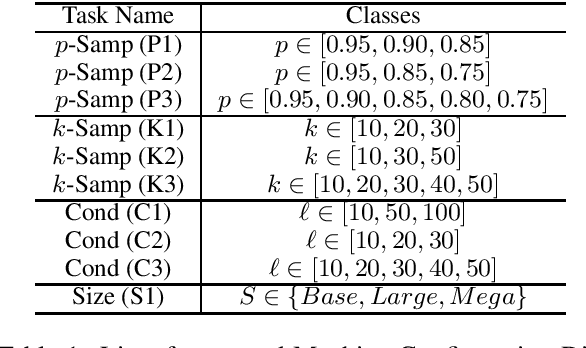
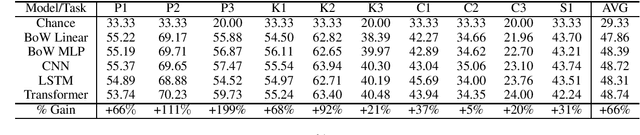
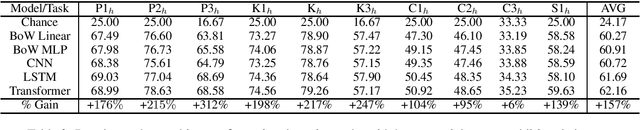
This paper seeks to develop a deeper understanding of the fundamental properties of neural text generations models. The study of artifacts that emerge in machine generated text as a result of modeling choices is a nascent research area. Previously, the extent and degree to which these artifacts surface in generated text has not been well studied. In the spirit of better understanding generative text models and their artifacts, we propose the new task of distinguishing which of several variants of a given model generated a piece of text, and we conduct an extensive suite of diagnostic tests to observe whether modeling choices (e.g., sampling methods, top-$k$ probabilities, model architectures, etc.) leave detectable artifacts in the text they generate. Our key finding, which is backed by a rigorous set of experiments, is that such artifacts are present and that different modeling choices can be inferred by observing the generated text alone. This suggests that neural text generators may be more sensitive to various modeling choices than previously thought.