 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVibe-Eval: A hard evaluation suite for measuring progress of multimodal language models
May 03, 2024
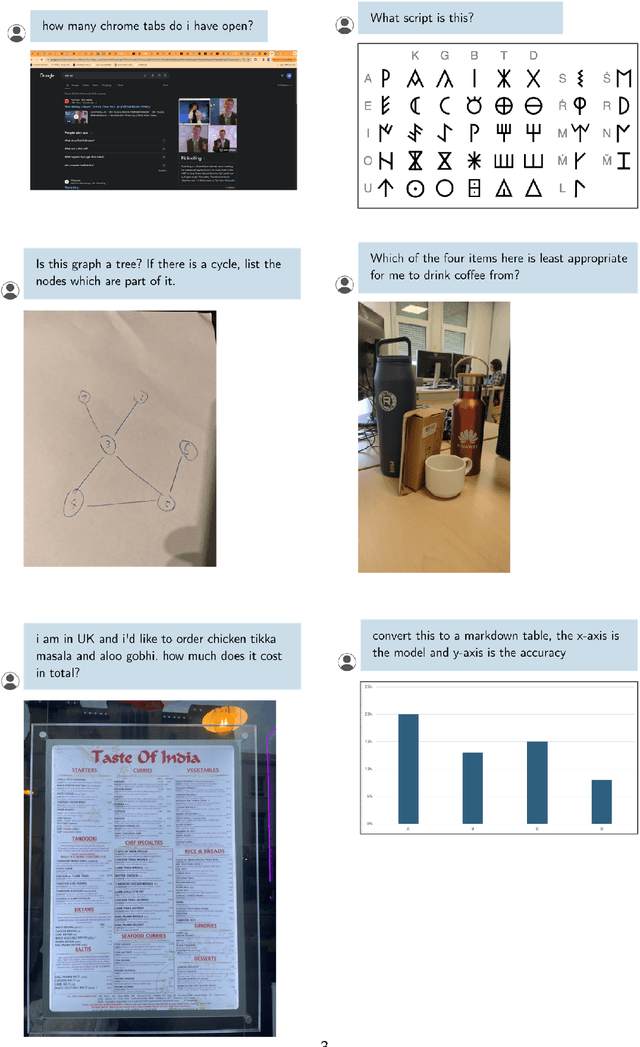
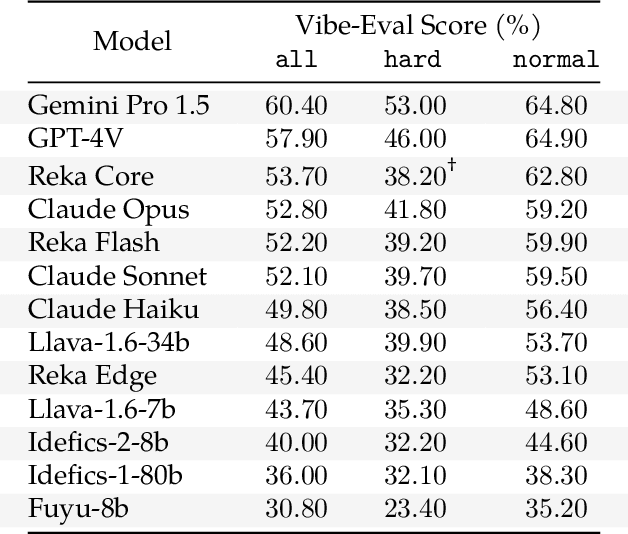
We introduce Vibe-Eval: a new open benchmark and framework for evaluating multimodal chat models. Vibe-Eval consists of 269 visual understanding prompts, including 100 of hard difficulty, complete with gold-standard responses authored by experts. Vibe-Eval is open-ended and challenging with dual objectives: (i) vibe checking multimodal chat models for day-to-day tasks and (ii) rigorously testing and probing the capabilities of present frontier models. Notably, our hard set contains >50% questions that all frontier models answer incorrectly. We explore the nuances of designing, evaluating, and ranking models on ultra challenging prompts. We also discuss trade-offs between human and automatic evaluation, and show that automatic model evaluation using Reka Core roughly correlates to human judgment. We offer free API access for the purpose of lightweight evaluation and plan to conduct formal human evaluations for public models that perform well on the Vibe-Eval's automatic scores. We release the evaluation code and data, see https://github.com/reka-ai/reka-vibe-eval
Reka Core, Flash, and Edge: A Series of Powerful Multimodal Language Models
Apr 18, 2024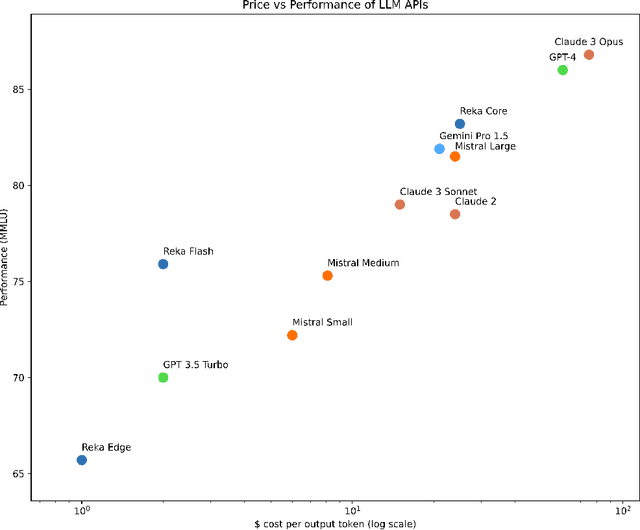


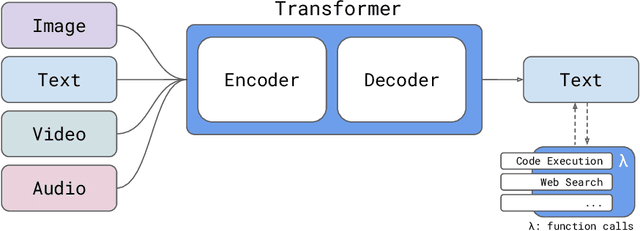
We introduce Reka Core, Flash, and Edge, a series of powerful multimodal language models trained from scratch by Reka. Reka models are able to process and reason with text, images, video, and audio inputs. This technical report discusses details of training some of these models and provides comprehensive evaluation results. We show that Reka Edge and Reka Flash are not only state-of-the-art but also outperform many much larger models, delivering outsized values for their respective compute class. Meanwhile, our most capable and largest model, Reka Core, approaches the best frontier models on both automatic evaluations and blind human evaluations. On image question answering benchmarks (e.g. MMMU, VQAv2), Core performs competitively to GPT4-V. Meanwhile, on multimodal chat, Core ranks as the second most preferred model under a blind third-party human evaluation setup, outperforming other models such as Claude 3 Opus. On text benchmarks, Core not only performs competitively to other frontier models on a set of well-established benchmarks (e.g. MMLU, GSM8K) but also outperforms GPT4-0613 on human evaluation. On video question answering (Perception-Test), Core outperforms Gemini Ultra. Models are shipped in production at http://chat.reka.ai . A showcase of non cherry picked qualitative examples can also be found at http://showcase.reka.ai .
Disentangling multiple scattering with deep learning: application to strain mapping from electron diffraction patterns
Feb 01, 2022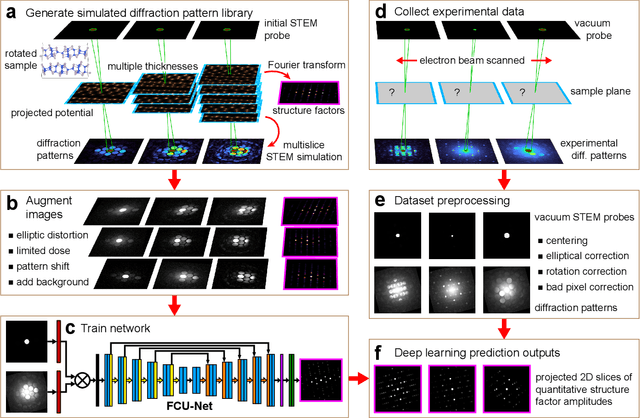
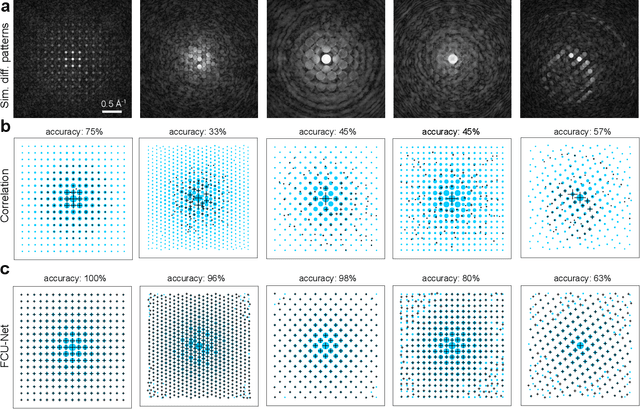
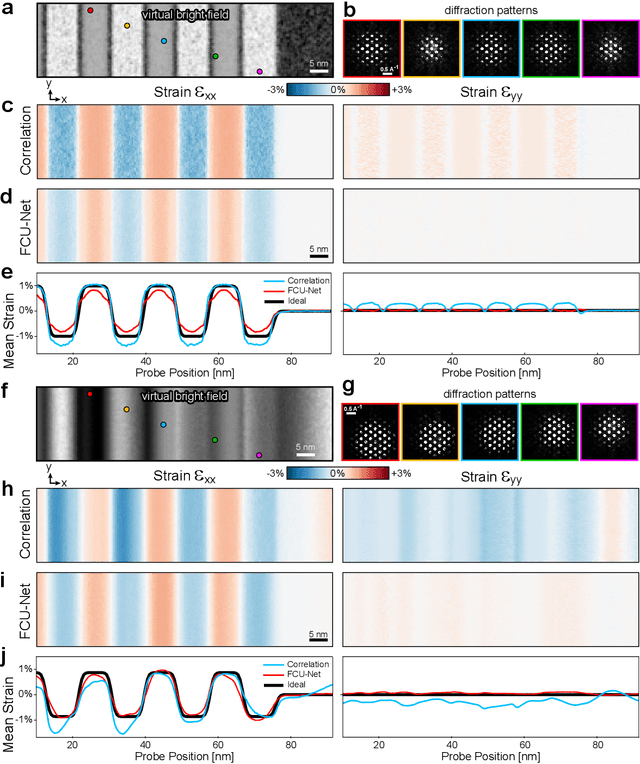

Implementation of a fast, robust, and fully-automated pipeline for crystal structure determination and underlying strain mapping for crystalline materials is important for many technological applications. Scanning electron nanodiffraction offers a procedure for identifying and collecting strain maps with good accuracy and high spatial resolutions. However, the application of this technique is limited, particularly in thick samples where the electron beam can undergo multiple scattering, which introduces signal nonlinearities. Deep learning methods have the potential to invert these complex signals, but previous implementations are often trained only on specific crystal systems or a small subset of the crystal structure and microscope parameter phase space. In this study, we implement a Fourier space, complex-valued deep neural network called FCU-Net, to invert highly nonlinear electron diffraction patterns into the corresponding quantitative structure factor images. We trained the FCU-Net using over 200,000 unique simulated dynamical diffraction patterns which include many different combinations of crystal structures, orientations, thicknesses, microscope parameters, and common experimental artifacts. We evaluated the trained FCU-Net model against simulated and experimental 4D-STEM diffraction datasets, where it substantially out-performs conventional analysis methods. Our simulated diffraction pattern library, implementation of FCU-Net, and trained model weights are freely available in open source repositories, and can be adapted to many different diffraction measurement problems.
ConVEx: Data-Efficient and Few-Shot Slot Labeling
Oct 22, 2020


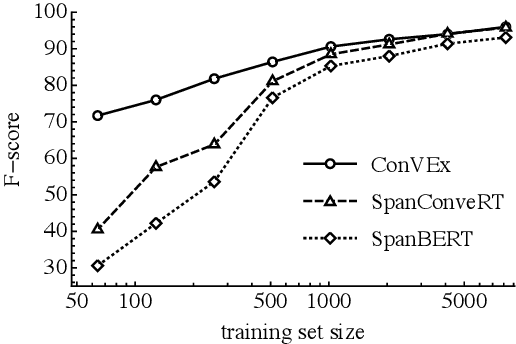
We propose ConVEx (Conversational Value Extractor), an efficient pretraining and fine-tuning neural approach for slot-labeling dialog tasks. Instead of relying on more general pretraining objectives from prior work (e.g., language modeling, response selection), ConVEx's pretraining objective, a novel pairwise cloze task using Reddit data, is well aligned with its intended usage on sequence labeling tasks. This enables learning domain-specific slot labelers by simply fine-tuning decoding layers of the pretrained general-purpose sequence labeling model, while the majority of the pretrained model's parameters are kept frozen. We report state-of-the-art performance of ConVEx across a range of diverse domains and data sets for dialog slot-labeling, with the largest gains in the most challenging, few-shot setups. We believe that ConVEx's reduced pretraining times (i.e., only 18 hours on 12 GPUs) and cost, along with its efficient fine-tuning and strong performance, promise wider portability and scalability for data-efficient sequence-labeling tasks in general.
Span-ConveRT: Few-shot Span Extraction for Dialog with Pretrained Conversational Representations
May 18, 2020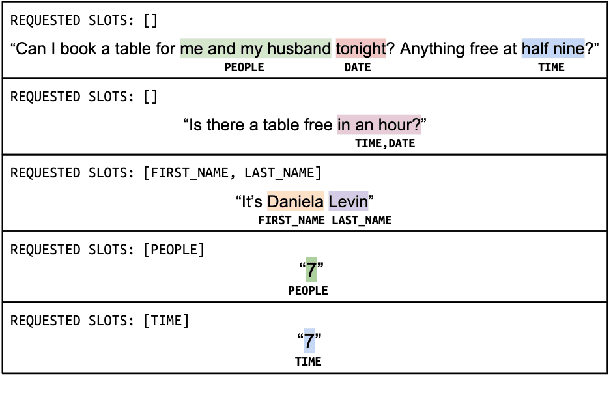

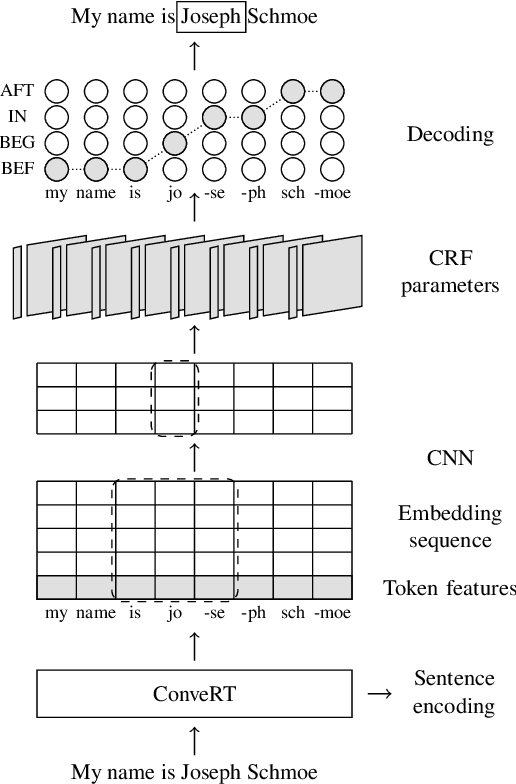

We introduce Span-ConveRT, a light-weight model for dialog slot-filling which frames the task as a turn-based span extraction task. This formulation allows for a simple integration of conversational knowledge coded in large pretrained conversational models such as ConveRT (Henderson et al., 2019). We show that leveraging such knowledge in Span-ConveRT is especially useful for few-shot learning scenarios: we report consistent gains over 1) a span extractor that trains representations from scratch in the target domain, and 2) a BERT-based span extractor. In order to inspire more work on span extraction for the slot-filling task, we also release RESTAURANTS-8K, a new challenging data set of 8,198 utterances, compiled from actual conversations in the restaurant booking domain.
Efficient Intent Detection with Dual Sentence Encoders
Mar 10, 2020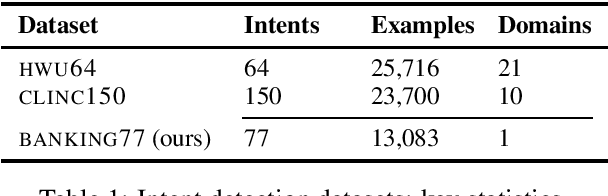

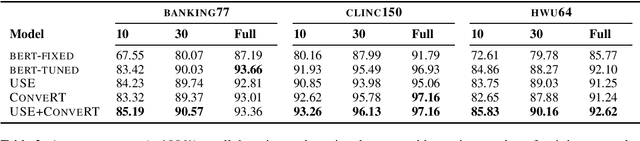

Building conversational systems in new domains and with added functionality requires resource-efficient models that work under low-data regimes (i.e., in few-shot setups). Motivated by these requirements, we introduce intent detection methods backed by pretrained dual sentence encoders such as USE and ConveRT. We demonstrate the usefulness and wide applicability of the proposed intent detectors, showing that: 1) they outperform intent detectors based on fine-tuning the full BERT-Large model or using BERT as a fixed black-box encoder on three diverse intent detection data sets; 2) the gains are especially pronounced in few-shot setups (i.e., with only 10 or 30 annotated examples per intent); 3) our intent detectors can be trained in a matter of minutes on a single CPU; and 4) they are stable across different hyperparameter settings. In hope of facilitating and democratizing research focused on intention detection, we release our code, as well as a new challenging single-domain intent detection dataset comprising 13,083 annotated examples over 77 intents.
ConveRT: Efficient and Accurate Conversational Representations from Transformers
Nov 09, 2019


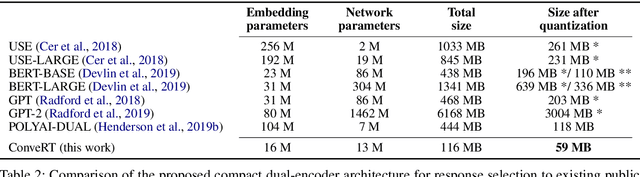
General-purpose pretrained sentence encoders such as BERT are not ideal for real-world conversational AI applications; they are computationally heavy, slow, and expensive to train. We propose ConveRT (Conversational Representations from Transformers), a faster, more compact dual sentence encoder specifically optimized for dialog tasks. We pretrain using a retrieval-based response selection task, effectively leveraging quantization and subword-level parameterization in the dual encoder to build a lightweight memory- and energy-efficient model. In our evaluation, we show that ConveRT achieves state-of-the-art performance across widely established response selection tasks. We also demonstrate that the use of extended dialog history as context yields further performance gains. Finally, we show that pretrained representations from the proposed encoder can be transferred to the intent classification task, yielding strong results across three diverse data sets. ConveRT trains substantially faster than standard sentence encoders or previous state-of-the-art dual encoders. With its reduced size and superior performance, we believe this model promises wider portability and scalability for Conversational AI applications.
PolyResponse: A Rank-based Approach to Task-Oriented Dialogue with Application in Restaurant Search and Booking
Sep 03, 2019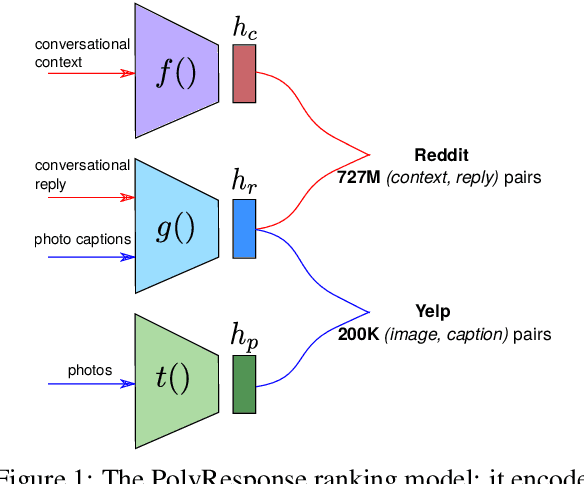
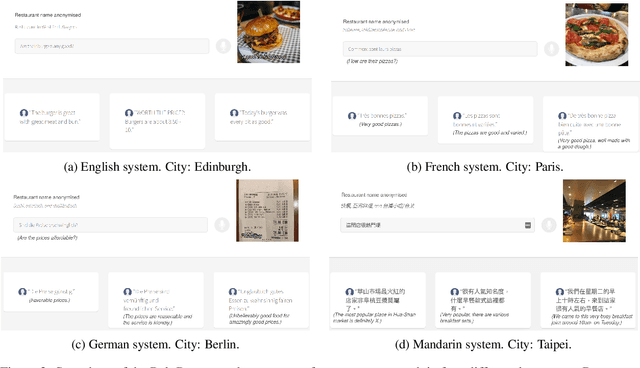
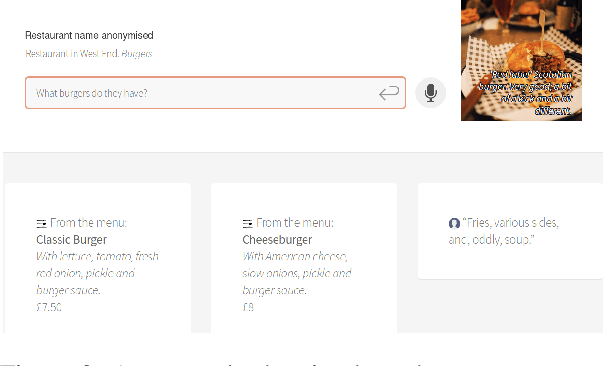
We present PolyResponse, a conversational search engine that supports task-oriented dialogue. It is a retrieval-based approach that bypasses the complex multi-component design of traditional task-oriented dialogue systems and the use of explicit semantics in the form of task-specific ontologies. The PolyResponse engine is trained on hundreds of millions of examples extracted from real conversations: it learns what responses are appropriate in different conversational contexts. It then ranks a large index of text and visual responses according to their similarity to the given context, and narrows down the list of relevant entities during the multi-turn conversation. We introduce a restaurant search and booking system powered by the PolyResponse engine, currently available in 8 different languages.
Training Neural Response Selection for Task-Oriented Dialogue Systems
Jun 07, 2019

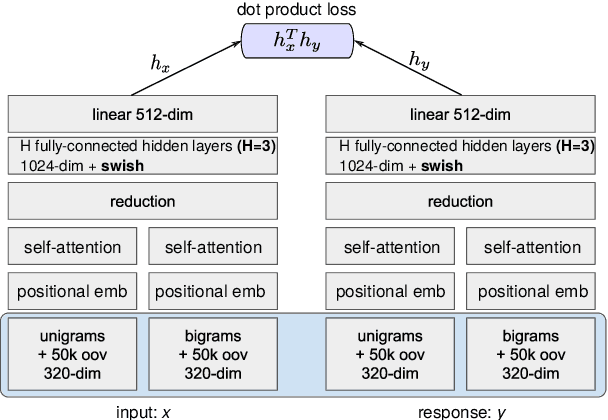

Despite their popularity in the chatbot literature, retrieval-based models have had modest impact on task-oriented dialogue systems, with the main obstacle to their application being the low-data regime of most task-oriented dialogue tasks. Inspired by the recent success of pretraining in language modelling, we propose an effective method for deploying response selection in task-oriented dialogue. To train response selection models for task-oriented dialogue tasks, we propose a novel method which: 1) pretrains the response selection model on large general-domain conversational corpora; and then 2) fine-tunes the pretrained model for the target dialogue domain, relying only on the small in-domain dataset to capture the nuances of the given dialogue domain. Our evaluation on six diverse application domains, ranging from e-commerce to banking, demonstrates the effectiveness of the proposed training method.
A Repository of Conversational Datasets
May 29, 2019

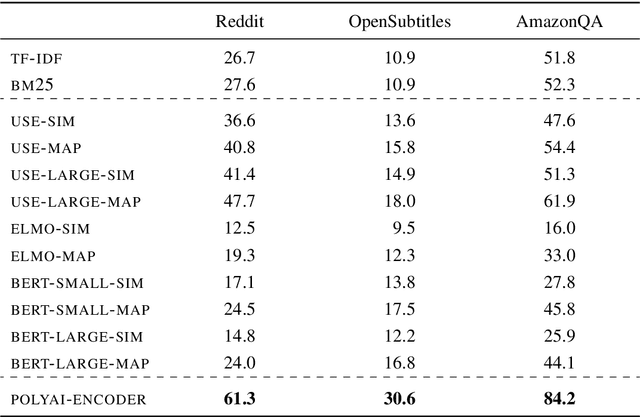

Progress in Machine Learning is often driven by the availability of large datasets, and consistent evaluation metrics for comparing modeling approaches. To this end, we present a repository of conversational datasets consisting of hundreds of millions of examples, and a standardised evaluation procedure for conversational response selection models using '1-of-100 accuracy'. The repository contains scripts that allow researchers to reproduce the standard datasets, or to adapt the pre-processing and data filtering steps to their needs. We introduce and evaluate several competitive baselines for conversational response selection, whose implementations are shared in the repository, as well as a neural encoder model that is trained on the entire training set.