 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvFiT: Conversational Fine-Tuning of Pretrained Language Models
Sep 21, 2021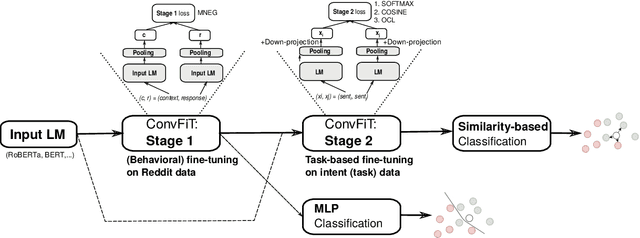

Transformer-based language models (LMs) pretrained on large text collections are proven to store a wealth of semantic knowledge. However, 1) they are not effective as sentence encoders when used off-the-shelf, and 2) thus typically lag behind conversationally pretrained (e.g., via response selection) encoders on conversational tasks such as intent detection (ID). In this work, we propose ConvFiT, a simple and efficient two-stage procedure which turns any pretrained LM into a universal conversational encoder (after Stage 1 ConvFiT-ing) and task-specialised sentence encoder (after Stage 2). We demonstrate that 1) full-blown conversational pretraining is not required, and that LMs can be quickly transformed into effective conversational encoders with much smaller amounts of unannotated data; 2) pretrained LMs can be fine-tuned into task-specialised sentence encoders, optimised for the fine-grained semantics of a particular task. Consequently, such specialised sentence encoders allow for treating ID as a simple semantic similarity task based on interpretable nearest neighbours retrieval. We validate the robustness and versatility of the ConvFiT framework with such similarity-based inference on the standard ID evaluation sets: ConvFiT-ed LMs achieve state-of-the-art ID performance across the board, with particular gains in the most challenging, few-shot setups.
Multilingual and Cross-Lingual Intent Detection from Spoken Data
Apr 17, 2021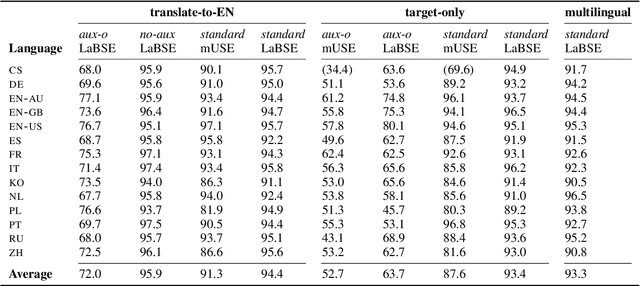
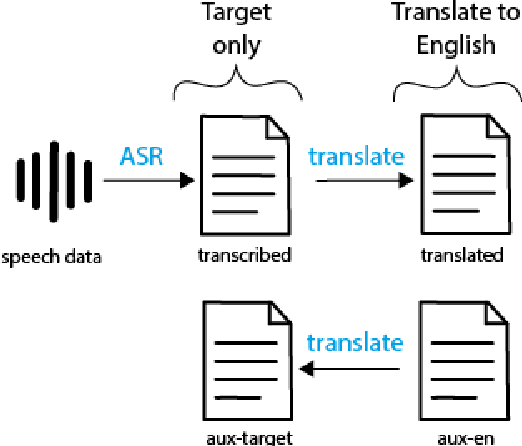
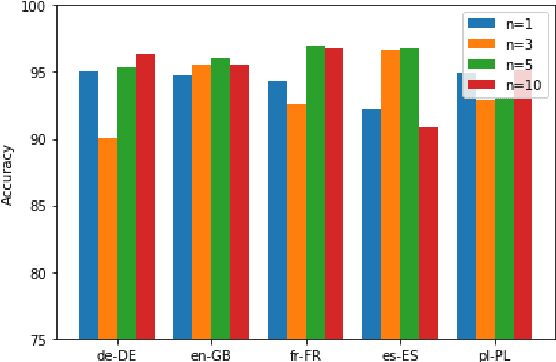
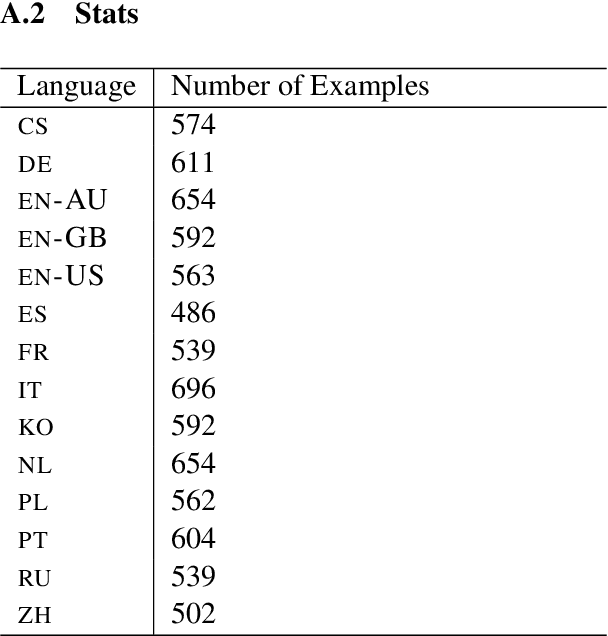
We present a systematic study on multilingual and cross-lingual intent detection from spoken data. The study leverages a new resource put forth in this work, termed MInDS-14, a first training and evaluation resource for the intent detection task with spoken data. It covers 14 intents extracted from a commercial system in the e-banking domain, associated with spoken examples in 14 diverse language varieties. Our key results indicate that combining machine translation models with state-of-the-art multilingual sentence encoders (e.g., LaBSE) can yield strong intent detectors in the majority of target languages covered in MInDS-14, and offer comparative analyses across different axes: e.g., zero-shot versus few-shot learning, translation direction, and impact of speech recognition. We see this work as an important step towards more inclusive development and evaluation of multilingual intent detectors from spoken data, in a much wider spectrum of languages compared to prior work.
Span-ConveRT: Few-shot Span Extraction for Dialog with Pretrained Conversational Representations
May 18, 2020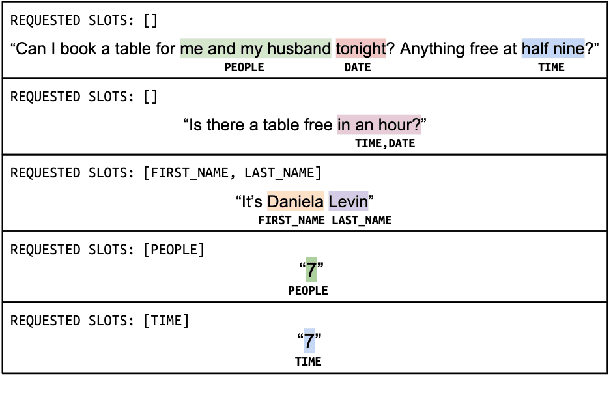


We introduce Span-ConveRT, a light-weight model for dialog slot-filling which frames the task as a turn-based span extraction task. This formulation allows for a simple integration of conversational knowledge coded in large pretrained conversational models such as ConveRT (Henderson et al., 2019). We show that leveraging such knowledge in Span-ConveRT is especially useful for few-shot learning scenarios: we report consistent gains over 1) a span extractor that trains representations from scratch in the target domain, and 2) a BERT-based span extractor. In order to inspire more work on span extraction for the slot-filling task, we also release RESTAURANTS-8K, a new challenging data set of 8,198 utterances, compiled from actual conversations in the restaurant booking domain.
Multidirectional Associative Optimization of Function-Specific Word Representations
May 11, 2020



We present a neural framework for learning associations between interrelated groups of words such as the ones found in Subject-Verb-Object (SVO) structures. Our model induces a joint function-specific word vector space, where vectors of e.g. plausible SVO compositions lie close together. The model retains information about word group membership even in the joint space, and can thereby effectively be applied to a number of tasks reasoning over the SVO structure. We show the robustness and versatility of the proposed framework by reporting state-of-the-art results on the tasks of estimating selectional preference and event similarity. The results indicate that the combinations of representations learned with our task-independent model outperform task-specific architectures from prior work, while reducing the number of parameters by up to 95%.
Efficient Intent Detection with Dual Sentence Encoders
Mar 10, 2020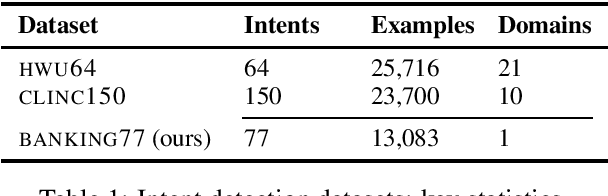

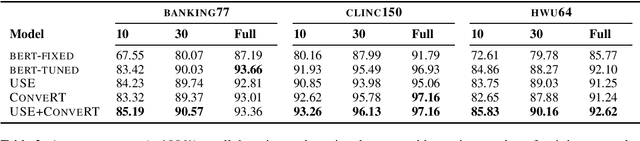

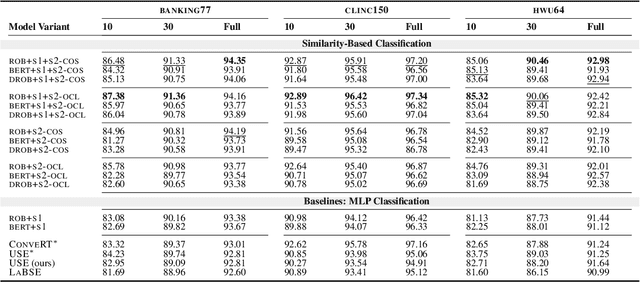
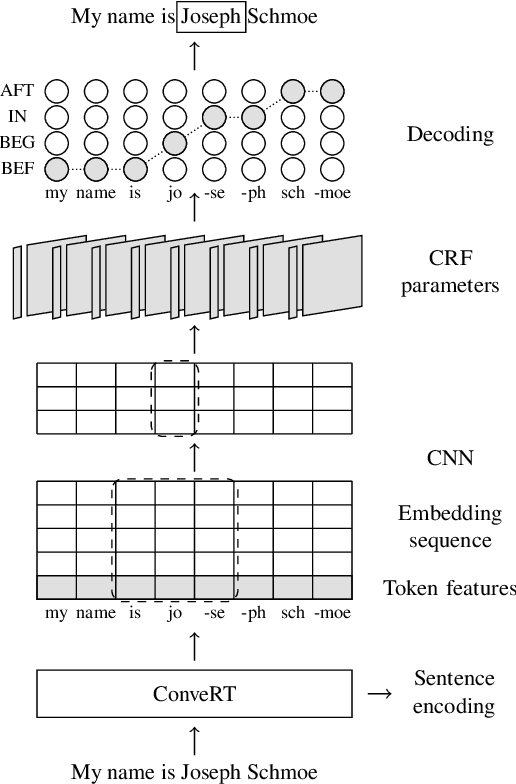
Building conversational systems in new domains and with added functionality requires resource-efficient models that work under low-data regimes (i.e., in few-shot setups). Motivated by these requirements, we introduce intent detection methods backed by pretrained dual sentence encoders such as USE and ConveRT. We demonstrate the usefulness and wide applicability of the proposed intent detectors, showing that: 1) they outperform intent detectors based on fine-tuning the full BERT-Large model or using BERT as a fixed black-box encoder on three diverse intent detection data sets; 2) the gains are especially pronounced in few-shot setups (i.e., with only 10 or 30 annotated examples per intent); 3) our intent detectors can be trained in a matter of minutes on a single CPU; and 4) they are stable across different hyperparameter settings. In hope of facilitating and democratizing research focused on intention detection, we release our code, as well as a new challenging single-domain intent detection dataset comprising 13,083 annotated examples over 77 intents.
PolyResponse: A Rank-based Approach to Task-Oriented Dialogue with Application in Restaurant Search and Booking
Sep 03, 2019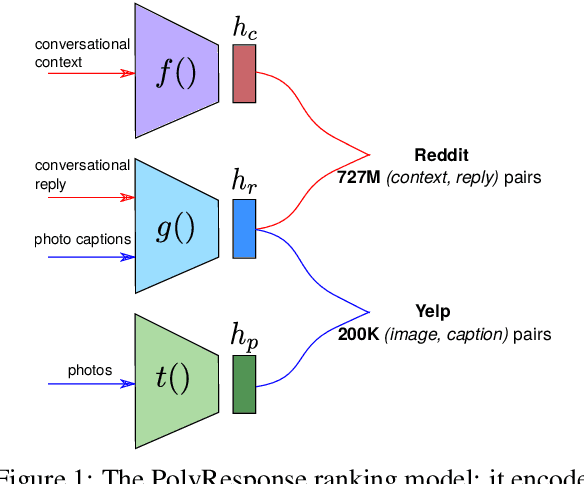
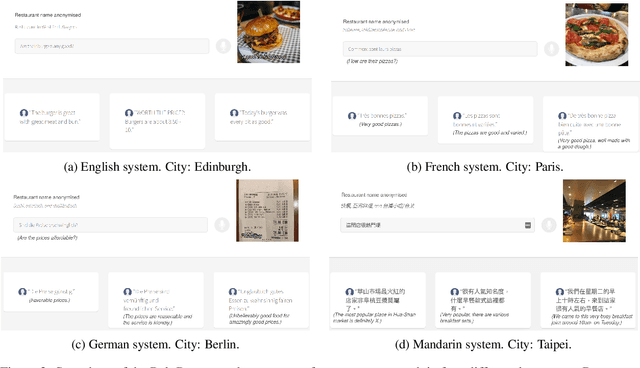
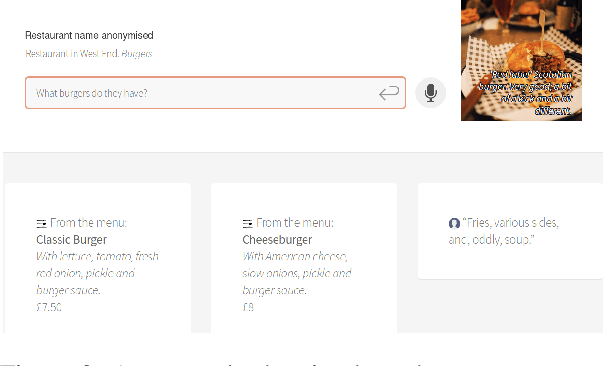
We present PolyResponse, a conversational search engine that supports task-oriented dialogue. It is a retrieval-based approach that bypasses the complex multi-component design of traditional task-oriented dialogue systems and the use of explicit semantics in the form of task-specific ontologies. The PolyResponse engine is trained on hundreds of millions of examples extracted from real conversations: it learns what responses are appropriate in different conversational contexts. It then ranks a large index of text and visual responses according to their similarity to the given context, and narrows down the list of relevant entities during the multi-turn conversation. We introduce a restaurant search and booking system powered by the PolyResponse engine, currently available in 8 different languages.
Training Neural Response Selection for Task-Oriented Dialogue Systems
Jun 07, 2019

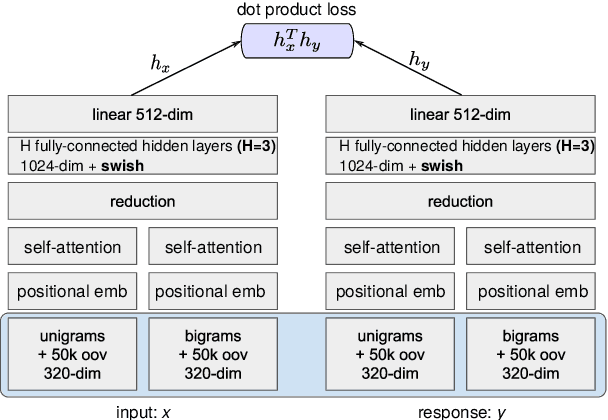

Despite their popularity in the chatbot literature, retrieval-based models have had modest impact on task-oriented dialogue systems, with the main obstacle to their application being the low-data regime of most task-oriented dialogue tasks. Inspired by the recent success of pretraining in language modelling, we propose an effective method for deploying response selection in task-oriented dialogue. To train response selection models for task-oriented dialogue tasks, we propose a novel method which: 1) pretrains the response selection model on large general-domain conversational corpora; and then 2) fine-tunes the pretrained model for the target dialogue domain, relying only on the small in-domain dataset to capture the nuances of the given dialogue domain. Our evaluation on six diverse application domains, ranging from e-commerce to banking, demonstrates the effectiveness of the proposed training method.
A Repository of Conversational Datasets
May 29, 2019

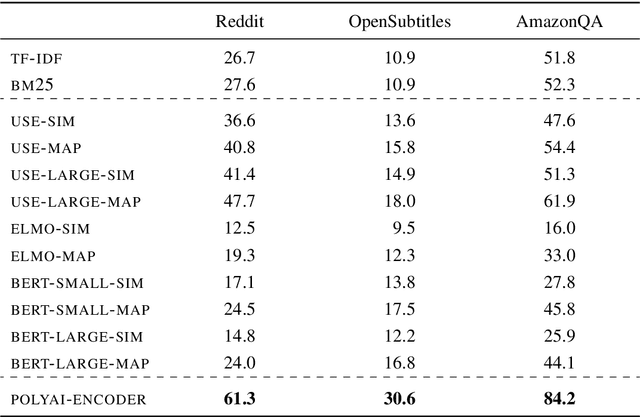

Progress in Machine Learning is often driven by the availability of large datasets, and consistent evaluation metrics for comparing modeling approaches. To this end, we present a repository of conversational datasets consisting of hundreds of millions of examples, and a standardised evaluation procedure for conversational response selection models using '1-of-100 accuracy'. The repository contains scripts that allow researchers to reproduce the standard datasets, or to adapt the pre-processing and data filtering steps to their needs. We introduce and evaluate several competitive baselines for conversational response selection, whose implementations are shared in the repository, as well as a neural encoder model that is trained on the entire training set.
Scoring Lexical Entailment with a Supervised Directional Similarity Network
May 23, 2018

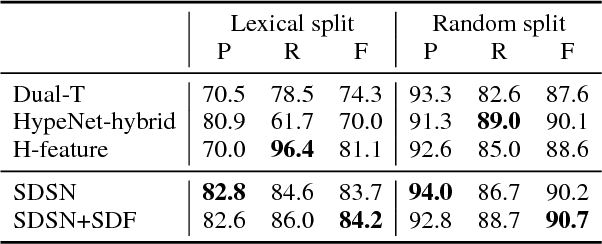

We present the Supervised Directional Similarity Network (SDSN), a novel neural architecture for learning task-specific transformation functions on top of general-purpose word embeddings. Relying on only a limited amount of supervision from task-specific scores on a subset of the vocabulary, our architecture is able to generalise and transform a general-purpose distributional vector space to model the relation of lexical entailment. Experiments show excellent performance on scoring graded lexical entailment, raising the state-of-the-art on the HyperLex dataset by approximately 25%.
HyperLex: A Large-Scale Evaluation of Graded Lexical Entailment
May 10, 2017We introduce HyperLex - a dataset and evaluation resource that quantifies the extent of of the semantic category membership, that is, type-of relation also known as hyponymy-hypernymy or lexical entailment (LE) relation between 2,616 concept pairs. Cognitive psychology research has established that typicality and category/class membership are computed in human semantic memory as a gradual rather than binary relation. Nevertheless, most NLP research, and existing large-scale invetories of concept category membership (WordNet, DBPedia, etc.) treat category membership and LE as binary. To address this, we asked hundreds of native English speakers to indicate typicality and strength of category membership between a diverse range of concept pairs on a crowdsourcing platform. Our results confirm that category membership and LE are indeed more gradual than binary. We then compare these human judgements with the predictions of automatic systems, which reveals a huge gap between human performance and state-of-the-art LE, distributional and representation learning models, and substantial differences between the models themselves. We discuss a pathway for improving semantic models to overcome this discrepancy, and indicate future application areas for improved graded LE systems.