 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvFiT: Conversational Fine-Tuning of Pretrained Language Models
Sep 21, 2021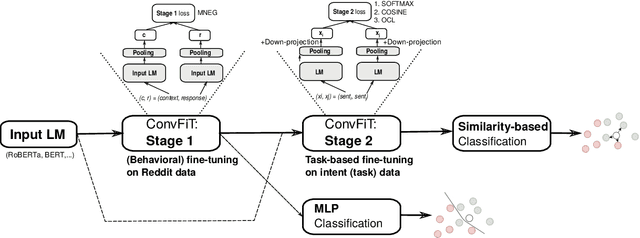
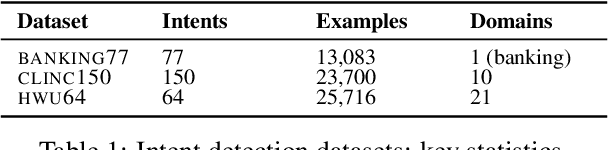

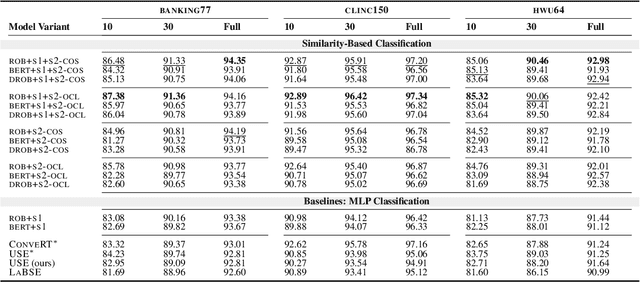
Transformer-based language models (LMs) pretrained on large text collections are proven to store a wealth of semantic knowledge. However, 1) they are not effective as sentence encoders when used off-the-shelf, and 2) thus typically lag behind conversationally pretrained (e.g., via response selection) encoders on conversational tasks such as intent detection (ID). In this work, we propose ConvFiT, a simple and efficient two-stage procedure which turns any pretrained LM into a universal conversational encoder (after Stage 1 ConvFiT-ing) and task-specialised sentence encoder (after Stage 2). We demonstrate that 1) full-blown conversational pretraining is not required, and that LMs can be quickly transformed into effective conversational encoders with much smaller amounts of unannotated data; 2) pretrained LMs can be fine-tuned into task-specialised sentence encoders, optimised for the fine-grained semantics of a particular task. Consequently, such specialised sentence encoders allow for treating ID as a simple semantic similarity task based on interpretable nearest neighbours retrieval. We validate the robustness and versatility of the ConvFiT framework with such similarity-based inference on the standard ID evaluation sets: ConvFiT-ed LMs achieve state-of-the-art ID performance across the board, with particular gains in the most challenging, few-shot setups.
Multilingual and Cross-Lingual Intent Detection from Spoken Data
Apr 17, 2021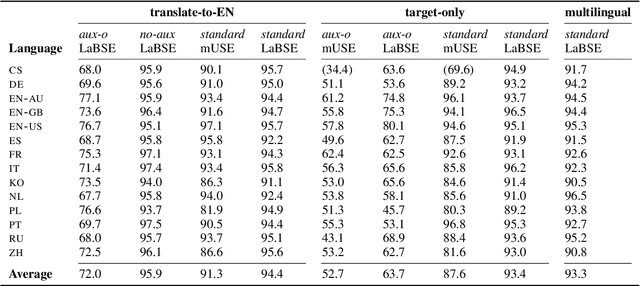
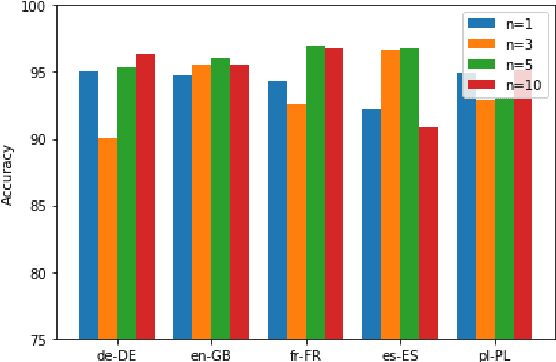
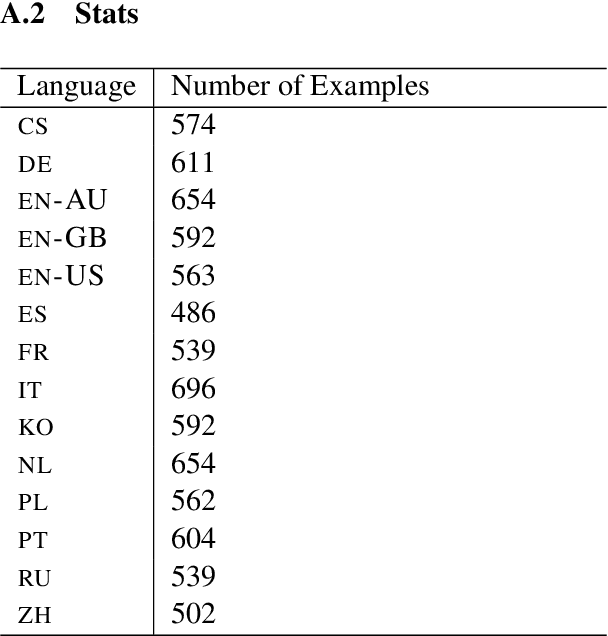
We present a systematic study on multilingual and cross-lingual intent detection from spoken data. The study leverages a new resource put forth in this work, termed MInDS-14, a first training and evaluation resource for the intent detection task with spoken data. It covers 14 intents extracted from a commercial system in the e-banking domain, associated with spoken examples in 14 diverse language varieties. Our key results indicate that combining machine translation models with state-of-the-art multilingual sentence encoders (e.g., LaBSE) can yield strong intent detectors in the majority of target languages covered in MInDS-14, and offer comparative analyses across different axes: e.g., zero-shot versus few-shot learning, translation direction, and impact of speech recognition. We see this work as an important step towards more inclusive development and evaluation of multilingual intent detectors from spoken data, in a much wider spectrum of languages compared to prior work.
ConveRT: Efficient and Accurate Conversational Representations from Transformers
Nov 09, 2019


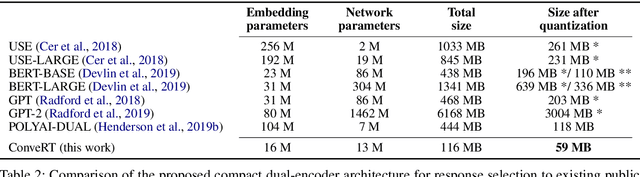
General-purpose pretrained sentence encoders such as BERT are not ideal for real-world conversational AI applications; they are computationally heavy, slow, and expensive to train. We propose ConveRT (Conversational Representations from Transformers), a faster, more compact dual sentence encoder specifically optimized for dialog tasks. We pretrain using a retrieval-based response selection task, effectively leveraging quantization and subword-level parameterization in the dual encoder to build a lightweight memory- and energy-efficient model. In our evaluation, we show that ConveRT achieves state-of-the-art performance across widely established response selection tasks. We also demonstrate that the use of extended dialog history as context yields further performance gains. Finally, we show that pretrained representations from the proposed encoder can be transferred to the intent classification task, yielding strong results across three diverse data sets. ConveRT trains substantially faster than standard sentence encoders or previous state-of-the-art dual encoders. With its reduced size and superior performance, we believe this model promises wider portability and scalability for Conversational AI applications.
PolyResponse: A Rank-based Approach to Task-Oriented Dialogue with Application in Restaurant Search and Booking
Sep 03, 2019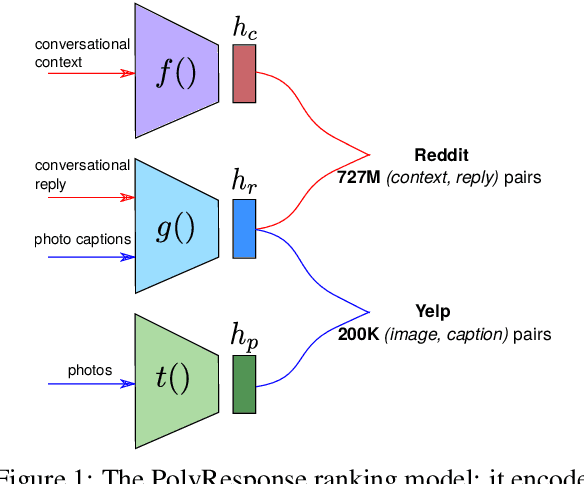
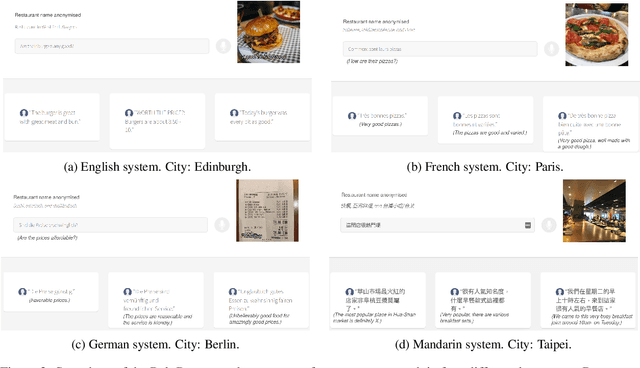
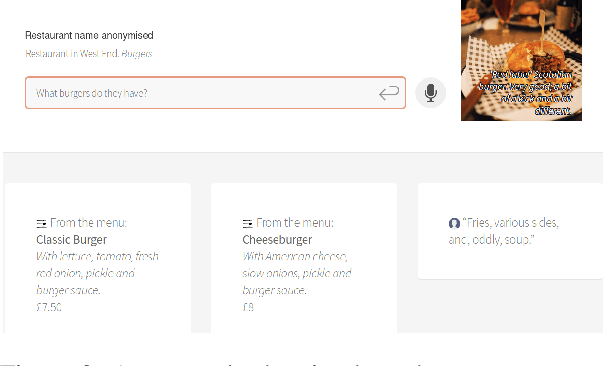
We present PolyResponse, a conversational search engine that supports task-oriented dialogue. It is a retrieval-based approach that bypasses the complex multi-component design of traditional task-oriented dialogue systems and the use of explicit semantics in the form of task-specific ontologies. The PolyResponse engine is trained on hundreds of millions of examples extracted from real conversations: it learns what responses are appropriate in different conversational contexts. It then ranks a large index of text and visual responses according to their similarity to the given context, and narrows down the list of relevant entities during the multi-turn conversation. We introduce a restaurant search and booking system powered by the PolyResponse engine, currently available in 8 different languages.
Training Neural Response Selection for Task-Oriented Dialogue Systems
Jun 07, 2019

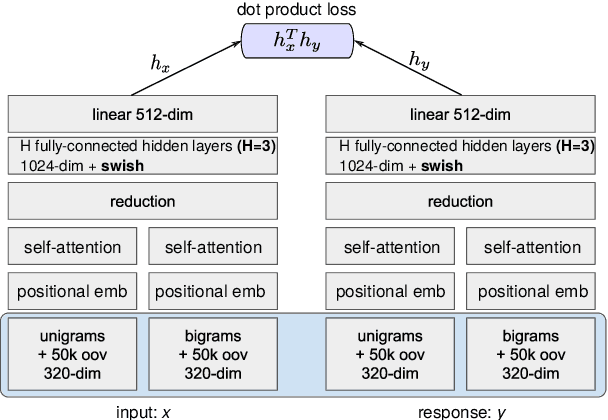

Despite their popularity in the chatbot literature, retrieval-based models have had modest impact on task-oriented dialogue systems, with the main obstacle to their application being the low-data regime of most task-oriented dialogue tasks. Inspired by the recent success of pretraining in language modelling, we propose an effective method for deploying response selection in task-oriented dialogue. To train response selection models for task-oriented dialogue tasks, we propose a novel method which: 1) pretrains the response selection model on large general-domain conversational corpora; and then 2) fine-tunes the pretrained model for the target dialogue domain, relying only on the small in-domain dataset to capture the nuances of the given dialogue domain. Our evaluation on six diverse application domains, ranging from e-commerce to banking, demonstrates the effectiveness of the proposed training method.
A Repository of Conversational Datasets
May 29, 2019

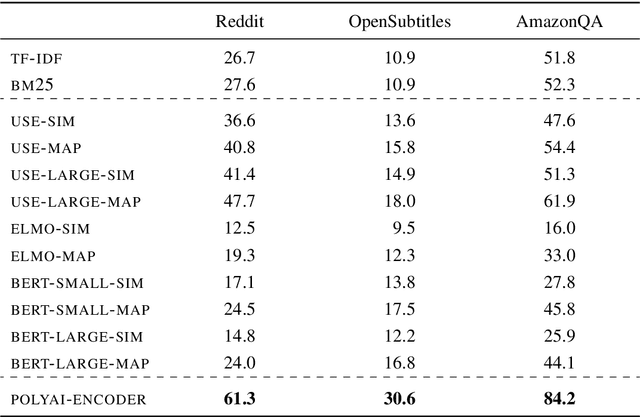

Progress in Machine Learning is often driven by the availability of large datasets, and consistent evaluation metrics for comparing modeling approaches. To this end, we present a repository of conversational datasets consisting of hundreds of millions of examples, and a standardised evaluation procedure for conversational response selection models using '1-of-100 accuracy'. The repository contains scripts that allow researchers to reproduce the standard datasets, or to adapt the pre-processing and data filtering steps to their needs. We introduce and evaluate several competitive baselines for conversational response selection, whose implementations are shared in the repository, as well as a neural encoder model that is trained on the entire training set.
Adversarial Propagation and Zero-Shot Cross-Lingual Transfer of Word Vector Specialization
Sep 11, 2018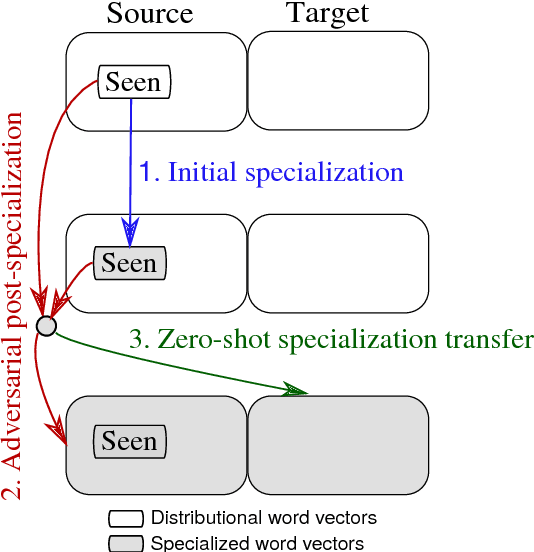
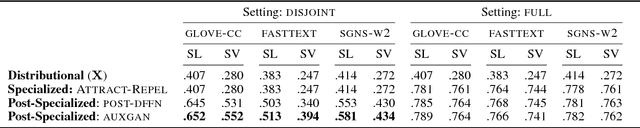
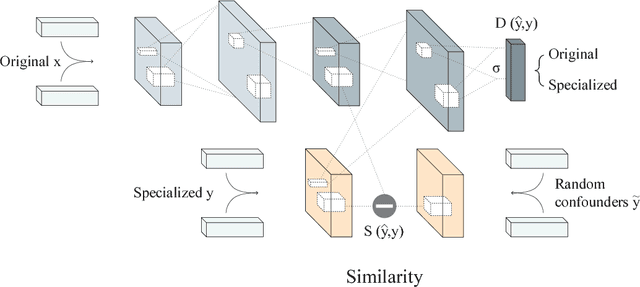
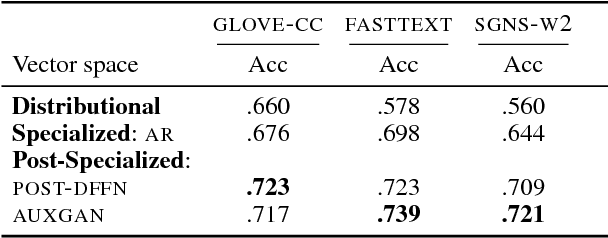
Semantic specialization is the process of fine-tuning pre-trained distributional word vectors using external lexical knowledge (e.g., WordNet) to accentuate a particular semantic relation in the specialized vector space. While post-processing specialization methods are applicable to arbitrary distributional vectors, they are limited to updating only the vectors of words occurring in external lexicons (i.e., seen words), leaving the vectors of all other words unchanged. We propose a novel approach to specializing the full distributional vocabulary. Our adversarial post-specialization method propagates the external lexical knowledge to the full distributional space. We exploit words seen in the resources as training examples for learning a global specialization function. This function is learned by combining a standard L2-distance loss with an adversarial loss: the adversarial component produces more realistic output vectors. We show the effectiveness and robustness of the proposed method across three languages and on three tasks: word similarity, dialog state tracking, and lexical simplification. We report consistent improvements over distributional word vectors and vectors specialized by other state-of-the-art specialization frameworks. Finally, we also propose a cross-lingual transfer method for zero-shot specialization which successfully specializes a full target distributional space without any lexical knowledge in the target language and without any bilingual data.
Fully Statistical Neural Belief Tracking
May 29, 2018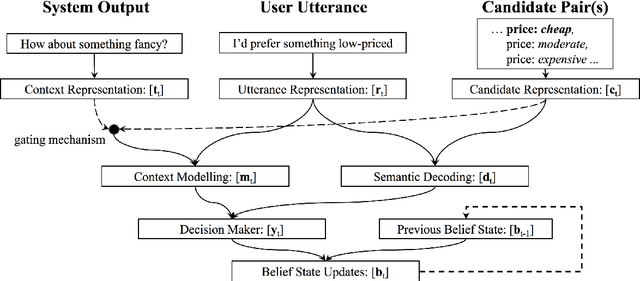
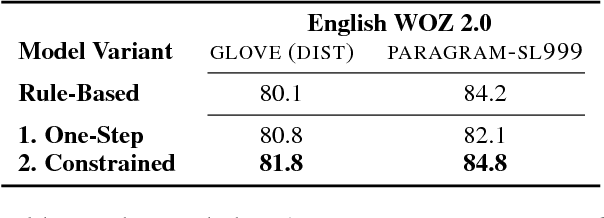
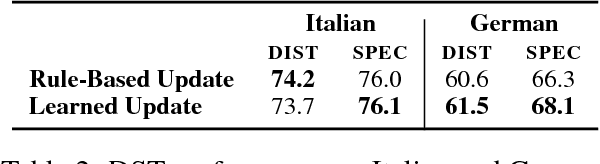
This paper proposes an improvement to the existing data-driven Neural Belief Tracking (NBT) framework for Dialogue State Tracking (DST). The existing NBT model uses a hand-crafted belief state update mechanism which involves an expensive manual retuning step whenever the model is deployed to a new dialogue domain. We show that this update mechanism can be learned jointly with the semantic decoding and context modelling parts of the NBT model, eliminating the last rule-based module from this DST framework. We propose two different statistical update mechanisms and show that dialogue dynamics can be modelled with a very small number of additional model parameters. In our DST evaluation over three languages, we show that this model achieves competitive performance and provides a robust framework for building resource-light DST models.
Post-Specialisation: Retrofitting Vectors of Words Unseen in Lexical Resources
May 08, 2018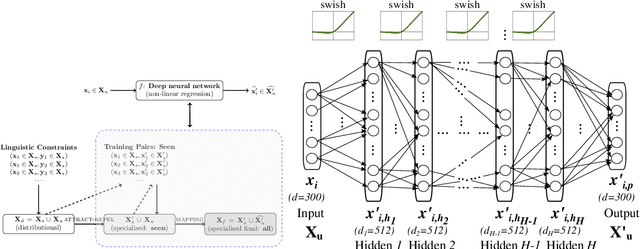

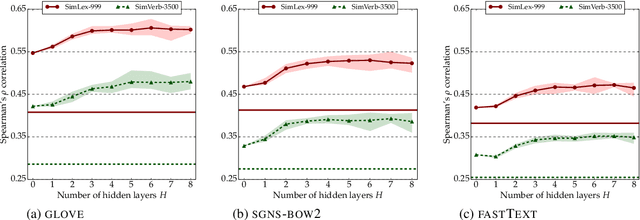
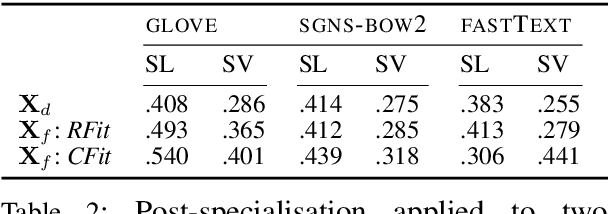
Word vector specialisation (also known as retrofitting) is a portable, light-weight approach to fine-tuning arbitrary distributional word vector spaces by injecting external knowledge from rich lexical resources such as WordNet. By design, these post-processing methods only update the vectors of words occurring in external lexicons, leaving the representations of all unseen words intact. In this paper, we show that constraint-driven vector space specialisation can be extended to unseen words. We propose a novel post-specialisation method that: a) preserves the useful linguistic knowledge for seen words; while b) propagating this external signal to unseen words in order to improve their vector representations as well. Our post-specialisation approach explicits a non-linear specialisation function in the form of a deep neural network by learning to predict specialised vectors from their original distributional counterparts. The learned function is then used to specialise vectors of unseen words. This approach, applicable to any post-processing model, yields considerable gains over the initial specialisation models both in intrinsic word similarity tasks, and in two downstream tasks: dialogue state tracking and lexical text simplification. The positive effects persist across three languages, demonstrating the importance of specialising the full vocabulary of distributional word vector spaces.
Specialising Word Vectors for Lexical Entailment
Apr 19, 2018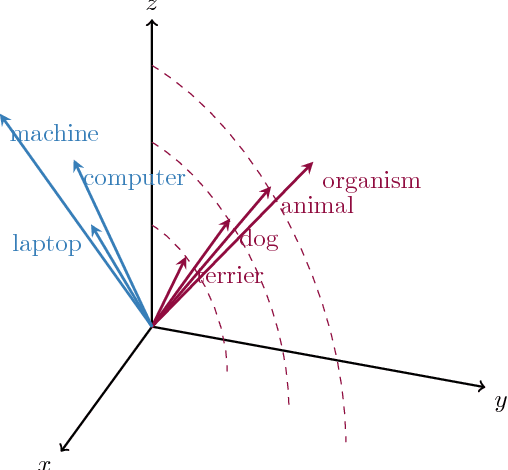


We present LEAR (Lexical Entailment Attract-Repel), a novel post-processing method that transforms any input word vector space to emphasise the asymmetric relation of lexical entailment (LE), also known as the IS-A or hyponymy-hypernymy relation. By injecting external linguistic constraints (e.g., WordNet links) into the initial vector space, the LE specialisation procedure brings true hyponymy-hypernymy pairs closer together in the transformed Euclidean space. The proposed asymmetric distance measure adjusts the norms of word vectors to reflect the actual WordNet-style hierarchy of concepts. Simultaneously, a joint objective enforces semantic similarity using the symmetric cosine distance, yielding a vector space specialised for both lexical relations at once. LEAR specialisation achieves state-of-the-art performance in the tasks of hypernymy directionality, hypernymy detection, and graded lexical entailment, demonstrating the effectiveness and robustness of the proposed asymmetric specialisation model.