 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEVI: Multilingual Spoken Dialogue Tasks and Dataset for Knowledge-Based Enrolment, Verification, and Identification
Apr 28, 2022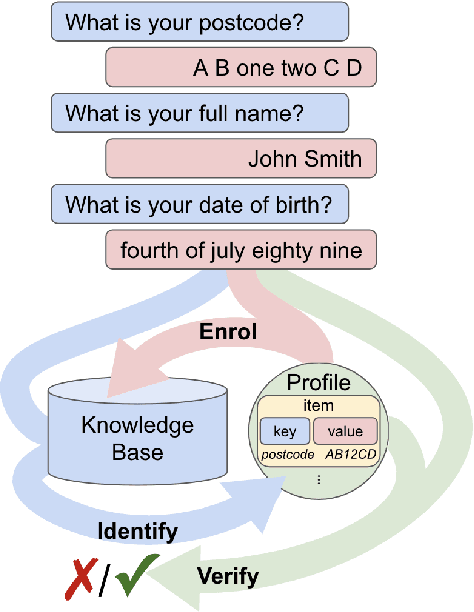
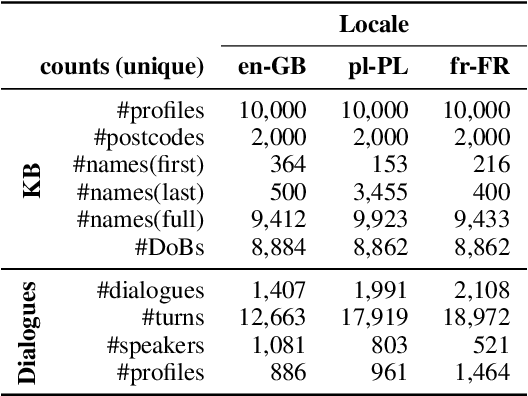
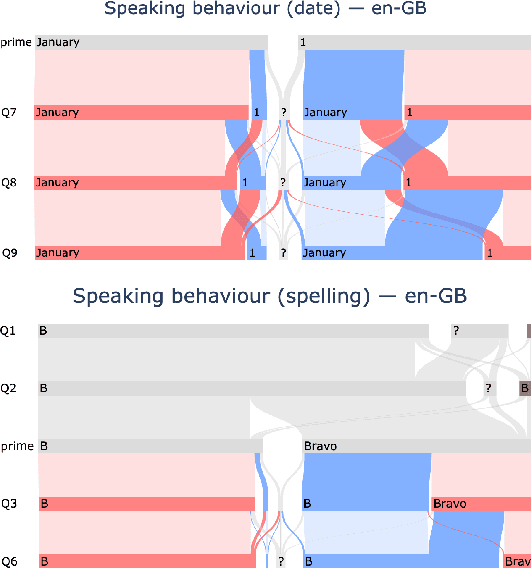
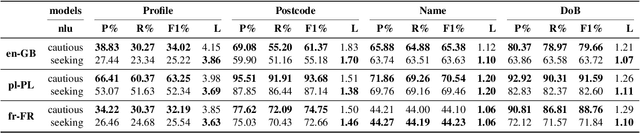
Knowledge-based authentication is crucial for task-oriented spoken dialogue systems that offer personalised and privacy-focused services. Such systems should be able to enrol (E), verify (V), and identify (I) new and recurring users based on their personal information, e.g. postcode, name, and date of birth. In this work, we formalise the three authentication tasks and their evaluation protocols, and we present EVI, a challenging spoken multilingual dataset with 5,506 dialogues in English, Polish, and French. Our proposed models set the first competitive benchmarks, explore the challenges of multilingual natural language processing of spoken dialogue, and set directions for future research.
Multilingual and Cross-Lingual Intent Detection from Spoken Data
Apr 17, 2021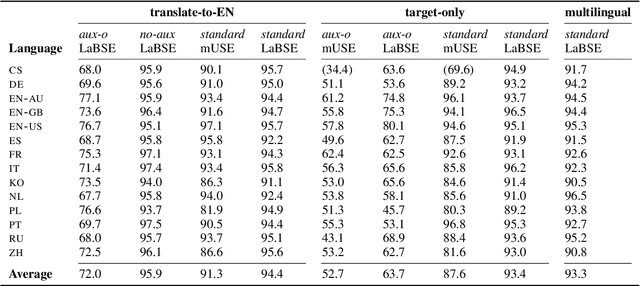
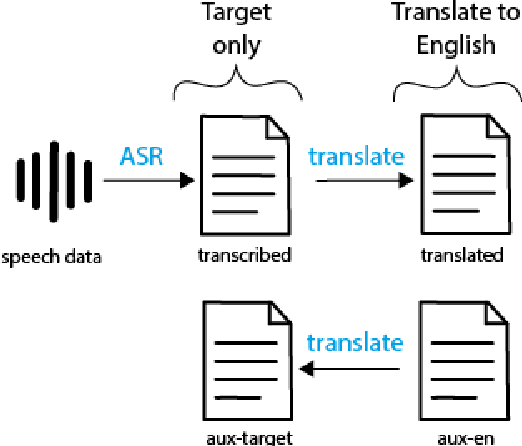
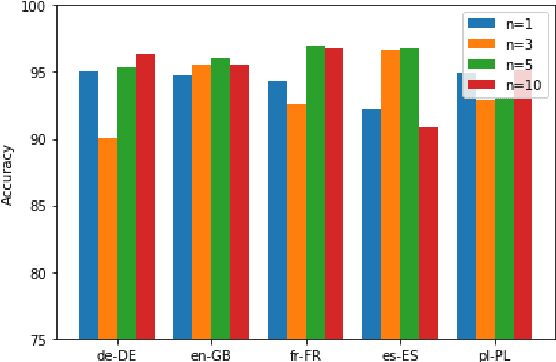
We present a systematic study on multilingual and cross-lingual intent detection from spoken data. The study leverages a new resource put forth in this work, termed MInDS-14, a first training and evaluation resource for the intent detection task with spoken data. It covers 14 intents extracted from a commercial system in the e-banking domain, associated with spoken examples in 14 diverse language varieties. Our key results indicate that combining machine translation models with state-of-the-art multilingual sentence encoders (e.g., LaBSE) can yield strong intent detectors in the majority of target languages covered in MInDS-14, and offer comparative analyses across different axes: e.g., zero-shot versus few-shot learning, translation direction, and impact of speech recognition. We see this work as an important step towards more inclusive development and evaluation of multilingual intent detectors from spoken data, in a much wider spectrum of languages compared to prior work.