 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$\textit{Dial BeInfo for Faithfulness}$: Improving Factuality of Information-Seeking Dialogue via Behavioural Fine-Tuning
Nov 16, 2023



Factuality is a crucial requirement in information seeking dialogue: the system should respond to the user's queries so that the responses are meaningful and aligned with the knowledge provided to the system. However, most modern large language models suffer from hallucinations, that is, they generate responses not supported by or contradicting the knowledge source. To mitigate the issue and increase faithfulness of information-seeking dialogue systems, we introduce BeInfo, a simple yet effective method that applies behavioural tuning to aid information-seeking dialogue. Relying on three standard datasets, we show that models tuned with BeInfo} become considerably more faithful to the knowledge source both for datasets and domains seen during BeInfo-tuning, as well as on unseen domains, when applied in a zero-shot manner. In addition, we show that the models with 3B parameters (e.g., Flan-T5) tuned with BeInfo demonstrate strong performance on data from real `production' conversations and outperform GPT4 when tuned on a limited amount of such realistic in-domain dialogues.
ConvFiT: Conversational Fine-Tuning of Pretrained Language Models
Sep 21, 2021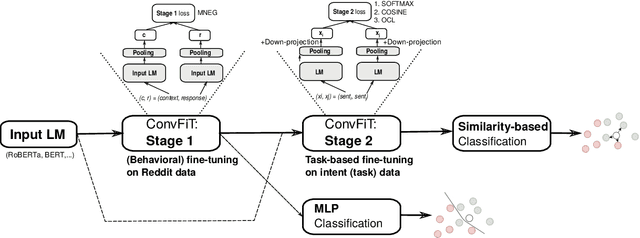

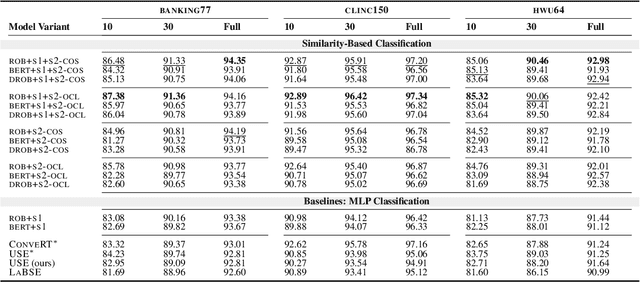
Transformer-based language models (LMs) pretrained on large text collections are proven to store a wealth of semantic knowledge. However, 1) they are not effective as sentence encoders when used off-the-shelf, and 2) thus typically lag behind conversationally pretrained (e.g., via response selection) encoders on conversational tasks such as intent detection (ID). In this work, we propose ConvFiT, a simple and efficient two-stage procedure which turns any pretrained LM into a universal conversational encoder (after Stage 1 ConvFiT-ing) and task-specialised sentence encoder (after Stage 2). We demonstrate that 1) full-blown conversational pretraining is not required, and that LMs can be quickly transformed into effective conversational encoders with much smaller amounts of unannotated data; 2) pretrained LMs can be fine-tuned into task-specialised sentence encoders, optimised for the fine-grained semantics of a particular task. Consequently, such specialised sentence encoders allow for treating ID as a simple semantic similarity task based on interpretable nearest neighbours retrieval. We validate the robustness and versatility of the ConvFiT framework with such similarity-based inference on the standard ID evaluation sets: ConvFiT-ed LMs achieve state-of-the-art ID performance across the board, with particular gains in the most challenging, few-shot setups.
Multilingual and Cross-Lingual Intent Detection from Spoken Data
Apr 17, 2021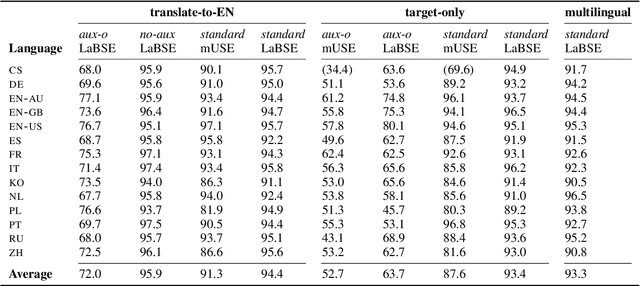
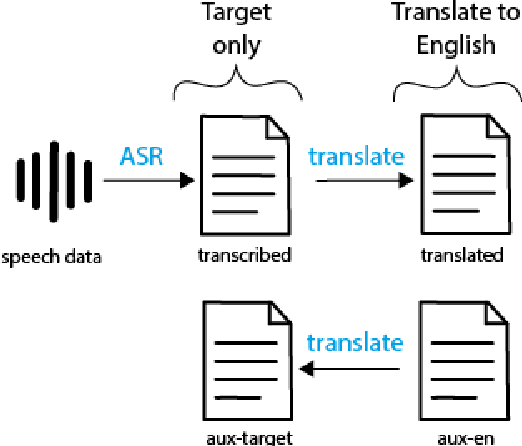
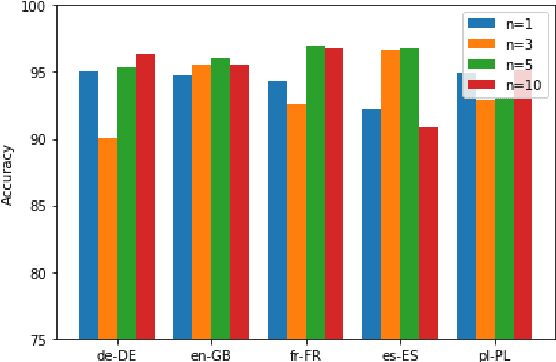
We present a systematic study on multilingual and cross-lingual intent detection from spoken data. The study leverages a new resource put forth in this work, termed MInDS-14, a first training and evaluation resource for the intent detection task with spoken data. It covers 14 intents extracted from a commercial system in the e-banking domain, associated with spoken examples in 14 diverse language varieties. Our key results indicate that combining machine translation models with state-of-the-art multilingual sentence encoders (e.g., LaBSE) can yield strong intent detectors in the majority of target languages covered in MInDS-14, and offer comparative analyses across different axes: e.g., zero-shot versus few-shot learning, translation direction, and impact of speech recognition. We see this work as an important step towards more inclusive development and evaluation of multilingual intent detectors from spoken data, in a much wider spectrum of languages compared to prior work.
PolyResponse: A Rank-based Approach to Task-Oriented Dialogue with Application in Restaurant Search and Booking
Sep 03, 2019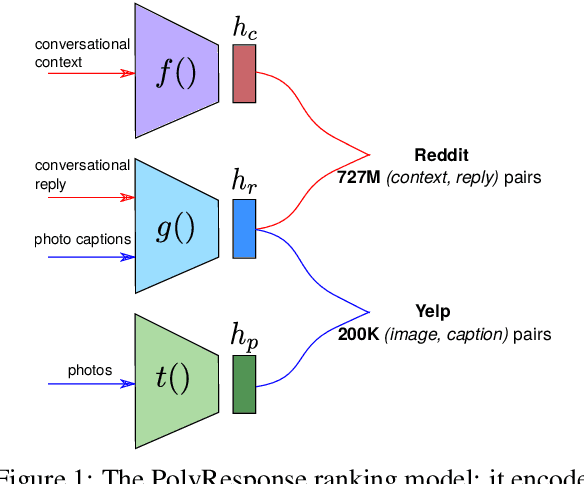
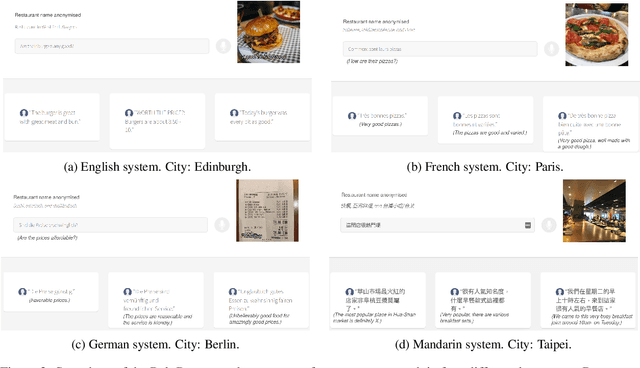
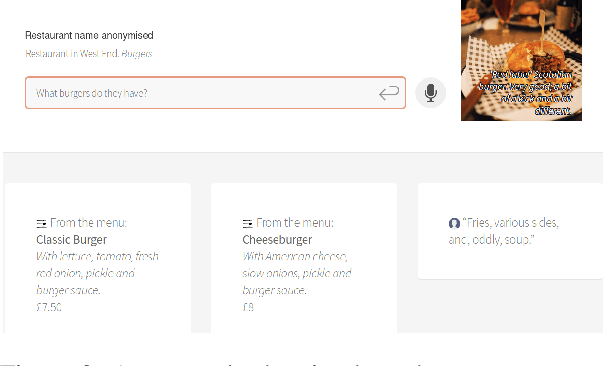
We present PolyResponse, a conversational search engine that supports task-oriented dialogue. It is a retrieval-based approach that bypasses the complex multi-component design of traditional task-oriented dialogue systems and the use of explicit semantics in the form of task-specific ontologies. The PolyResponse engine is trained on hundreds of millions of examples extracted from real conversations: it learns what responses are appropriate in different conversational contexts. It then ranks a large index of text and visual responses according to their similarity to the given context, and narrows down the list of relevant entities during the multi-turn conversation. We introduce a restaurant search and booking system powered by the PolyResponse engine, currently available in 8 different languages.
Training Neural Response Selection for Task-Oriented Dialogue Systems
Jun 07, 2019

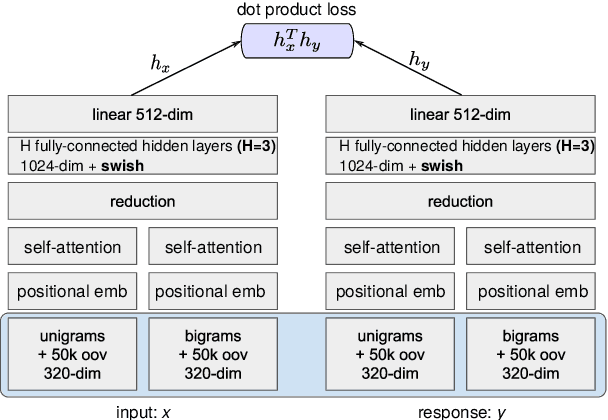

Despite their popularity in the chatbot literature, retrieval-based models have had modest impact on task-oriented dialogue systems, with the main obstacle to their application being the low-data regime of most task-oriented dialogue tasks. Inspired by the recent success of pretraining in language modelling, we propose an effective method for deploying response selection in task-oriented dialogue. To train response selection models for task-oriented dialogue tasks, we propose a novel method which: 1) pretrains the response selection model on large general-domain conversational corpora; and then 2) fine-tunes the pretrained model for the target dialogue domain, relying only on the small in-domain dataset to capture the nuances of the given dialogue domain. Our evaluation on six diverse application domains, ranging from e-commerce to banking, demonstrates the effectiveness of the proposed training method.
A Repository of Conversational Datasets
May 29, 2019

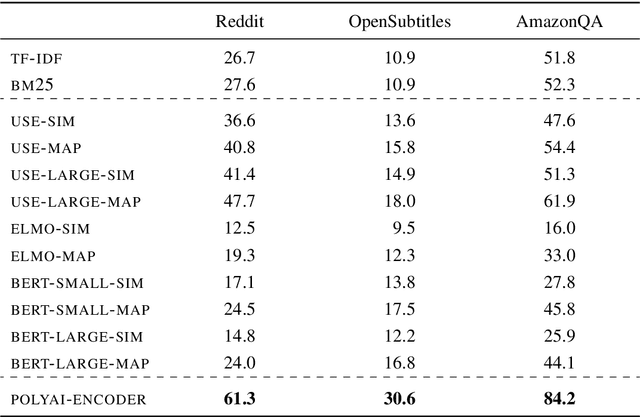

Progress in Machine Learning is often driven by the availability of large datasets, and consistent evaluation metrics for comparing modeling approaches. To this end, we present a repository of conversational datasets consisting of hundreds of millions of examples, and a standardised evaluation procedure for conversational response selection models using '1-of-100 accuracy'. The repository contains scripts that allow researchers to reproduce the standard datasets, or to adapt the pre-processing and data filtering steps to their needs. We introduce and evaluate several competitive baselines for conversational response selection, whose implementations are shared in the repository, as well as a neural encoder model that is trained on the entire training set.
MultiWOZ - A Large-Scale Multi-Domain Wizard-of-Oz Dataset for Task-Oriented Dialogue Modelling
Sep 29, 2018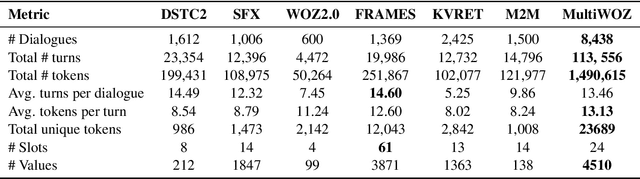


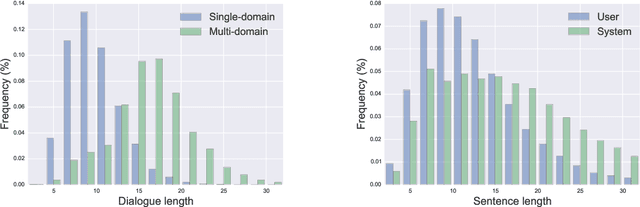
Even though machine learning has become the major scene in dialogue research community, the real breakthrough has been blocked by the scale of data available. To address this fundamental obstacle, we introduce the Multi-Domain Wizard-of-Oz dataset (MultiWOZ), a fully-labeled collection of human-human written conversations spanning over multiple domains and topics. At a size of $10$k dialogues, it is at least one order of magnitude larger than all previous annotated task-oriented corpora. The contribution of this work apart from the open-sourced dataset labelled with dialogue belief states and dialogue actions is two-fold: firstly, a detailed description of the data collection procedure along with a summary of data structure and analysis is provided. The proposed data-collection pipeline is entirely based on crowd-sourcing without the need of hiring professional annotators; secondly, a set of benchmark results of belief tracking, dialogue act and response generation is reported, which shows the usability of the data and sets a baseline for future studies.
Latent Topic Conversational Models
Sep 19, 2018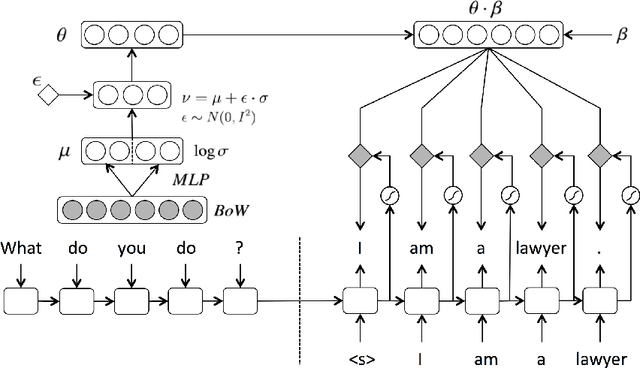
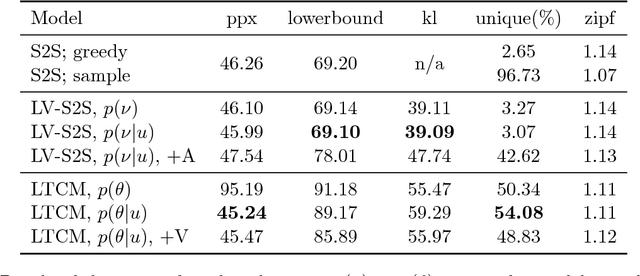

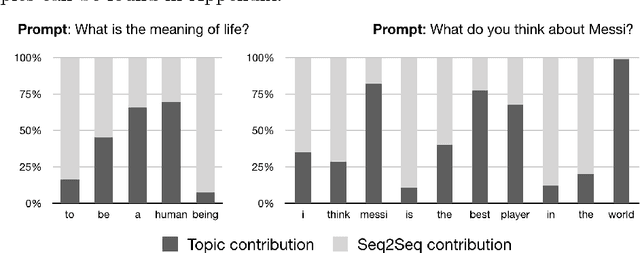
Latent variable models have been a preferred choice in conversational modeling compared to sequence-to-sequence (seq2seq) models which tend to generate generic and repetitive responses. Despite so, training latent variable models remains to be difficult. In this paper, we propose Latent Topic Conversational Model (LTCM) which augments seq2seq with a neural latent topic component to better guide response generation and make training easier. The neural topic component encodes information from the source sentence to build a global "topic" distribution over words, which is then consulted by the seq2seq model at each generation step. We study in details how the latent representation is learnt in both the vanilla model and LTCM. Our extensive experiments contribute to better understanding and training of conditional latent models for languages. Our results show that by sampling from the learnt latent representations, LTCM can generate diverse and interesting responses. In a subjective human evaluation, the judges also confirm that LTCM is the overall preferred option.
A Benchmarking Environment for Reinforcement Learning Based Task Oriented Dialogue Management
Apr 06, 2018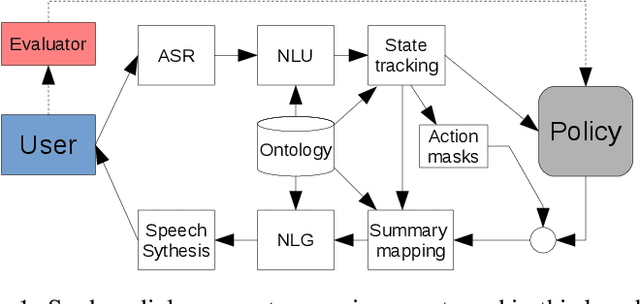
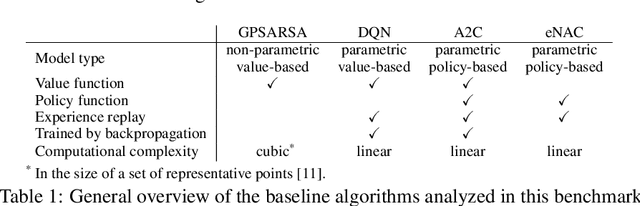

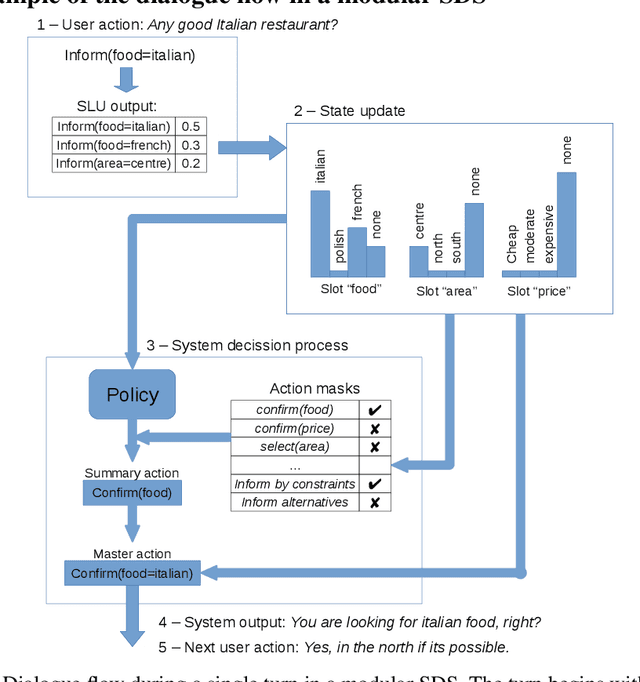
Dialogue assistants are rapidly becoming an indispensable daily aid. To avoid the significant effort needed to hand-craft the required dialogue flow, the Dialogue Management (DM) module can be cast as a continuous Markov Decision Process (MDP) and trained through Reinforcement Learning (RL). Several RL models have been investigated over recent years. However, the lack of a common benchmarking framework makes it difficult to perform a fair comparison between different models and their capability to generalise to different environments. Therefore, this paper proposes a set of challenging simulated environments for dialogue model development and evaluation. To provide some baselines, we investigate a number of representative parametric algorithms, namely deep reinforcement learning algorithms - DQN, A2C and Natural Actor-Critic and compare them to a non-parametric model, GP-SARSA. Both the environments and policy models are implemented using the publicly available PyDial toolkit and released on-line, in order to establish a testbed framework for further experiments and to facilitate experimental reproducibility.
Reward-Balancing for Statistical Spoken Dialogue Systems using Multi-objective Reinforcement Learning
Jul 19, 2017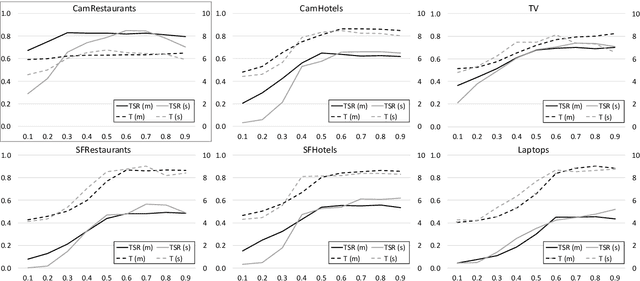
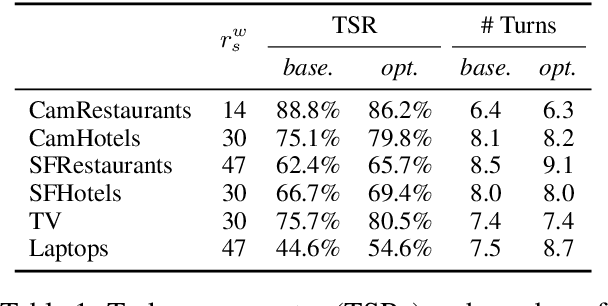
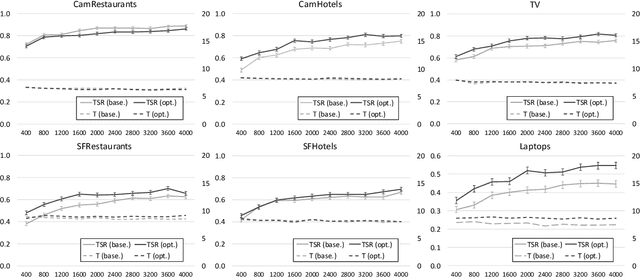
Reinforcement learning is widely used for dialogue policy optimization where the reward function often consists of more than one component, e.g., the dialogue success and the dialogue length. In this work, we propose a structured method for finding a good balance between these components by searching for the optimal reward component weighting. To render this search feasible, we use multi-objective reinforcement learning to significantly reduce the number of training dialogues required. We apply our proposed method to find optimized component weights for six domains and compare them to a default baseline.