 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Inflection Generation Using Neural Language Modeling
Dec 03, 2019
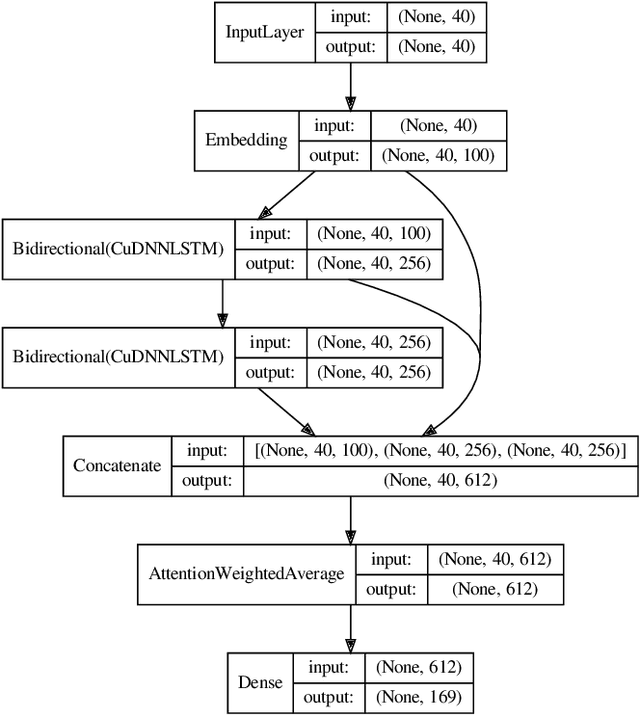
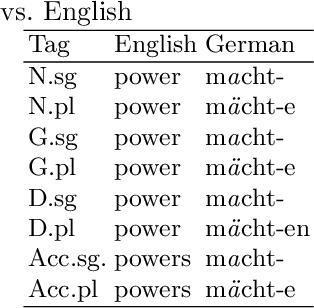
The use of Deep Neural Network architectures for Language Modeling has recently seen a tremendous increase in interest in the field of NLP with the advent of transfer learning and the shift in focus from rule-based and predictive models (supervised learning) to generative or unsupervised models to solve the long-standing problems in NLP like Information Extraction or Question Answering. While this shift has worked greatly for languages lacking in inflectional morphology, such as English, challenges still arise when trying to build similar systems for morphologically-rich languages, since their individual words shift forms in context more often. In this paper we investigate the extent to which these new unsupervised or generative techniques can serve to alleviate the type-token ratio disparity in morphologically rich languages. We apply an off-the-shelf neural language modeling library to the newly introduced task of unsupervised inflection generation in the nominal domain of three morphologically rich languages: Romanian, German, and Finnish. We show that this neural language model architecture can successfully generate the full inflection table of nouns without needing any pre-training on large, wikipedia-sized corpora, as long as the model is shown enough inflection examples. In fact, our experiments show that pre-training hinders the generation performance.
Addressing Objects and Their Relations: The Conversational Entity Dialogue Model
Jan 05, 2019



Statistical spoken dialogue systems usually rely on a single- or multi-domain dialogue model that is restricted in its capabilities of modelling complex dialogue structures, e.g., relations. In this work, we propose a novel dialogue model that is centred around entities and is able to model relations as well as multiple entities of the same type. We demonstrate in a prototype implementation benefits of relation modelling on the dialogue level and show that a trained policy using these relations outperforms the multi-domain baseline. Furthermore, we show that by modelling the relations on the dialogue level, the system is capable of processing relations present in the user input and even learns to address them in the system response.
Nearly Zero-Shot Learning for Semantic Decoding in Spoken Dialogue Systems
Jun 21, 2018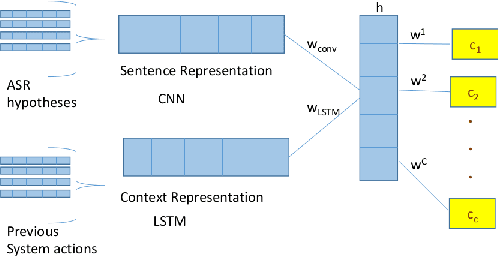
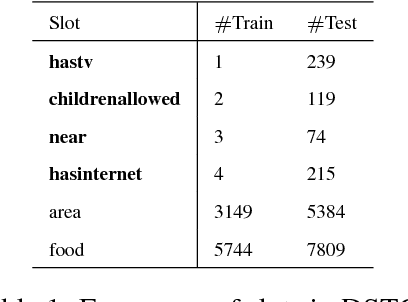
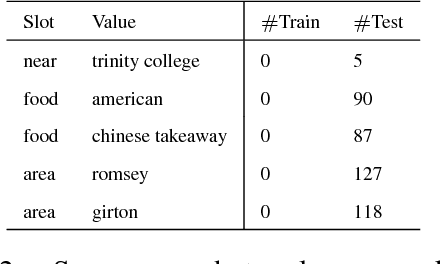

This paper presents two ways of dealing with scarce data in semantic decoding using N-Best speech recognition hypotheses. First, we learn features by using a deep learning architecture in which the weights for the unknown and known categories are jointly optimised. Second, an unsupervised method is used for further tuning the weights. Sharing weights injects prior knowledge to unknown categories. The unsupervised tuning (i.e. the risk minimisation) improves the F-Measure when recognising nearly zero-shot data on the DSTC3 corpus. This unsupervised method can be applied subject to two assumptions: the rank of the class marginal is assumed to be known and the class-conditional scores of the classifier are assumed to follow a Gaussian distribution.
A Benchmarking Environment for Reinforcement Learning Based Task Oriented Dialogue Management
Apr 06, 2018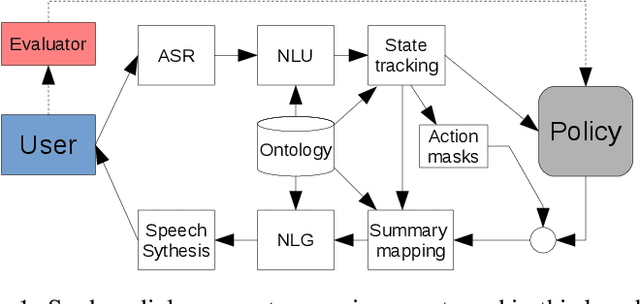
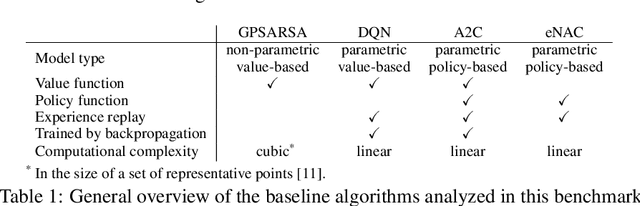

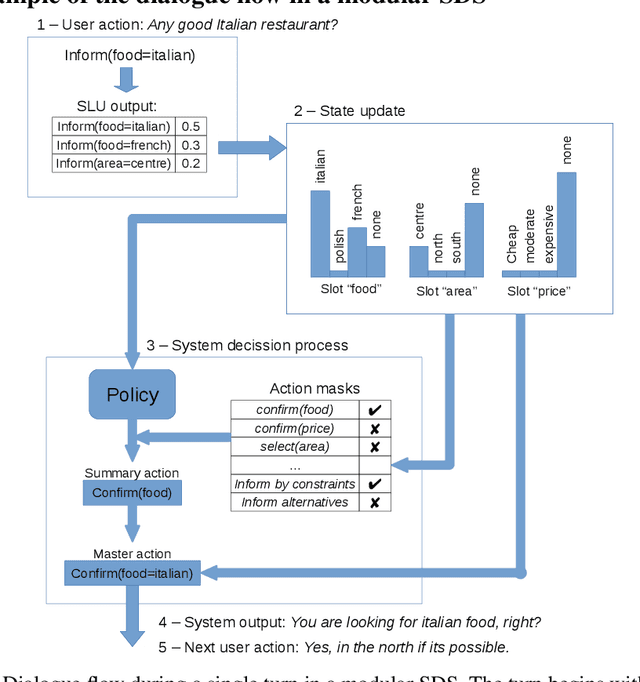
Dialogue assistants are rapidly becoming an indispensable daily aid. To avoid the significant effort needed to hand-craft the required dialogue flow, the Dialogue Management (DM) module can be cast as a continuous Markov Decision Process (MDP) and trained through Reinforcement Learning (RL). Several RL models have been investigated over recent years. However, the lack of a common benchmarking framework makes it difficult to perform a fair comparison between different models and their capability to generalise to different environments. Therefore, this paper proposes a set of challenging simulated environments for dialogue model development and evaluation. To provide some baselines, we investigate a number of representative parametric algorithms, namely deep reinforcement learning algorithms - DQN, A2C and Natural Actor-Critic and compare them to a non-parametric model, GP-SARSA. Both the environments and policy models are implemented using the publicly available PyDial toolkit and released on-line, in order to establish a testbed framework for further experiments and to facilitate experimental reproducibility.
Reward-Balancing for Statistical Spoken Dialogue Systems using Multi-objective Reinforcement Learning
Jul 19, 2017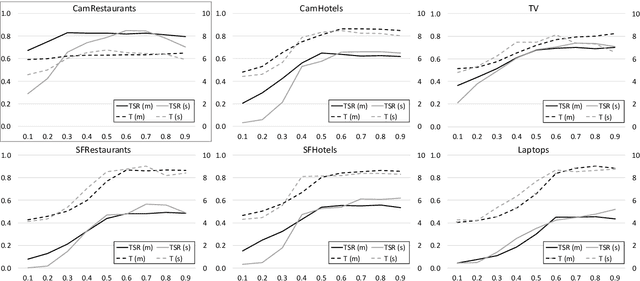
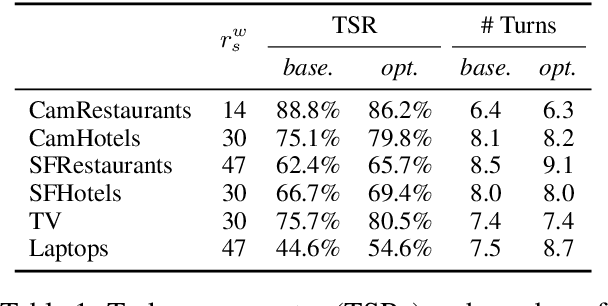
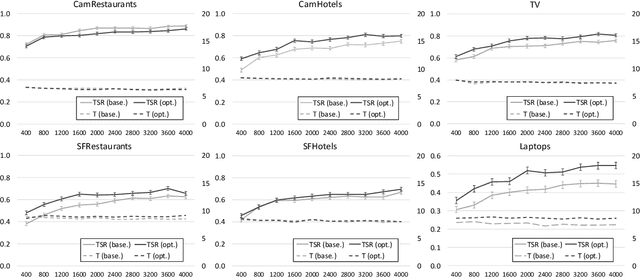
Reinforcement learning is widely used for dialogue policy optimization where the reward function often consists of more than one component, e.g., the dialogue success and the dialogue length. In this work, we propose a structured method for finding a good balance between these components by searching for the optimal reward component weighting. To render this search feasible, we use multi-objective reinforcement learning to significantly reduce the number of training dialogues required. We apply our proposed method to find optimized component weights for six domains and compare them to a default baseline.
Sample-efficient Actor-Critic Reinforcement Learning with Supervised Data for Dialogue Management
Jul 05, 2017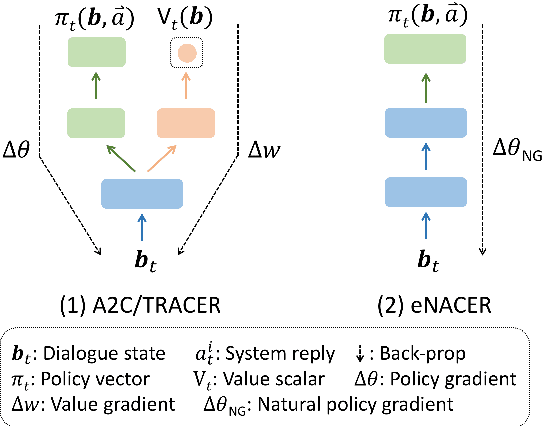
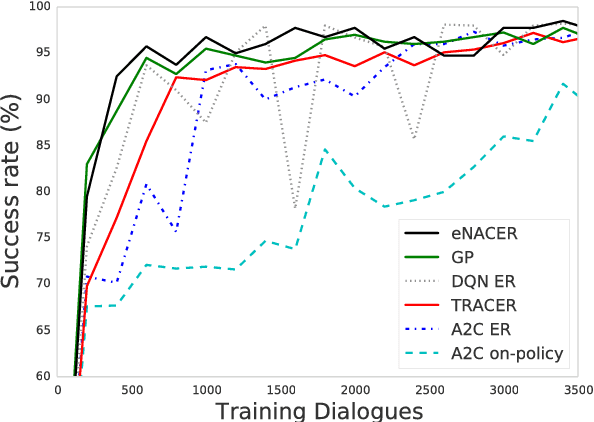
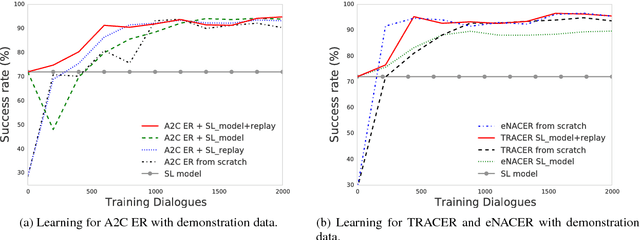
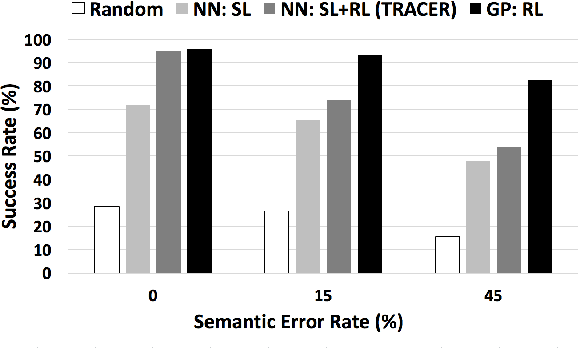
Deep reinforcement learning (RL) methods have significant potential for dialogue policy optimisation. However, they suffer from a poor performance in the early stages of learning. This is especially problematic for on-line learning with real users. Two approaches are introduced to tackle this problem. Firstly, to speed up the learning process, two sample-efficient neural networks algorithms: trust region actor-critic with experience replay (TRACER) and episodic natural actor-critic with experience replay (eNACER) are presented. For TRACER, the trust region helps to control the learning step size and avoid catastrophic model changes. For eNACER, the natural gradient identifies the steepest ascent direction in policy space to speed up the convergence. Both models employ off-policy learning with experience replay to improve sample-efficiency. Secondly, to mitigate the cold start issue, a corpus of demonstration data is utilised to pre-train the models prior to on-line reinforcement learning. Combining these two approaches, we demonstrate a practical approach to learn deep RL-based dialogue policies and demonstrate their effectiveness in a task-oriented information seeking domain.
Morph-fitting: Fine-Tuning Word Vector Spaces with Simple Language-Specific Rules
Jun 01, 2017
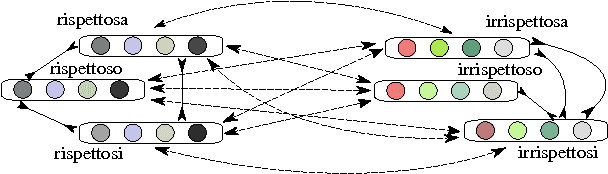

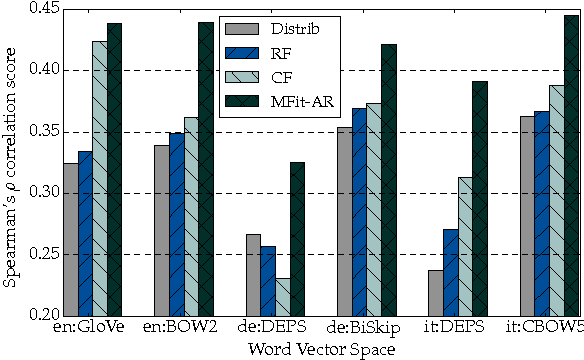
Morphologically rich languages accentuate two properties of distributional vector space models: 1) the difficulty of inducing accurate representations for low-frequency word forms; and 2) insensitivity to distinct lexical relations that have similar distributional signatures. These effects are detrimental for language understanding systems, which may infer that 'inexpensive' is a rephrasing for 'expensive' or may not associate 'acquire' with 'acquires'. In this work, we propose a novel morph-fitting procedure which moves past the use of curated semantic lexicons for improving distributional vector spaces. Instead, our method injects morphological constraints generated using simple language-specific rules, pulling inflectional forms of the same word close together and pushing derivational antonyms far apart. In intrinsic evaluation over four languages, we show that our approach: 1) improves low-frequency word estimates; and 2) boosts the semantic quality of the entire word vector collection. Finally, we show that morph-fitted vectors yield large gains in the downstream task of dialogue state tracking, highlighting the importance of morphology for tackling long-tail phenomena in language understanding tasks.
Semantic Specialisation of Distributional Word Vector Spaces using Monolingual and Cross-Lingual Constraints
Jun 01, 2017



We present Attract-Repel, an algorithm for improving the semantic quality of word vectors by injecting constraints extracted from lexical resources. Attract-Repel facilitates the use of constraints from mono- and cross-lingual resources, yielding semantically specialised cross-lingual vector spaces. Our evaluation shows that the method can make use of existing cross-lingual lexicons to construct high-quality vector spaces for a plethora of different languages, facilitating semantic transfer from high- to lower-resource ones. The effectiveness of our approach is demonstrated with state-of-the-art results on semantic similarity datasets in six languages. We next show that Attract-Repel-specialised vectors boost performance in the downstream task of dialogue state tracking (DST) across multiple languages. Finally, we show that cross-lingual vector spaces produced by our algorithm facilitate the training of multilingual DST models, which brings further performance improvements.
Latent Intention Dialogue Models
May 29, 2017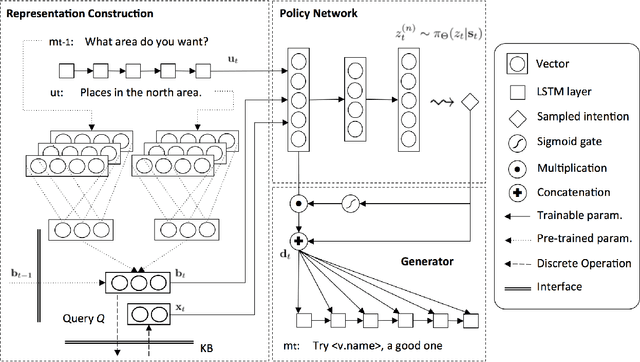

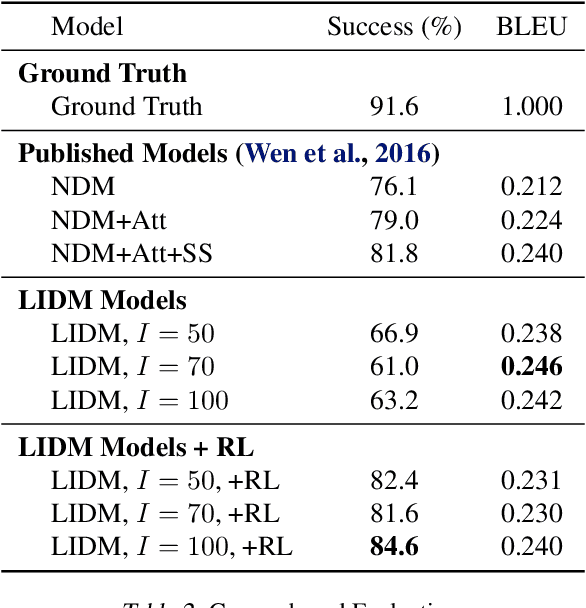
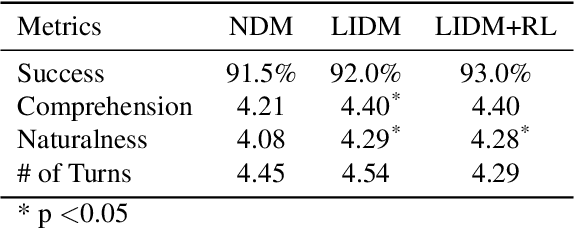
Developing a dialogue agent that is capable of making autonomous decisions and communicating by natural language is one of the long-term goals of machine learning research. Traditional approaches either rely on hand-crafting a small state-action set for applying reinforcement learning that is not scalable or constructing deterministic models for learning dialogue sentences that fail to capture natural conversational variability. In this paper, we propose a Latent Intention Dialogue Model (LIDM) that employs a discrete latent variable to learn underlying dialogue intentions in the framework of neural variational inference. In a goal-oriented dialogue scenario, these latent intentions can be interpreted as actions guiding the generation of machine responses, which can be further refined autonomously by reinforcement learning. The experimental evaluation of LIDM shows that the model out-performs published benchmarks for both corpus-based and human evaluation, demonstrating the effectiveness of discrete latent variable models for learning goal-oriented dialogues.
A Network-based End-to-End Trainable Task-oriented Dialogue System
Apr 24, 2017Teaching machines to accomplish tasks by conversing naturally with humans is challenging. Currently, developing task-oriented dialogue systems requires creating multiple components and typically this involves either a large amount of handcrafting, or acquiring costly labelled datasets to solve a statistical learning problem for each component. In this work we introduce a neural network-based text-in, text-out end-to-end trainable goal-oriented dialogue system along with a new way of collecting dialogue data based on a novel pipe-lined Wizard-of-Oz framework. This approach allows us to develop dialogue systems easily and without making too many assumptions about the task at hand. The results show that the model can converse with human subjects naturally whilst helping them to accomplish tasks in a restaurant search domain.