 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Inflection Generation Using Neural Language Modeling
Paper and Code
Dec 03, 2019
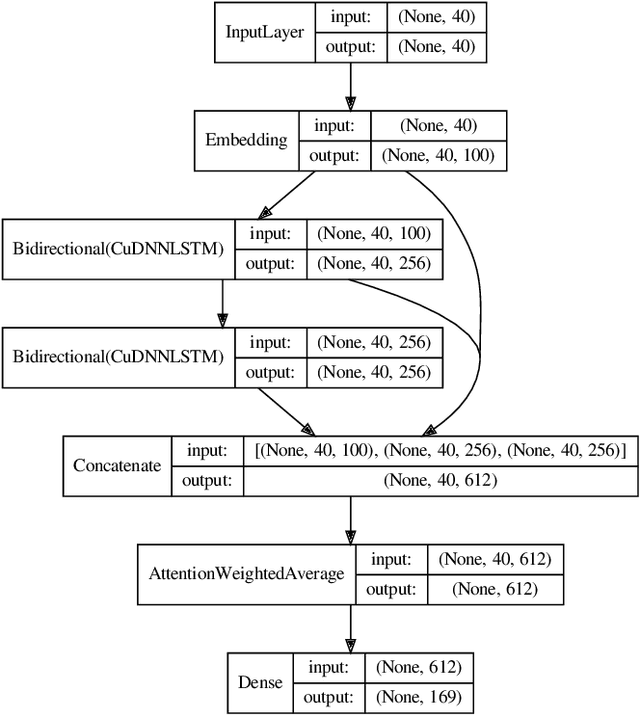
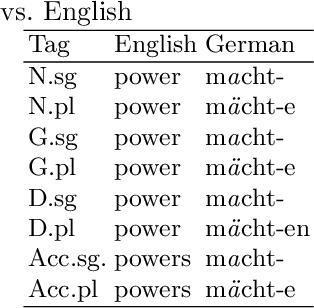
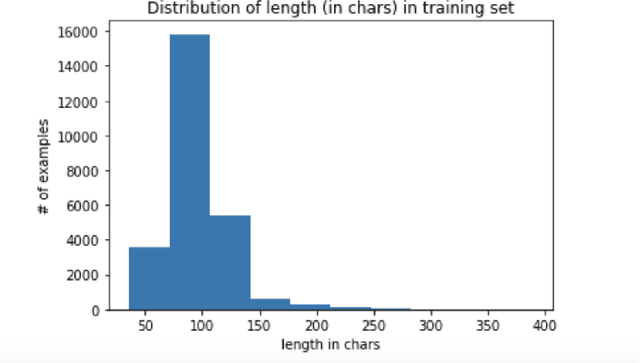
The use of Deep Neural Network architectures for Language Modeling has recently seen a tremendous increase in interest in the field of NLP with the advent of transfer learning and the shift in focus from rule-based and predictive models (supervised learning) to generative or unsupervised models to solve the long-standing problems in NLP like Information Extraction or Question Answering. While this shift has worked greatly for languages lacking in inflectional morphology, such as English, challenges still arise when trying to build similar systems for morphologically-rich languages, since their individual words shift forms in context more often. In this paper we investigate the extent to which these new unsupervised or generative techniques can serve to alleviate the type-token ratio disparity in morphologically rich languages. We apply an off-the-shelf neural language modeling library to the newly introduced task of unsupervised inflection generation in the nominal domain of three morphologically rich languages: Romanian, German, and Finnish. We show that this neural language model architecture can successfully generate the full inflection table of nouns without needing any pre-training on large, wikipedia-sized corpora, as long as the model is shown enough inflection examples. In fact, our experiments show that pre-training hinders the generation performance.