 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Inflection Generation Using Neural Language Modeling
Dec 03, 2019
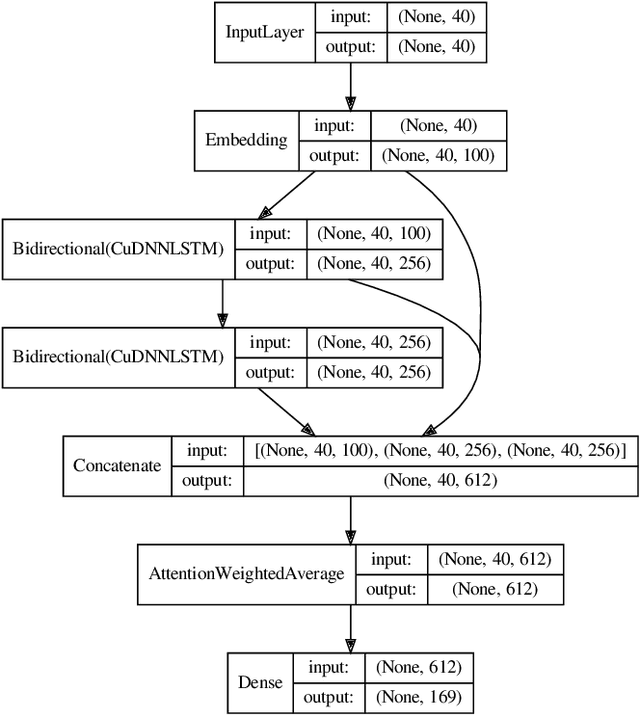
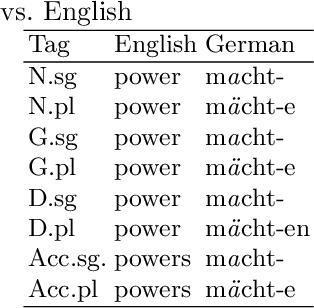
The use of Deep Neural Network architectures for Language Modeling has recently seen a tremendous increase in interest in the field of NLP with the advent of transfer learning and the shift in focus from rule-based and predictive models (supervised learning) to generative or unsupervised models to solve the long-standing problems in NLP like Information Extraction or Question Answering. While this shift has worked greatly for languages lacking in inflectional morphology, such as English, challenges still arise when trying to build similar systems for morphologically-rich languages, since their individual words shift forms in context more often. In this paper we investigate the extent to which these new unsupervised or generative techniques can serve to alleviate the type-token ratio disparity in morphologically rich languages. We apply an off-the-shelf neural language modeling library to the newly introduced task of unsupervised inflection generation in the nominal domain of three morphologically rich languages: Romanian, German, and Finnish. We show that this neural language model architecture can successfully generate the full inflection table of nouns without needing any pre-training on large, wikipedia-sized corpora, as long as the model is shown enough inflection examples. In fact, our experiments show that pre-training hinders the generation performance.
Exploring the Use of Text Classification in the Legal Domain
Oct 25, 2017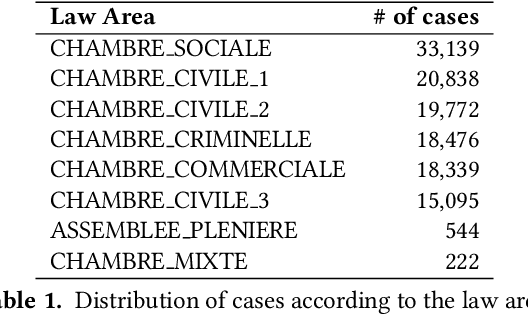
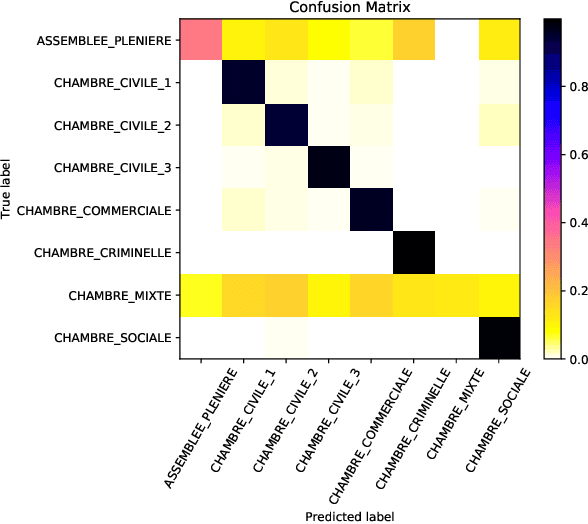
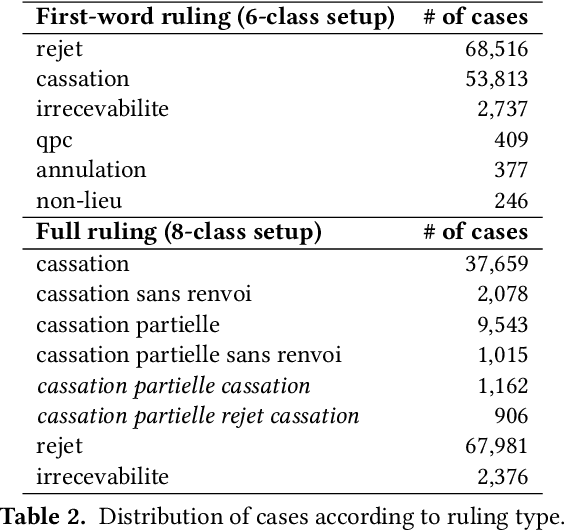
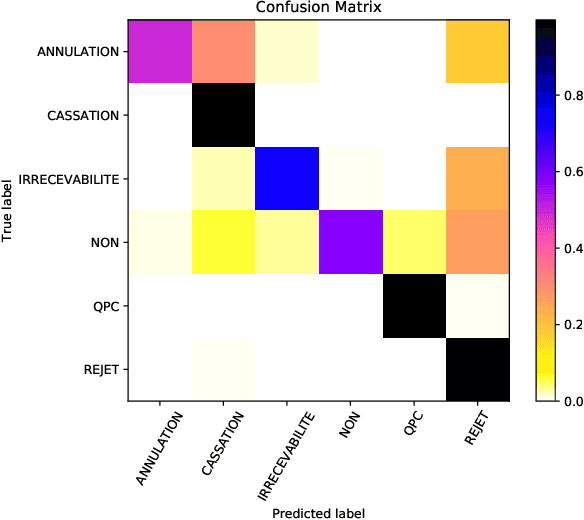
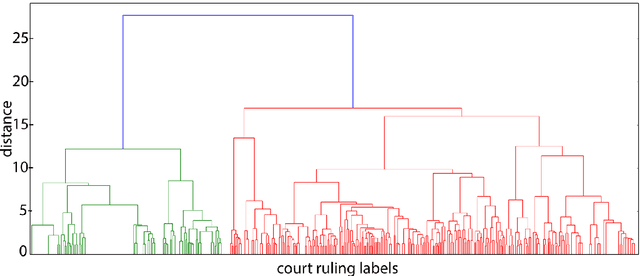
In this paper, we investigate the application of text classification methods to support law professionals. We present several experiments applying machine learning techniques to predict with high accuracy the ruling of the French Supreme Court and the law area to which a case belongs to. We also investigate the influence of the time period in which a ruling was made on the form of the case description and the extent to which we need to mask information in a full case ruling to automatically obtain training and test data that resembles case descriptions. We developed a mean probability ensemble system combining the output of multiple SVM classifiers. We report results of 98% average F1 score in predicting a case ruling, 96% F1 score for predicting the law area of a case, and 87.07% F1 score on estimating the date of a ruling.
Predicting the Law Area and Decisions of French Supreme Court Cases
Aug 04, 2017
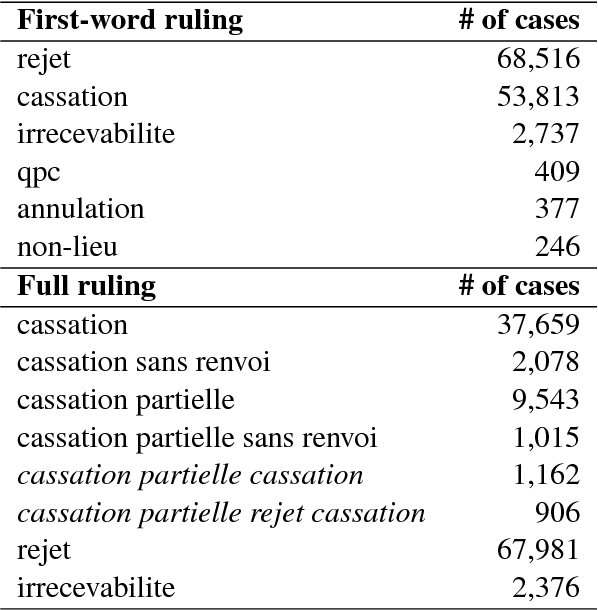
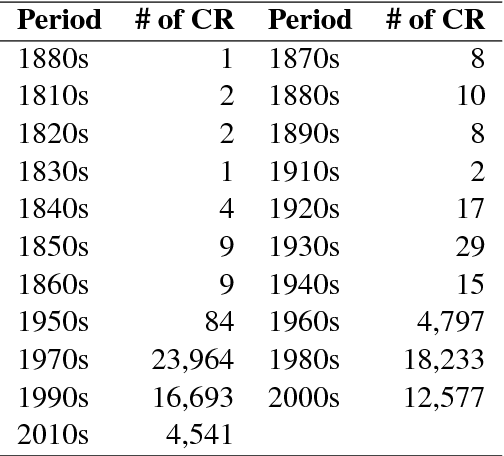
In this paper, we investigate the application of text classification methods to predict the law area and the decision of cases judged by the French Supreme Court. We also investigate the influence of the time period in which a ruling was made over the textual form of the case description and the extent to which it is necessary to mask the judge's motivation for a ruling to emulate a real-world test scenario. We report results of 96% f1 score in predicting a case ruling, 90% f1 score in predicting the law area of a case, and 75.9% f1 score in estimating the time span when a ruling has been issued using a linear Support Vector Machine (SVM) classifier trained on lexical features.