 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models for Mental Health: A Multilingual Evaluation
Feb 02, 2026Large Language Models (LLMs) have remarkable capabilities across NLP tasks. However, their performance in multilingual contexts, especially within the mental health domain, has not been thoroughly explored. In this paper, we evaluate proprietary and open-source LLMs on eight mental health datasets in various languages, as well as their machine-translated (MT) counterparts. We compare LLM performance in zero-shot, few-shot, and fine-tuned settings against conventional NLP baselines that do not employ LLMs. In addition, we assess translation quality across language families and typologies to understand its influence on LLM performance. Proprietary LLMs and fine-tuned open-source LLMs achieve competitive F1 scores on several datasets, often surpassing state-of-the-art results. However, performance on MT data is generally lower, and the extent of this decline varies by language and typology. This variation highlights both the strengths of LLMs in handling mental health tasks in languages other than English and their limitations when translation quality introduces structural or lexical mismatches.
Exploring the Performance of Large Language Models on Subjective Span Identification Tasks
Jan 02, 2026Identifying relevant text spans is important for several downstream tasks in NLP, as it contributes to model explainability. While most span identification approaches rely on relatively smaller pre-trained language models like BERT, a few recent approaches have leveraged the latest generation of Large Language Models (LLMs) for the task. Current work has focused on explicit span identification like Named Entity Recognition (NER), while more subjective span identification with LLMs in tasks like Aspect-based Sentiment Analysis (ABSA) has been underexplored. In this paper, we fill this important gap by presenting an evaluation of the performance of various LLMs on text span identification in three popular tasks, namely sentiment analysis, offensive language identification, and claim verification. We explore several LLM strategies like instruction tuning, in-context learning, and chain of thought. Our results indicate underlying relationships within text aid LLMs in identifying precise text spans.
TigerCoder: A Novel Suite of LLMs for Code Generation in Bangla
Sep 11, 2025Despite being the 5th most spoken language, Bangla remains underrepresented in Large Language Models (LLMs), particularly for code generation. This primarily stems from the scarcity of high-quality data to pre-train and/or finetune such models. Hence, we introduce the first dedicated family of Code LLMs for Bangla (1B & 9B). We offer three major contributions: (1) a comprehensive Bangla code instruction datasets for programming domain adaptation; (2) MBPP-Bangla, an evaluation benchmark for Bangla code generation; and (3) the TigerCoder-family of Code LLMs, achieving significant ~11-18% performance gains at Pass@1 over existing multilingual and general-purpose Bangla LLMs. Our findings show that curated, high-quality datasets can overcome limitations of smaller models for low-resource languages. We open-source all resources to advance further Bangla LLM research.
Narrate2Nav: Real-Time Visual Navigation with Implicit Language Reasoning in Human-Centric Environments
Jun 17, 2025Large Vision-Language Models (VLMs) have demonstrated potential in enhancing mobile robot navigation in human-centric environments by understanding contextual cues, human intentions, and social dynamics while exhibiting reasoning capabilities. However, their computational complexity and limited sensitivity to continuous numerical data impede real-time performance and precise motion control. To this end, we propose Narrate2Nav, a novel real-time vision-action model that leverages a novel self-supervised learning framework based on the Barlow Twins redundancy reduction loss to embed implicit natural language reasoning, social cues, and human intentions within a visual encoder-enabling reasoning in the model's latent space rather than token space. The model combines RGB inputs, motion commands, and textual signals of scene context during training to bridge from robot observations to low-level motion commands for short-horizon point-goal navigation during deployment. Extensive evaluation of Narrate2Nav across various challenging scenarios in both offline unseen dataset and real-world experiments demonstrates an overall improvement of 52.94 percent and 41.67 percent, respectively, over the next best baseline. Additionally, qualitative comparative analysis of Narrate2Nav's visual encoder attention map against four other baselines demonstrates enhanced attention to navigation-critical scene elements, underscoring its effectiveness in human-centric navigation tasks.
A Survey on Multilingual Mental Disorders Detection from Social Media Data
May 21, 2025The increasing prevalence of mental health disorders globally highlights the urgent need for effective digital screening methods that can be used in multilingual contexts. Most existing studies, however, focus on English data, overlooking critical mental health signals that may be present in non-English texts. To address this important gap, we present the first survey on the detection of mental health disorders using multilingual social media data. We investigate the cultural nuances that influence online language patterns and self-disclosure behaviors, and how these factors can impact the performance of NLP tools. Additionally, we provide a comprehensive list of multilingual data collections that can be used for developing NLP models for mental health screening. Our findings can inform the design of effective multilingual mental health screening tools that can meet the needs of diverse populations, ultimately improving mental health outcomes on a global scale.
SCALAR: A Part-of-speech Tagger for Identifiers
Apr 23, 2025The paper presents the Source Code Analysis and Lexical Annotation Runtime (SCALAR), a tool specialized for mapping (annotating) source code identifier names to their corresponding part-of-speech tag sequence (grammar pattern). SCALAR's internal model is trained using scikit-learn's GradientBoostingClassifier in conjunction with a manually-curated oracle of identifier names and their grammar patterns. This specializes the tagger to recognize the unique structure of the natural language used by developers to create all types of identifiers (e.g., function names, variable names etc.). SCALAR's output is compared with a previous version of the tagger, as well as a modern off-the-shelf part-of-speech tagger to show how it improves upon other taggers' output for annotating identifiers. The code is available on Github
Subasa -- Adapting Language Models for Low-resourced Offensive Language Detection in Sinhala
Apr 02, 2025
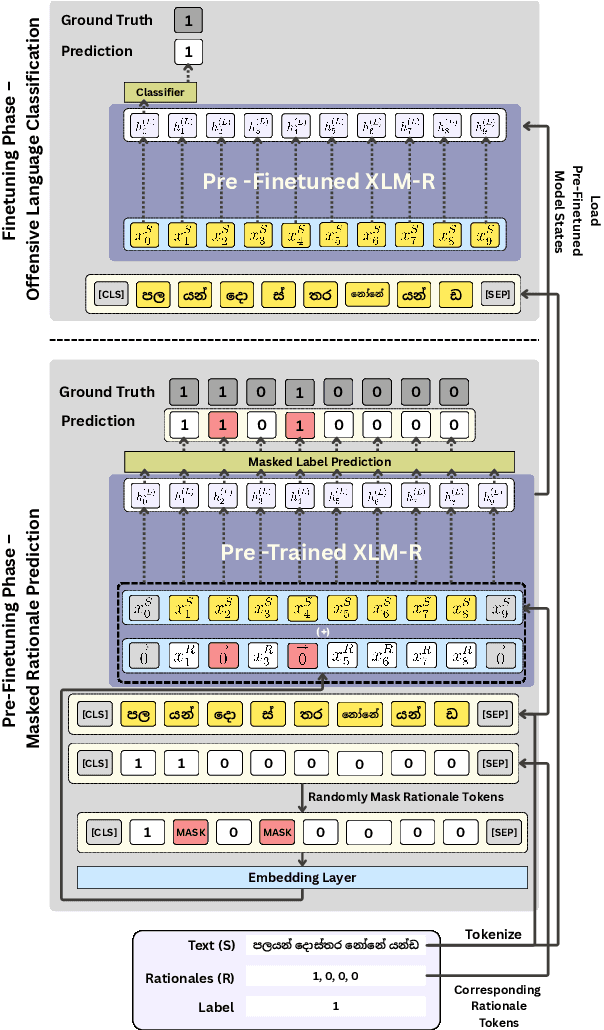
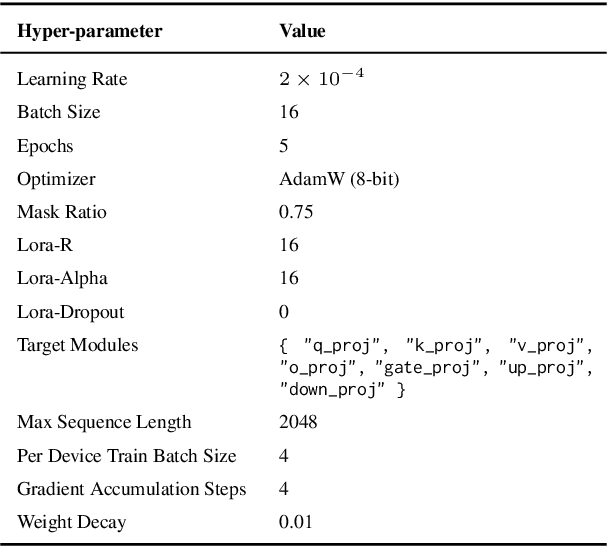
Accurate detection of offensive language is essential for a number of applications related to social media safety. There is a sharp contrast in performance in this task between low and high-resource languages. In this paper, we adapt fine-tuning strategies that have not been previously explored for Sinhala in the downstream task of offensive language detection. Using this approach, we introduce four models: "Subasa-XLM-R", which incorporates an intermediate Pre-Finetuning step using Masked Rationale Prediction. Two variants of "Subasa-Llama" and "Subasa-Mistral", are fine-tuned versions of Llama (3.2) and Mistral (v0.3), respectively, with a task-specific strategy. We evaluate our models on the SOLD benchmark dataset for Sinhala offensive language detection. All our models outperform existing baselines. Subasa-XLM-R achieves the highest Macro F1 score (0.84) surpassing state-of-the-art large language models like GPT-4o when evaluated on the same SOLD benchmark dataset under zero-shot settings. The models and code are publicly available.
Datasets for Depression Modeling in Social Media: An Overview
Mar 27, 2025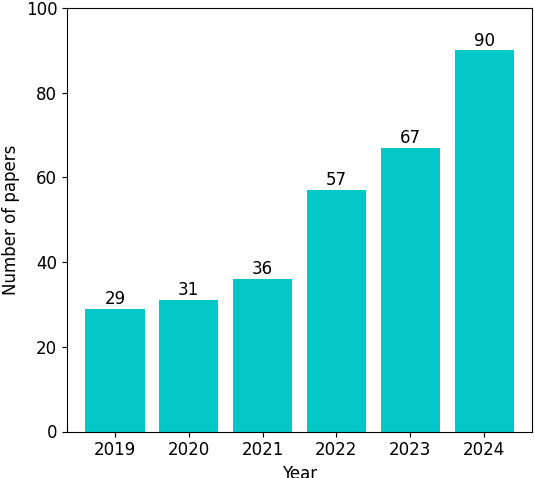
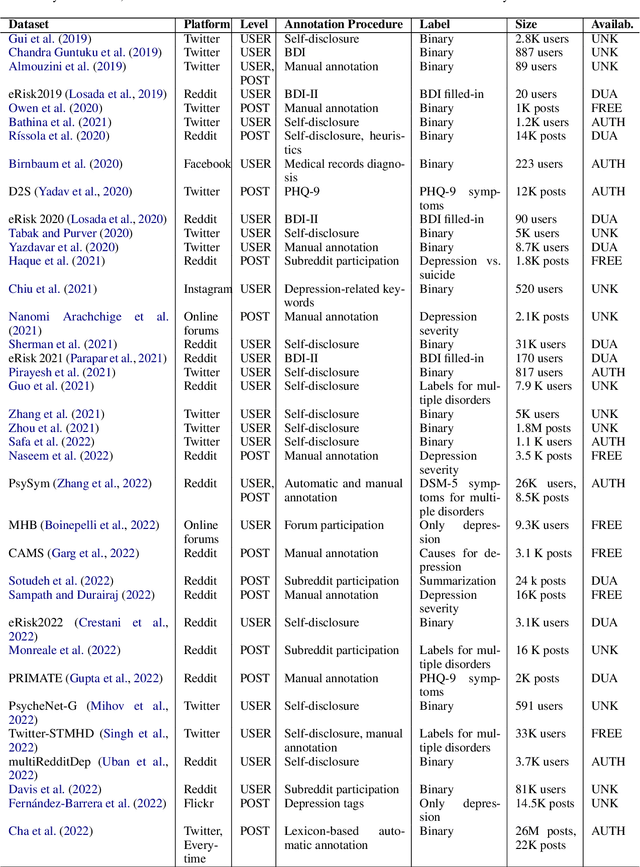
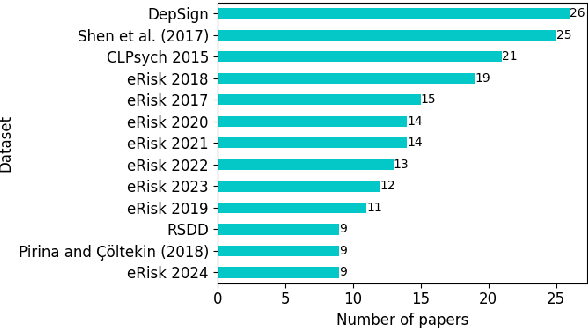
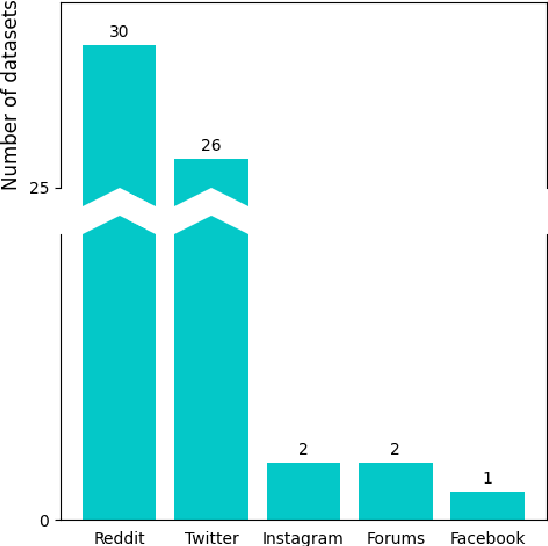
Depression is the most common mental health disorder, and its prevalence increased during the COVID-19 pandemic. As one of the most extensively researched psychological conditions, recent research has increasingly focused on leveraging social media data to enhance traditional methods of depression screening. This paper addresses the growing interest in interdisciplinary research on depression, and aims to support early-career researchers by providing a comprehensive and up-to-date list of datasets for analyzing and predicting depression through social media data. We present an overview of datasets published between 2019 and 2024. We also make the comprehensive list of datasets available online as a continuously updated resource, with the hope that it will facilitate further interdisciplinary research into the linguistic expressions of depression on social media.
TigerLLM -- A Family of Bangla Large Language Models
Mar 14, 2025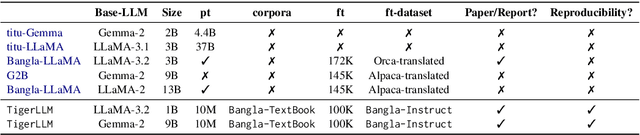

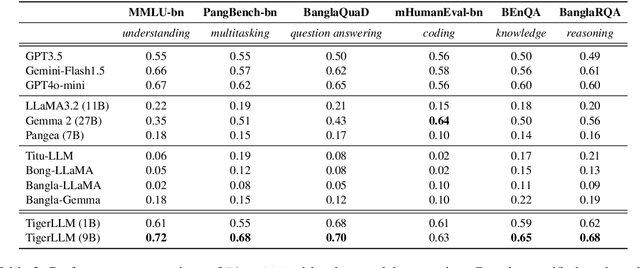
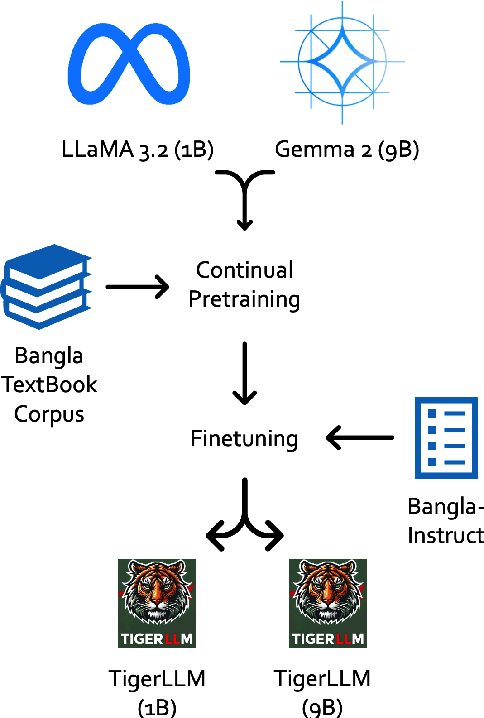
The development of Large Language Models (LLMs) remains heavily skewed towards English and a few other high-resource languages. This linguistic disparity is particularly evident for Bangla - the 5th most spoken language. A few initiatives attempted to create open-source Bangla LLMs with performance still behind high-resource languages and limited reproducibility. To address this gap, we introduce TigerLLM - a family of Bangla LLMs. Our results demonstrate that these models surpass all open-source alternatives and also outperform larger proprietary models like GPT3.5 across standard benchmarks, establishing TigerLLM as the new baseline for future Bangla language modeling.
Code LLMs: A Taxonomy-based Survey
Dec 11, 2024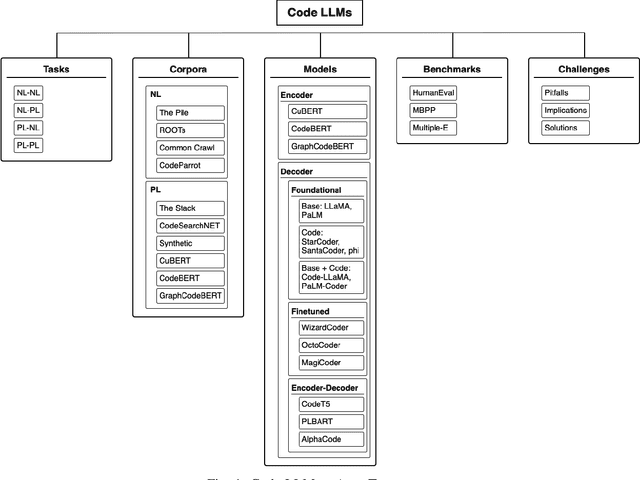

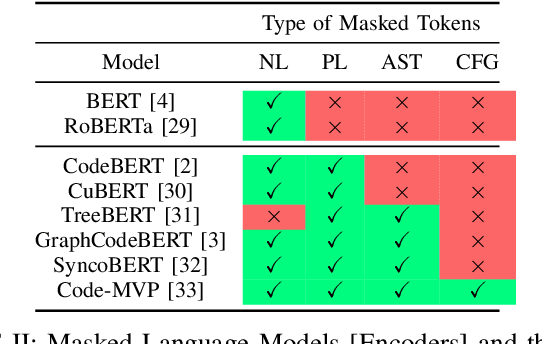
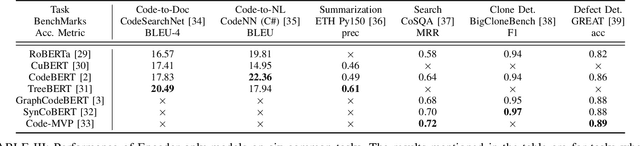
Large language models (LLMs) have demonstrated remarkable capabilities across various NLP tasks and have recently expanded their impact to coding tasks, bridging the gap between natural languages (NL) and programming languages (PL). This taxonomy-based survey provides a comprehensive analysis of LLMs in the NL-PL domain, investigating how these models are utilized in coding tasks and examining their methodologies, architectures, and training processes. We propose a taxonomy-based framework that categorizes relevant concepts, providing a unified classification system to facilitate a deeper understanding of this rapidly evolving field. This survey offers insights into the current state and future directions of LLMs in coding tasks, including their applications and limitations.