 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Taxonomy of Programming Languages for Code Generation
Mar 31, 2026The world's 7,000+ languages vary widely in the availability of resources for NLP, motivating efforts to systematically categorize them by their degree of resourcefulness (Joshi et al., 2020). A similar disparity exists among programming languages (PLs); however, no resource-tier taxonomy has been established for code. As large language models (LLMs) grow increasingly capable of generating code, such a taxonomy becomes essential. To fill this gap, we present the first reproducible PL resource classification, grouping 646 languages into four tiers. We show that only 1.9% of languages (Tier 3, High) account for 74.6% of all tokens in seven major corpora, while 71.7% of languages (Tier 0, Scarce) contribute just 1.0%. Statistical analyses of within-tier inequality, dispersion, and distributional skew confirm that this imbalance is both extreme and systematic. Our results provide a principled framework for dataset curation and tier-aware evaluation of multilingual LLMs.
Temporal Text Classification with Large Language Models
Mar 11, 2026Languages change over time. Computational models can be trained to recognize such changes enabling them to estimate the publication date of texts. Despite recent advancements in Large Language Models (LLMs), their performance on automatic dating of texts, also known as Temporal Text Classification (TTC), has not been explored. This study provides the first systematic evaluation of leading proprietary (Claude 3.5, GPT-4o, Gemini 1.5) and open-source (LLaMA 3.2, Gemma 2, Mistral, Nemotron 4) LLMs on TTC using three historical corpora, two in English and one in Portuguese. We test zero-shot and few-shot prompting, and fine-tuning settings. Our results indicate that proprietary models perform well, especially with few-shot prompting. They also indicate that fine-tuning substantially improves open-source models but that they still fail to match the performance delivered by proprietary LLMs.
Large Language Models for Mental Health: A Multilingual Evaluation
Feb 02, 2026Large Language Models (LLMs) have remarkable capabilities across NLP tasks. However, their performance in multilingual contexts, especially within the mental health domain, has not been thoroughly explored. In this paper, we evaluate proprietary and open-source LLMs on eight mental health datasets in various languages, as well as their machine-translated (MT) counterparts. We compare LLM performance in zero-shot, few-shot, and fine-tuned settings against conventional NLP baselines that do not employ LLMs. In addition, we assess translation quality across language families and typologies to understand its influence on LLM performance. Proprietary LLMs and fine-tuned open-source LLMs achieve competitive F1 scores on several datasets, often surpassing state-of-the-art results. However, performance on MT data is generally lower, and the extent of this decline varies by language and typology. This variation highlights both the strengths of LLMs in handling mental health tasks in languages other than English and their limitations when translation quality introduces structural or lexical mismatches.
TigerCoder: A Novel Suite of LLMs for Code Generation in Bangla
Sep 11, 2025Despite being the 5th most spoken language, Bangla remains underrepresented in Large Language Models (LLMs), particularly for code generation. This primarily stems from the scarcity of high-quality data to pre-train and/or finetune such models. Hence, we introduce the first dedicated family of Code LLMs for Bangla (1B & 9B). We offer three major contributions: (1) a comprehensive Bangla code instruction datasets for programming domain adaptation; (2) MBPP-Bangla, an evaluation benchmark for Bangla code generation; and (3) the TigerCoder-family of Code LLMs, achieving significant ~11-18% performance gains at Pass@1 over existing multilingual and general-purpose Bangla LLMs. Our findings show that curated, high-quality datasets can overcome limitations of smaller models for low-resource languages. We open-source all resources to advance further Bangla LLM research.
TigerLLM -- A Family of Bangla Large Language Models
Mar 14, 2025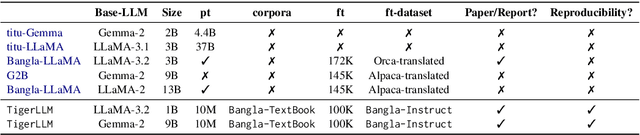

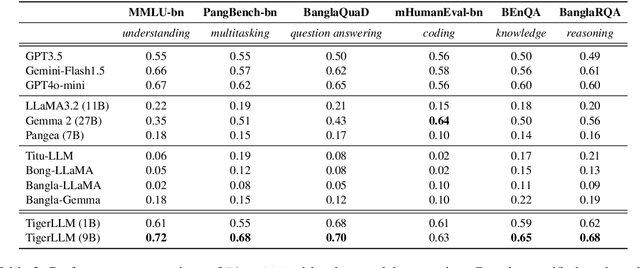
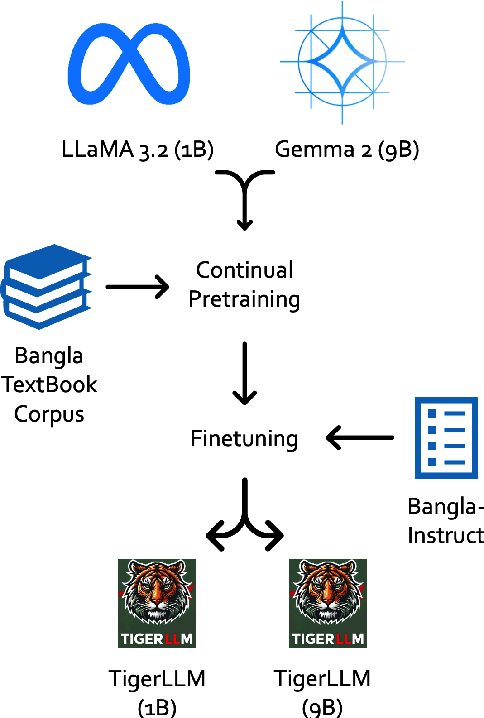
The development of Large Language Models (LLMs) remains heavily skewed towards English and a few other high-resource languages. This linguistic disparity is particularly evident for Bangla - the 5th most spoken language. A few initiatives attempted to create open-source Bangla LLMs with performance still behind high-resource languages and limited reproducibility. To address this gap, we introduce TigerLLM - a family of Bangla LLMs. Our results demonstrate that these models surpass all open-source alternatives and also outperform larger proprietary models like GPT3.5 across standard benchmarks, establishing TigerLLM as the new baseline for future Bangla language modeling.
Code LLMs: A Taxonomy-based Survey
Dec 11, 2024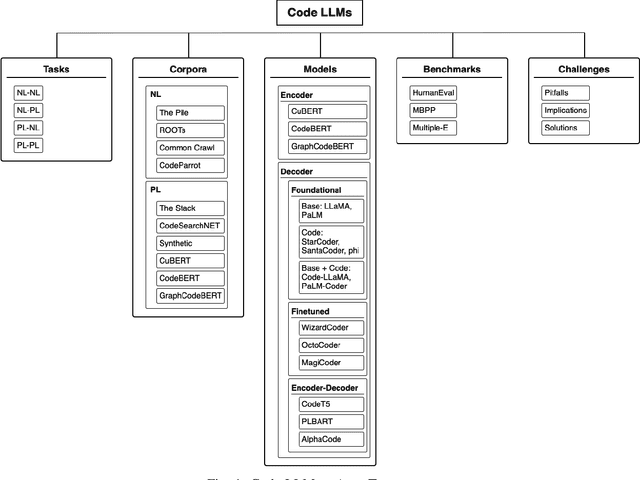

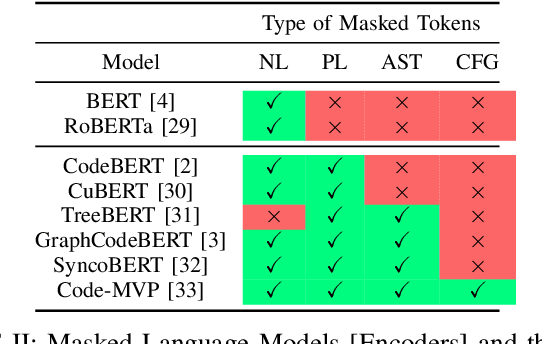
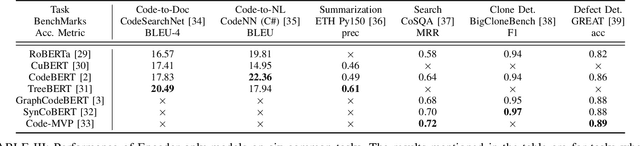
Large language models (LLMs) have demonstrated remarkable capabilities across various NLP tasks and have recently expanded their impact to coding tasks, bridging the gap between natural languages (NL) and programming languages (PL). This taxonomy-based survey provides a comprehensive analysis of LLMs in the NL-PL domain, investigating how these models are utilized in coding tasks and examining their methodologies, architectures, and training processes. We propose a taxonomy-based framework that categorizes relevant concepts, providing a unified classification system to facilitate a deeper understanding of this rapidly evolving field. This survey offers insights into the current state and future directions of LLMs in coding tasks, including their applications and limitations.
MojoBench: Language Modeling and Benchmarks for Mojo
Oct 23, 2024The recently introduced Mojo programming language (PL) by Modular, has received significant attention in the scientific community due to its claimed significant speed boost over Python. Despite advancements in code Large Language Models (LLMs) across various PLs, Mojo remains unexplored in this context. To address this gap, we introduce MojoBench, the first framework for Mojo code generation. MojoBench includes HumanEval-Mojo, a benchmark dataset designed for evaluating code LLMs on Mojo, and Mojo-Coder, the first LLM pretrained and finetuned for Mojo code generation, which supports instructions in 5 natural languages (NLs). Our results show that Mojo-Coder achieves a 30-35% performance improvement over leading models like GPT-4o and Claude-3.5-Sonnet. Furthermore, we provide insights into LLM behavior with underrepresented and unseen PLs, offering potential strategies for enhancing model adaptability. MojoBench contributes to our understanding of LLM capabilities and limitations in emerging programming paradigms fostering more robust code generation systems.
Large Language Models in Computer Science Education: A Systematic Literature Review
Oct 21, 2024
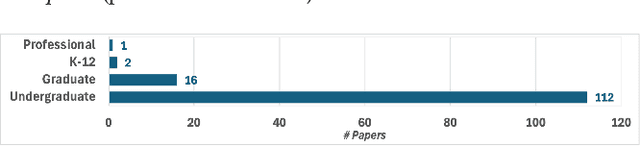
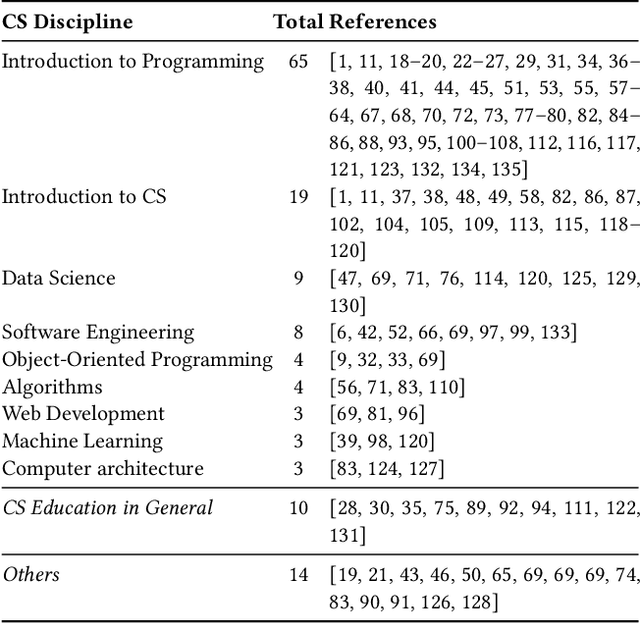
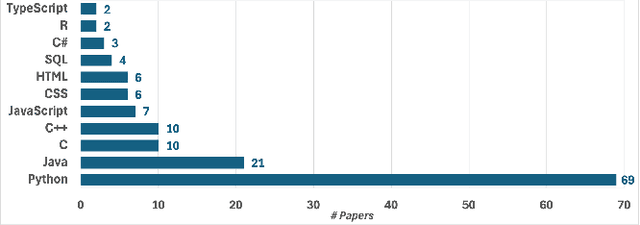
Large language models (LLMs) are becoming increasingly better at a wide range of Natural Language Processing tasks (NLP), such as text generation and understanding. Recently, these models have extended their capabilities to coding tasks, bridging the gap between natural languages (NL) and programming languages (PL). Foundational models such as the Generative Pre-trained Transformer (GPT) and LLaMA series have set strong baseline performances in various NL and PL tasks. Additionally, several models have been fine-tuned specifically for code generation, showing significant improvements in code-related applications. Both foundational and fine-tuned models are increasingly used in education, helping students write, debug, and understand code. We present a comprehensive systematic literature review to examine the impact of LLMs in computer science and computer engineering education. We analyze their effectiveness in enhancing the learning experience, supporting personalized education, and aiding educators in curriculum development. We address five research questions to uncover insights into how LLMs contribute to educational outcomes, identify challenges, and suggest directions for future research.
mHumanEval -- A Multilingual Benchmark to Evaluate Large Language Models for Code Generation
Oct 19, 2024



Recent advancements in large language models (LLMs) have significantly enhanced code generation from natural language prompts. The HumanEval Benchmark, developed by OpenAI, remains the most widely used code generation benchmark. However, this and other Code LLM benchmarks face critical limitations, particularly in task diversity, test coverage, and linguistic scope. Current evaluations primarily focus on English-to-Python conversion tasks with limited test cases, potentially overestimating model performance. While recent works have addressed test coverage and programming language (PL) diversity, code generation from low-resource language prompts remains largely unexplored. To address this gap, we introduce mHumanEval, an extended benchmark supporting prompts in over 200 natural languages. We employ established machine translation methods to compile the benchmark, coupled with a quality assurance process. Furthermore, we provide expert human translations for 15 diverse natural languages (NLs). We conclude by analyzing the multilingual code generation capabilities of state-of-the-art (SOTA) Code LLMs, offering insights into the current landscape of cross-lingual code generation.
MasonTigers at SemEval-2024 Task 10: Emotion Discovery and Flip Reasoning in Conversation with Ensemble of Transformers and Prompting
Jun 30, 2024


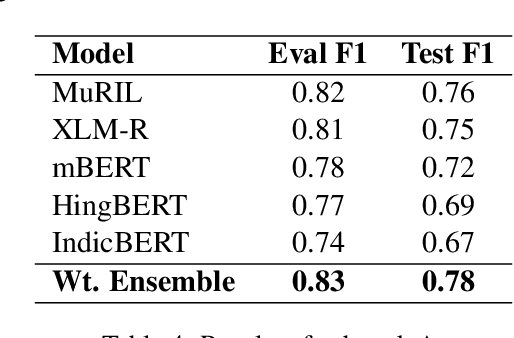
In this paper, we present MasonTigers' participation in SemEval-2024 Task 10, a shared task aimed at identifying emotions and understanding the rationale behind their flips within monolingual English and Hindi-English code-mixed dialogues. This task comprises three distinct subtasks - emotion recognition in conversation for Hindi-English code-mixed dialogues, emotion flip reasoning for Hindi-English code-mixed dialogues, and emotion flip reasoning for English dialogues. Our team, MasonTigers, contributed to each subtask, focusing on developing methods for accurate emotion recognition and reasoning. By leveraging our approaches, we attained impressive F1-scores of 0.78 for the first task and 0.79 for both the second and third tasks. This performance not only underscores the effectiveness of our methods across different aspects of the task but also secured us the top rank in the first and third subtasks, and the 2nd rank in the second subtask. Through extensive experimentation and analysis, we provide insights into our system's performance and contributions to each subtask.