 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Software Security Comprehension of Large Language Models
Dec 24, 2025



Large language models (LLMs) are increasingly used in software development, but their level of software security expertise remains unclear. This work systematically evaluates the security comprehension of five leading LLMs: GPT-4o-Mini, GPT-5-Mini, Gemini-2.5-Flash, Llama-3.1, and Qwen-2.5, using Blooms Taxonomy as a framework. We assess six cognitive dimensions: remembering, understanding, applying, analyzing, evaluating, and creating. Our methodology integrates diverse datasets, including curated multiple-choice questions, vulnerable code snippets (SALLM), course assessments from an Introduction to Software Security course, real-world case studies (XBOW), and project-based creation tasks from a Secure Software Engineering course. Results show that while LLMs perform well on lower-level cognitive tasks such as recalling facts and identifying known vulnerabilities, their performance degrades significantly on higher-order tasks that require reasoning, architectural evaluation, and secure system creation. Beyond reporting aggregate accuracy, we introduce a software security knowledge boundary that identifies the highest cognitive level at which a model consistently maintains reliable performance. In addition, we identify 51 recurring misconception patterns exhibited by LLMs across Blooms levels.
Large Language Models in Computer Science Education: A Systematic Literature Review
Oct 21, 2024
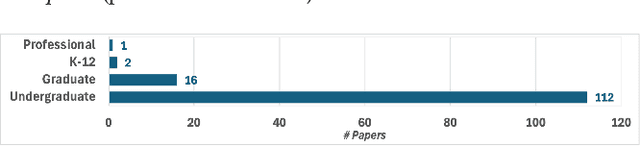
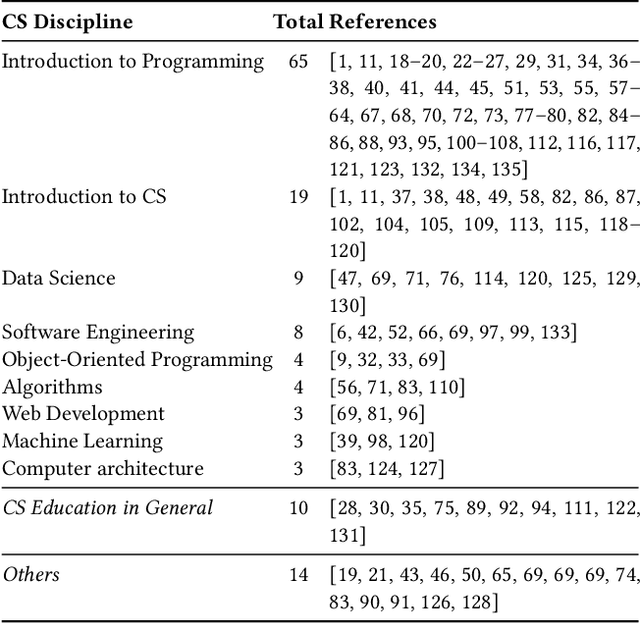
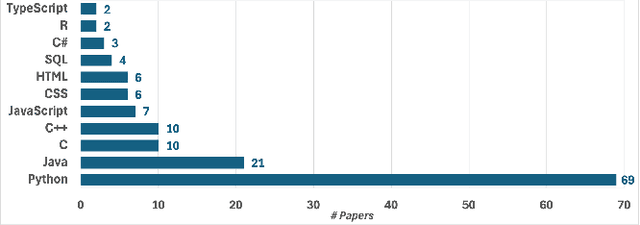
Large language models (LLMs) are becoming increasingly better at a wide range of Natural Language Processing tasks (NLP), such as text generation and understanding. Recently, these models have extended their capabilities to coding tasks, bridging the gap between natural languages (NL) and programming languages (PL). Foundational models such as the Generative Pre-trained Transformer (GPT) and LLaMA series have set strong baseline performances in various NL and PL tasks. Additionally, several models have been fine-tuned specifically for code generation, showing significant improvements in code-related applications. Both foundational and fine-tuned models are increasingly used in education, helping students write, debug, and understand code. We present a comprehensive systematic literature review to examine the impact of LLMs in computer science and computer engineering education. We analyze their effectiveness in enhancing the learning experience, supporting personalized education, and aiding educators in curriculum development. We address five research questions to uncover insights into how LLMs contribute to educational outcomes, identify challenges, and suggest directions for future research.
Quality Assessment of Prompts Used in Code Generation
Apr 15, 2024



Large Language Models (LLMs) are gaining popularity among software engineers. A crucial aspect of developing effective code-generation LLMs is to evaluate these models using a robust benchmark. Evaluation benchmarks with quality issues can provide a false sense of performance. In this work, we conduct the first-of-its-kind study of the quality of prompts within benchmarks used to compare the performance of different code generation models. To conduct this study, we analyzed 3,566 prompts from 9 code generation benchmarks to identify quality issues in them. We also investigated whether fixing the identified quality issues in the benchmarks' prompts affects a model's performance. We also studied memorization issues of the evaluation dataset, which can put into question a benchmark's trustworthiness. We found that code generation evaluation benchmarks mainly focused on Python and coding exercises and had very limited contextual dependencies to challenge the model. These datasets and the developers' prompts suffer from quality issues like spelling and grammatical errors, unclear sentences to express developers' intent, and not using proper documentation style. Fixing all these issues in the benchmarks can lead to a better performance for Python code generation, but not a significant improvement was observed for Java code generation. We also found evidence that GPT-3.5-Turbo and CodeGen-2.5 models possibly have data contamination issues.
Generate and Pray: Using SALLMS to Evaluate the Security of LLM Generated Code
Nov 01, 2023

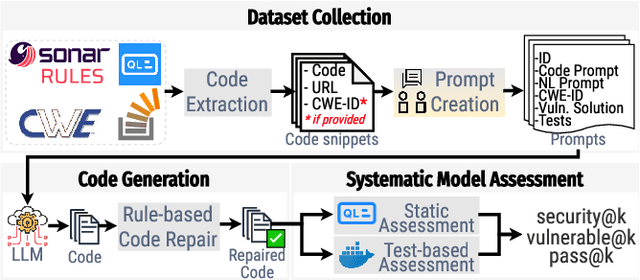
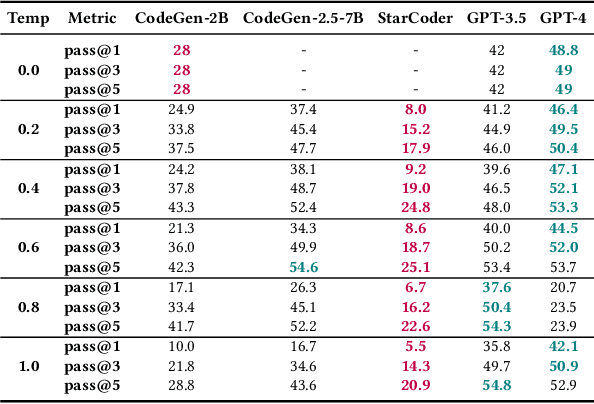
With the growing popularity of Large Language Models (e.g. GitHub Copilot, ChatGPT, etc.) in software engineers' daily practices, it is important to ensure that the code generated by these tools is not only functionally correct but also free of vulnerabilities. Although LLMs can help developers to be more productive, prior empirical studies have shown that LLMs can generate insecure code. There are two contributing factors to the insecure code generation. First, existing datasets used to evaluate Large Language Models (LLMs) do not adequately represent genuine software engineering tasks sensitive to security. Instead, they are often based on competitive programming challenges or classroom-type coding tasks. In real-world applications, the code produced is integrated into larger codebases, introducing potential security risks. There's a clear absence of benchmarks that focus on evaluating the security of the generated code. Second, existing evaluation metrics primarily focus on the functional correctness of the generated code while ignoring security considerations. Metrics such as pass@k gauge the probability of obtaining the correct code in the top k suggestions. Other popular metrics like BLEU, CodeBLEU, ROUGE, and METEOR similarly emphasize functional accuracy, neglecting security implications. In light of these research gaps, in this paper, we described SALLM, a framework to benchmark LLMs' abilities to generate secure code systematically. This framework has three major components: a novel dataset of security-centric Python prompts, an evaluation environment to test the generated code, and novel metrics to evaluate the models' performance from the perspective of secure code generation.
A Lightweight Framework for High-Quality Code Generation
Jul 17, 2023In recent years, the use of automated source code generation utilizing transformer-based generative models has expanded, and these models can generate functional code according to the requirements of the developers. However, recent research revealed that these automatically generated source codes can contain vulnerabilities and other quality issues. Despite researchers' and practitioners' attempts to enhance code generation models, retraining and fine-tuning large language models is time-consuming and resource-intensive. Thus, we describe FRANC, a lightweight framework for recommending more secure and high-quality source code derived from transformer-based code generation models. FRANC includes a static filter to make the generated code compilable with heuristics and a quality-aware ranker to sort the code snippets based on a quality score. Moreover, the framework uses prompt engineering to fix persistent quality issues. We evaluated the framework with five Python and Java code generation models and six prompt datasets, including a newly created one in this work (SOEval). The static filter improves 9% to 46% Java suggestions and 10% to 43% Python suggestions regarding compilability. The average improvement over the NDCG@10 score for the ranking system is 0.0763, and the repairing techniques repair the highest 80% of prompts. FRANC takes, on average, 1.98 seconds for Java; for Python, it takes 0.08 seconds.
Exploring the Effectiveness of Large Language Models in Generating Unit Tests
Apr 30, 2023


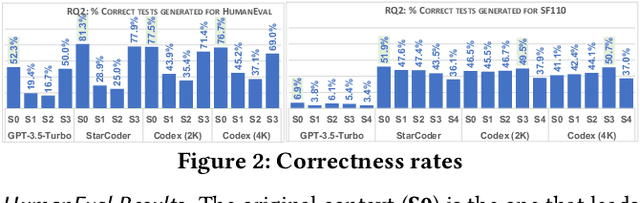
A code generation model generates code by taking a prompt from a code comment, existing code, or a combination of both. Although code generation models (e.g., GitHub Copilot) are increasingly being adopted in practice, it is unclear whether they can successfully be used for unit test generation without fine-tuning. To fill this gap, we investigated how well three generative models (CodeGen, Codex, and GPT-3.5) can generate test cases. We used two benchmarks (HumanEval and Evosuite SF110) to investigate the context generation's effect in the unit test generation process. We evaluated the models based on compilation rates, test correctness, coverage, and test smells. We found that the Codex model achieved above 80% coverage for the HumanEval dataset, but no model had more than 2% coverage for the EvoSuite SF110 benchmark. The generated tests also suffered from test smells, such as Duplicated Asserts and Empty Tests.