 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large-Scale Exploit Instrumentation Study of AI/ML Supply Chain Attacks in Hugging Face Models
Oct 06, 2024
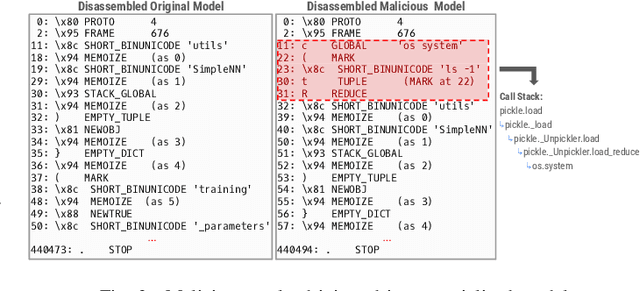

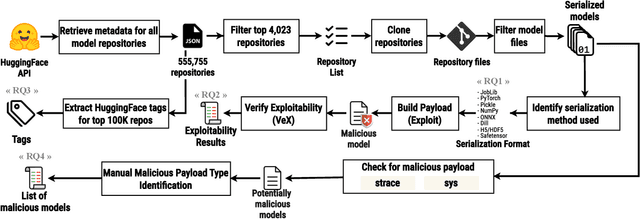
The development of machine learning (ML) techniques has led to ample opportunities for developers to develop and deploy their own models. Hugging Face serves as an open source platform where developers can share and download other models in an effort to make ML development more collaborative. In order for models to be shared, they first need to be serialized. Certain Python serialization methods are considered unsafe, as they are vulnerable to object injection. This paper investigates the pervasiveness of these unsafe serialization methods across Hugging Face, and demonstrates through an exploitation approach, that models using unsafe serialization methods can be exploited and shared, creating an unsafe environment for ML developers. We investigate to what extent Hugging Face is able to flag repositories and files using unsafe serialization methods, and develop a technique to detect malicious models. Our results show that Hugging Face is home to a wide range of potentially vulnerable models.
A Survey of Source Code Representations for Machine Learning-Based Cybersecurity Tasks
Mar 15, 2024



Machine learning techniques for cybersecurity-related software engineering tasks are becoming increasingly popular. The representation of source code is a key portion of the technique that can impact the way the model is able to learn the features of the source code. With an increasing number of these techniques being developed, it is valuable to see the current state of the field to better understand what exists and what's not there yet. This paper presents a study of these existing ML-based approaches and demonstrates what type of representations were used for different cybersecurity tasks and programming languages. Additionally, we study what types of models are used with different representations. We have found that graph-based representations are the most popular category of representation, and Tokenizers and Abstract Syntax Trees (ASTs) are the two most popular representations overall. We also found that the most popular cybersecurity task is vulnerability detection, and the language that is covered by the most techniques is C. Finally, we found that sequence-based models are the most popular category of models, and Support Vector Machines (SVMs) are the most popular model overall.
A Lightweight Framework for High-Quality Code Generation
Jul 17, 2023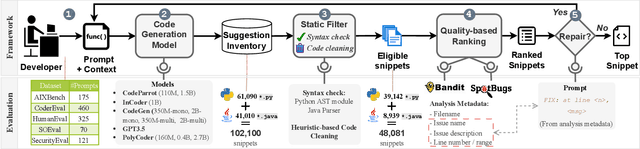

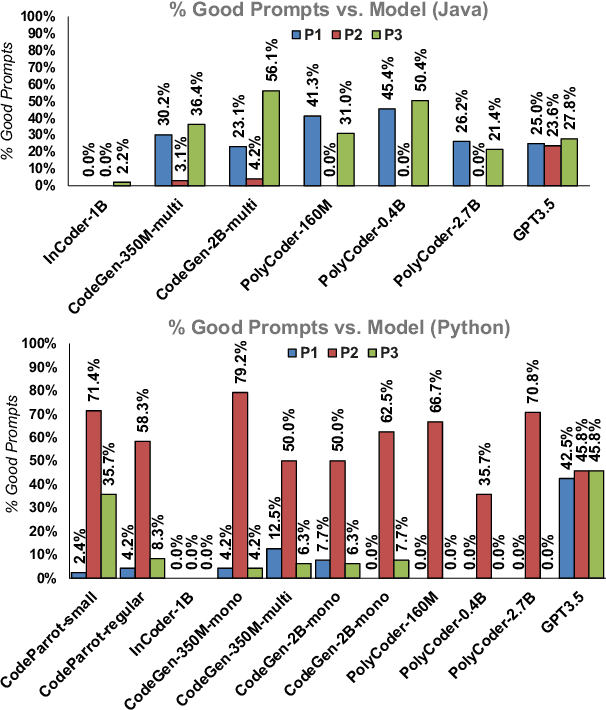

In recent years, the use of automated source code generation utilizing transformer-based generative models has expanded, and these models can generate functional code according to the requirements of the developers. However, recent research revealed that these automatically generated source codes can contain vulnerabilities and other quality issues. Despite researchers' and practitioners' attempts to enhance code generation models, retraining and fine-tuning large language models is time-consuming and resource-intensive. Thus, we describe FRANC, a lightweight framework for recommending more secure and high-quality source code derived from transformer-based code generation models. FRANC includes a static filter to make the generated code compilable with heuristics and a quality-aware ranker to sort the code snippets based on a quality score. Moreover, the framework uses prompt engineering to fix persistent quality issues. We evaluated the framework with five Python and Java code generation models and six prompt datasets, including a newly created one in this work (SOEval). The static filter improves 9% to 46% Java suggestions and 10% to 43% Python suggestions regarding compilability. The average improvement over the NDCG@10 score for the ranking system is 0.0763, and the repairing techniques repair the highest 80% of prompts. FRANC takes, on average, 1.98 seconds for Java; for Python, it takes 0.08 seconds.