 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBangla Grammatical Error Detection Leveraging Transformer-based Token Classification
Nov 13, 2024Bangla is the seventh most spoken language by a total number of speakers in the world, and yet the development of an automated grammar checker in this language is an understudied problem. Bangla grammatical error detection is a task of detecting sub-strings of a Bangla text that contain grammatical, punctuation, or spelling errors, which is crucial for developing an automated Bangla typing assistant. Our approach involves breaking down the task as a token classification problem and utilizing state-of-the-art transformer-based models. Finally, we combine the output of these models and apply rule-based post-processing to generate a more reliable and comprehensive result. Our system is evaluated on a dataset consisting of over 25,000 texts from various sources. Our best model achieves a Levenshtein distance score of 1.04. Finally, we provide a detailed analysis of different components of our system.
Exploring the Effectiveness of Large Language Models in Generating Unit Tests
Apr 30, 2023


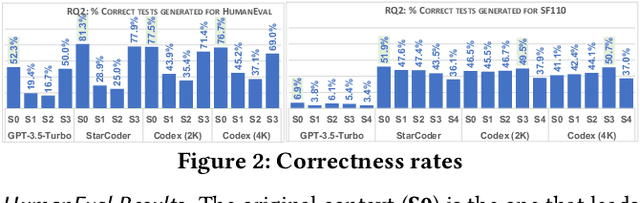
A code generation model generates code by taking a prompt from a code comment, existing code, or a combination of both. Although code generation models (e.g., GitHub Copilot) are increasingly being adopted in practice, it is unclear whether they can successfully be used for unit test generation without fine-tuning. To fill this gap, we investigated how well three generative models (CodeGen, Codex, and GPT-3.5) can generate test cases. We used two benchmarks (HumanEval and Evosuite SF110) to investigate the context generation's effect in the unit test generation process. We evaluated the models based on compilation rates, test correctness, coverage, and test smells. We found that the Codex model achieved above 80% coverage for the HumanEval dataset, but no model had more than 2% coverage for the EvoSuite SF110 benchmark. The generated tests also suffered from test smells, such as Duplicated Asserts and Empty Tests.