 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Effectiveness of Large Language Models in Generating Unit Tests
Paper and Code



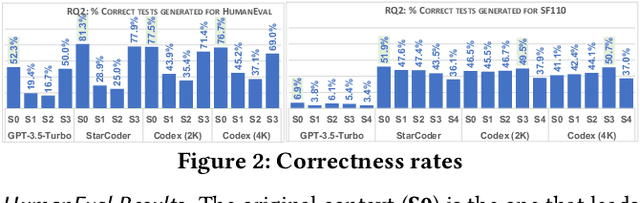
A code generation model generates code by taking a prompt from a code comment, existing code, or a combination of both. Although code generation models (e.g., GitHub Copilot) are increasingly being adopted in practice, it is unclear whether they can successfully be used for unit test generation without fine-tuning. To fill this gap, we investigated how well three generative models (CodeGen, Codex, and GPT-3.5) can generate test cases. We used two benchmarks (HumanEval and Evosuite SF110) to investigate the context generation's effect in the unit test generation process. We evaluated the models based on compilation rates, test correctness, coverage, and test smells. We found that the Codex model achieved above 80% coverage for the HumanEval dataset, but no model had more than 2% coverage for the EvoSuite SF110 benchmark. The generated tests also suffered from test smells, such as Duplicated Asserts and Empty Tests.