 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmoMix-3L: A Code-Mixed Dataset for Bangla-English-Hindi Emotion Detection
May 11, 2024Code-mixing is a well-studied linguistic phenomenon that occurs when two or more languages are mixed in text or speech. Several studies have been conducted on building datasets and performing downstream NLP tasks on code-mixed data. Although it is not uncommon to observe code-mixing of three or more languages, most available datasets in this domain contain code-mixed data from only two languages. In this paper, we introduce EmoMix-3L, a novel multi-label emotion detection dataset containing code-mixed data from three different languages. We experiment with several models on EmoMix-3L and we report that MuRIL outperforms other models on this dataset.
OffMix-3L: A Novel Code-Mixed Dataset in Bangla-English-Hindi for Offensive Language Identification
Oct 27, 2023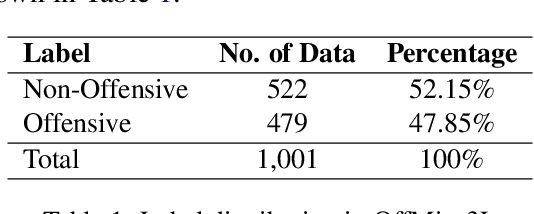


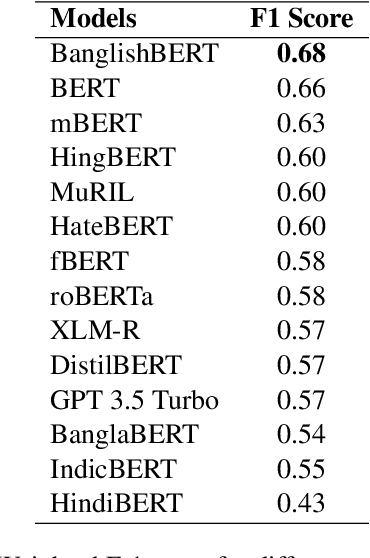
Code-mixing is a well-studied linguistic phenomenon when two or more languages are mixed in text or speech. Several works have been conducted on building datasets and performing downstream NLP tasks on code-mixed data. Although it is not uncommon to observe code-mixing of three or more languages, most available datasets in this domain contain code-mixed data from only two languages. In this paper, we introduce OffMix-3L, a novel offensive language identification dataset containing code-mixed data from three different languages. We experiment with several models on this dataset and observe that BanglishBERT outperforms other transformer-based models and GPT-3.5.
SentMix-3L: A Bangla-English-Hindi Code-Mixed Dataset for Sentiment Analysis
Oct 27, 2023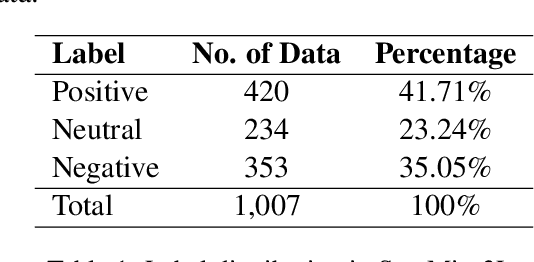

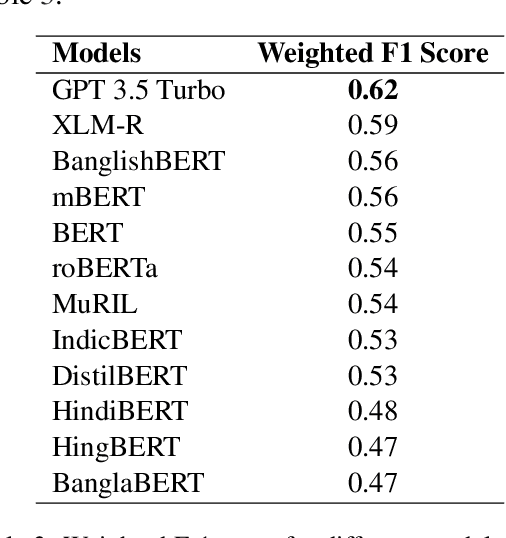
Code-mixing is a well-studied linguistic phenomenon when two or more languages are mixed in text or speech. Several datasets have been build with the goal of training computational models for code-mixing. Although it is very common to observe code-mixing with multiple languages, most datasets available contain code-mixed between only two languages. In this paper, we introduce SentMix-3L, a novel dataset for sentiment analysis containing code-mixed data between three languages Bangla, English, and Hindi. We carry out a comprehensive evaluation using SentMix-3L. We show that zero-shot prompting with GPT-3.5 outperforms all transformer-based models on SentMix-3L.
Mixed-Distil-BERT: Code-mixed Language Modeling for Bangla, English, and Hindi
Sep 19, 2023



One of the most popular downstream tasks in the field of Natural Language Processing is text classification. Text classification tasks have become more daunting when the texts are code-mixed. Though they are not exposed to such text during pre-training, different BERT models have demonstrated success in tackling Code-Mixed NLP challenges. Again, in order to enhance their performance, Code-Mixed NLP models have depended on combining synthetic data with real-world data. It is crucial to understand how the BERT models' performance is impacted when they are pretrained using corresponding code-mixed languages. In this paper, we introduce Tri-Distil-BERT, a multilingual model pre-trained on Bangla, English, and Hindi, and Mixed-Distil-BERT, a model fine-tuned on code-mixed data. Both models are evaluated across multiple NLP tasks and demonstrate competitive performance against larger models like mBERT and XLM-R. Our two-tiered pre-training approach offers efficient alternatives for multilingual and code-mixed language understanding, contributing to advancements in the field.