Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffMix-3L: A Novel Code-Mixed Dataset in Bangla-English-Hindi for Offensive Language Identification
Paper and Code
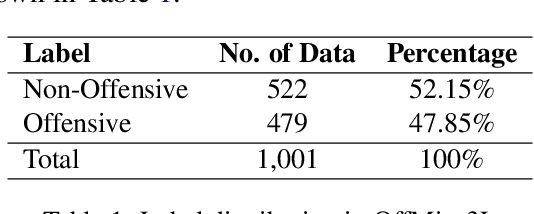


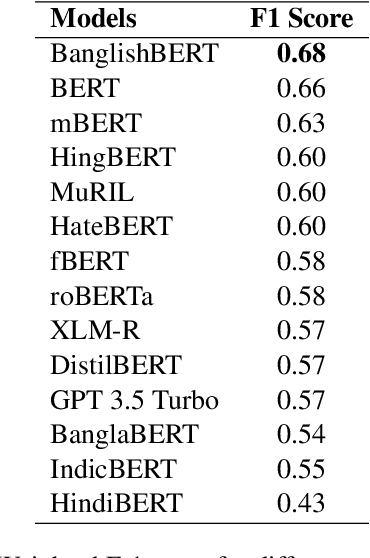
Code-mixing is a well-studied linguistic phenomenon when two or more languages are mixed in text or speech. Several works have been conducted on building datasets and performing downstream NLP tasks on code-mixed data. Although it is not uncommon to observe code-mixing of three or more languages, most available datasets in this domain contain code-mixed data from only two languages. In this paper, we introduce OffMix-3L, a novel offensive language identification dataset containing code-mixed data from three different languages. We experiment with several models on this dataset and observe that BanglishBERT outperforms other transformer-based models and GPT-3.5.
* arXiv admin note: substantial text overlap with arXiv:2310.18023
View paper on