 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models for Mental Health: A Multilingual Evaluation
Feb 02, 2026Large Language Models (LLMs) have remarkable capabilities across NLP tasks. However, their performance in multilingual contexts, especially within the mental health domain, has not been thoroughly explored. In this paper, we evaluate proprietary and open-source LLMs on eight mental health datasets in various languages, as well as their machine-translated (MT) counterparts. We compare LLM performance in zero-shot, few-shot, and fine-tuned settings against conventional NLP baselines that do not employ LLMs. In addition, we assess translation quality across language families and typologies to understand its influence on LLM performance. Proprietary LLMs and fine-tuned open-source LLMs achieve competitive F1 scores on several datasets, often surpassing state-of-the-art results. However, performance on MT data is generally lower, and the extent of this decline varies by language and typology. This variation highlights both the strengths of LLMs in handling mental health tasks in languages other than English and their limitations when translation quality introduces structural or lexical mismatches.
MasonTigers at SemEval-2024 Task 10: Emotion Discovery and Flip Reasoning in Conversation with Ensemble of Transformers and Prompting
Jun 30, 2024


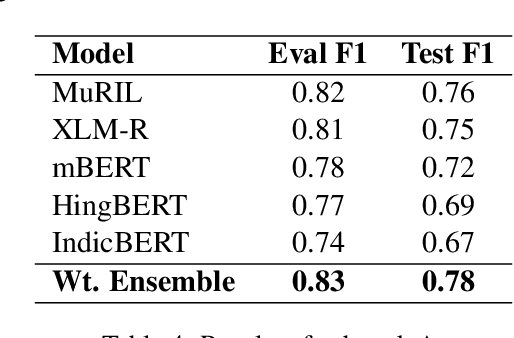
In this paper, we present MasonTigers' participation in SemEval-2024 Task 10, a shared task aimed at identifying emotions and understanding the rationale behind their flips within monolingual English and Hindi-English code-mixed dialogues. This task comprises three distinct subtasks - emotion recognition in conversation for Hindi-English code-mixed dialogues, emotion flip reasoning for Hindi-English code-mixed dialogues, and emotion flip reasoning for English dialogues. Our team, MasonTigers, contributed to each subtask, focusing on developing methods for accurate emotion recognition and reasoning. By leveraging our approaches, we attained impressive F1-scores of 0.78 for the first task and 0.79 for both the second and third tasks. This performance not only underscores the effectiveness of our methods across different aspects of the task but also secured us the top rank in the first and third subtasks, and the 2nd rank in the second subtask. Through extensive experimentation and analysis, we provide insights into our system's performance and contributions to each subtask.
MasonTigers at SemEval-2024 Task 1: An Ensemble Approach for Semantic Textual Relatedness
Apr 06, 2024
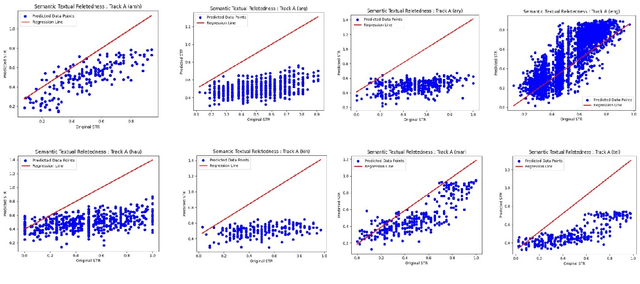
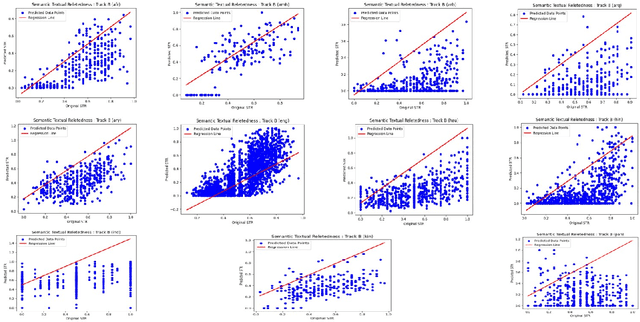
This paper presents the MasonTigers entry to the SemEval-2024 Task 1 - Semantic Textual Relatedness. The task encompasses supervised (Track A), unsupervised (Track B), and cross-lingual (Track C) approaches across 14 different languages. MasonTigers stands out as one of the two teams who participated in all languages across the three tracks. Our approaches achieved rankings ranging from 11th to 21st in Track A, from 1st to 8th in Track B, and from 5th to 12th in Track C. Adhering to the task-specific constraints, our best performing approaches utilize ensemble of statistical machine learning approaches combined with language-specific BERT based models and sentence transformers.
MasonTigers at SemEval-2024 Task 8: Performance Analysis of Transformer-based Models on Machine-Generated Text Detection
Apr 05, 2024This paper presents the MasonTigers entry to the SemEval-2024 Task 8 - Multigenerator, Multidomain, and Multilingual Black-Box Machine-Generated Text Detection. The task encompasses Binary Human-Written vs. Machine-Generated Text Classification (Track A), Multi-Way Machine-Generated Text Classification (Track B), and Human-Machine Mixed Text Detection (Track C). Our best performing approaches utilize mainly the ensemble of discriminator transformer models along with sentence transformer and statistical machine learning approaches in specific cases. Moreover, zero-shot prompting and fine-tuning of FLAN-T5 are used for Track A and B.
CSEPrompts: A Benchmark of Introductory Computer Science Prompts
Apr 04, 2024



Recent advances in AI, machine learning, and NLP have led to the development of a new generation of Large Language Models (LLMs) that are trained on massive amounts of data and often have trillions of parameters. Commercial applications (e.g., ChatGPT) have made this technology available to the general public, thus making it possible to use LLMs to produce high-quality texts for academic and professional purposes. Schools and universities are aware of the increasing use of AI-generated content by students and they have been researching the impact of this new technology and its potential misuse. Educational programs in Computer Science (CS) and related fields are particularly affected because LLMs are also capable of generating programming code in various programming languages. To help understand the potential impact of publicly available LLMs in CS education, we introduce CSEPrompts, a framework with hundreds of programming exercise prompts and multiple-choice questions retrieved from introductory CS and programming courses. We also provide experimental results on CSEPrompts to evaluate the performance of several LLMs with respect to generating Python code and answering basic computer science and programming questions.
MasonTigers at SemEval-2024 Task 9: Solving Puzzles with an Ensemble of Chain-of-Thoughts
Apr 03, 2024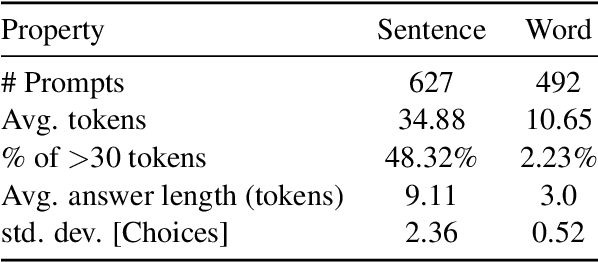


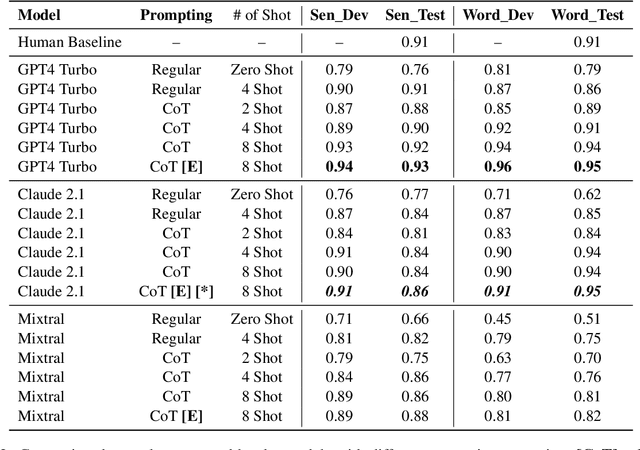
Our paper presents team MasonTigers submission to the SemEval-2024 Task 9 - which provides a dataset of puzzles for testing natural language understanding. We employ large language models (LLMs) to solve this task through several prompting techniques. Zero-shot and few-shot prompting generate reasonably good results when tested with proprietary LLMs, compared to the open-source models. We obtain further improved results with chain-of-thought prompting, an iterative prompting method that breaks down the reasoning process step-by-step. We obtain our best results by utilizing an ensemble of chain-of-thought prompts, placing 2nd in the word puzzle subtask and 13th in the sentence puzzle subtask. The strong performance of prompted LLMs demonstrates their capability for complex reasoning when provided with a decomposition of the thought process. Our work sheds light on how step-wise explanatory prompts can unlock more of the knowledge encoded in the parameters of large models.
MasonPerplexity at Multimodal Hate Speech Event Detection 2024: Hate Speech and Target Detection Using Transformer Ensembles
Feb 03, 2024
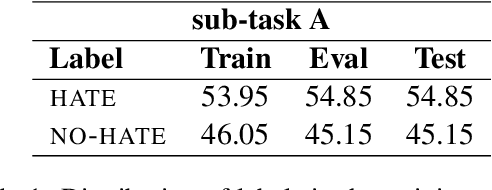

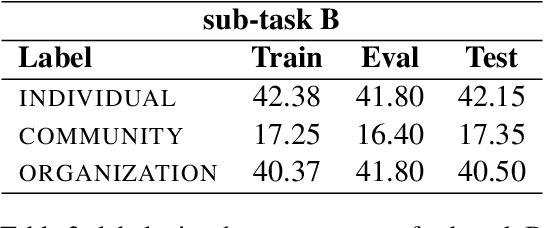
The automatic identification of offensive language such as hate speech is important to keep discussions civil in online communities. Identifying hate speech in multimodal content is a particularly challenging task because offensiveness can be manifested in either words or images or a juxtaposition of the two. This paper presents the MasonPerplexity submission for the Shared Task on Multimodal Hate Speech Event Detection at CASE 2024 at EACL 2024. The task is divided into two sub-tasks: sub-task A focuses on the identification of hate speech and sub-task B focuses on the identification of targets in text-embedded images during political events. We use an XLM-roBERTa-large model for sub-task A and an ensemble approach combining XLM-roBERTa-base, BERTweet-large, and BERT-base for sub-task B. Our approach obtained 0.8347 F1-score in sub-task A and 0.6741 F1-score in sub-task B ranking 3rd on both sub-tasks.
MasonPerplexity at ClimateActivism 2024: Integrating Advanced Ensemble Techniques and Data Augmentation for Climate Activism Stance and Hate Event Identification
Feb 03, 2024The task of identifying public opinions on social media, particularly regarding climate activism and the detection of hate events, has emerged as a critical area of research in our rapidly changing world. With a growing number of people voicing either to support or oppose to climate-related issues - understanding these diverse viewpoints has become increasingly vital. Our team, MasonPerplexity, participates in a significant research initiative focused on this subject. We extensively test various models and methods, discovering that our most effective results are achieved through ensemble modeling, enhanced by data augmentation techniques like back-translation. In the specific components of this research task, our team achieved notable positions, ranking 5th, 1st, and 6th in the respective sub-tasks, thereby illustrating the effectiveness of our approach in this important field of study.
MasonTigers@LT-EDI-2024: An Ensemble Approach towards Detecting Homophobia and Transphobia in Social Media Comments
Jan 26, 2024
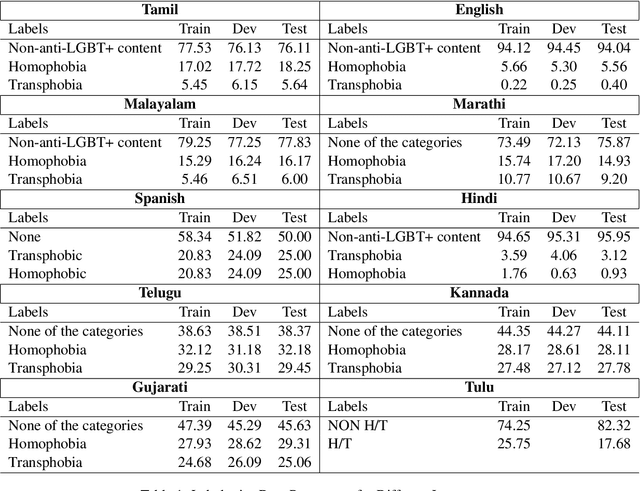
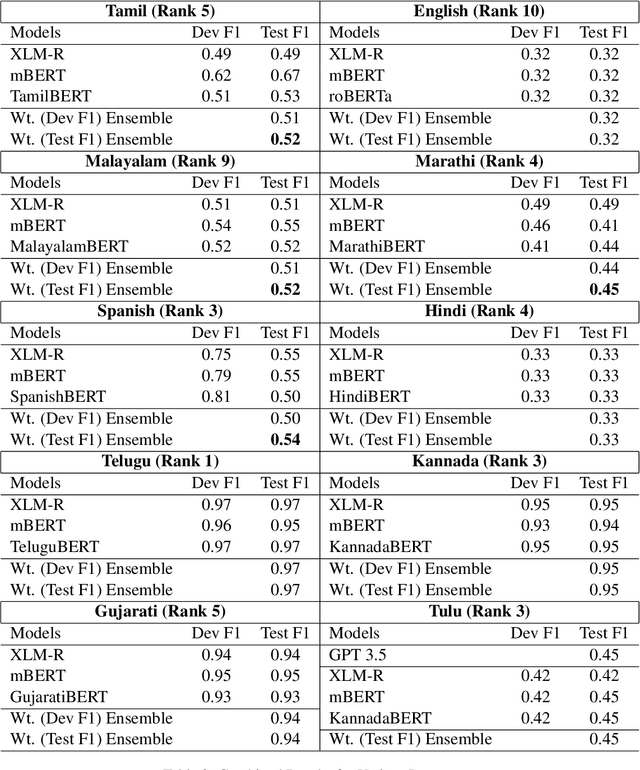
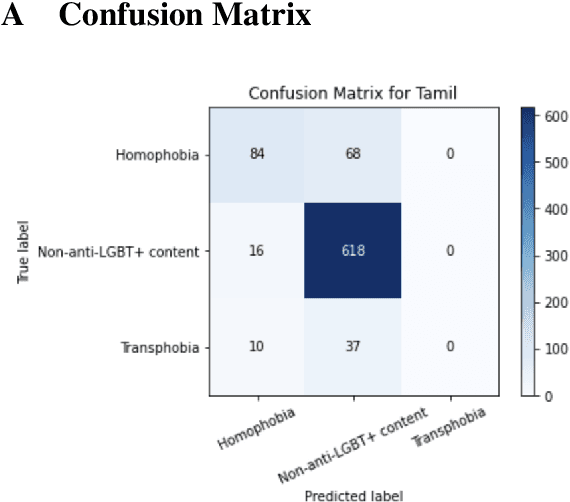
In this paper, we describe our approaches and results for Task 2 of the LT-EDI 2024 Workshop, aimed at detecting homophobia and/or transphobia across ten languages. Our methodologies include monolingual transformers and ensemble methods, capitalizing on the strengths of each to enhance the performance of the models. The ensemble models worked well, placing our team, MasonTigers, in the top five for eight of the ten languages, as measured by the macro F1 score. Our work emphasizes the efficacy of ensemble methods in multilingual scenarios, addressing the complexities of language-specific tasks.
nlpBDpatriots at BLP-2023 Task 2: A Transfer Learning Approach to Bangla Sentiment Analysis
Nov 25, 2023



In this paper, we discuss the nlpBDpatriots entry to the shared task on Sentiment Analysis of Bangla Social Media Posts organized at the first workshop on Bangla Language Processing (BLP) co-located with EMNLP. The main objective of this task is to identify the polarity of social media content using a Bangla dataset annotated with positive, neutral, and negative labels provided by the shared task organizers. Our best system for this task is a transfer learning approach with data augmentation which achieved a micro F1 score of 0.71. Our best system ranked 12th among 30 teams that participated in the competition.