 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Imaging Follow-Up in Radiology Reports: A Comparative Analysis of Traditional ML and LLM Approaches
Nov 14, 2025Large language models (LLMs) have shown considerable promise in clinical natural language processing, yet few domain-specific datasets exist to rigorously evaluate their performance on radiology tasks. In this work, we introduce an annotated corpus of 6,393 radiology reports from 586 patients, each labeled for follow-up imaging status, to support the development and benchmarking of follow-up adherence detection systems. Using this corpus, we systematically compared traditional machine-learning classifiers, including logistic regression (LR), support vector machines (SVM), Longformer, and a fully fine-tuned Llama3-8B-Instruct, with recent generative LLMs. To evaluate generative LLMs, we tested GPT-4o and the open-source GPT-OSS-20B under two configurations: a baseline (Base) and a task-optimized (Advanced) setting that focused inputs on metadata, recommendation sentences, and their surrounding context. A refined prompt for GPT-OSS-20B further improved reasoning accuracy. Performance was assessed using precision, recall, and F1 scores with 95% confidence intervals estimated via non-parametric bootstrapping. Inter-annotator agreement was high (F1 = 0.846). GPT-4o (Advanced) achieved the best performance (F1 = 0.832), followed closely by GPT-OSS-20B (Advanced; F1 = 0.828). LR and SVM also performed strongly (F1 = 0.776 and 0.775), underscoring that while LLMs approach human-level agreement through prompt optimization, interpretable and resource-efficient models remain valuable baselines.
A Scoping Review of Natural Language Processing in Addressing Medically Inaccurate Information: Errors, Misinformation, and Hallucination
Apr 16, 2025Objective: This review aims to explore the potential and challenges of using Natural Language Processing (NLP) to detect, correct, and mitigate medically inaccurate information, including errors, misinformation, and hallucination. By unifying these concepts, the review emphasizes their shared methodological foundations and their distinct implications for healthcare. Our goal is to advance patient safety, improve public health communication, and support the development of more reliable and transparent NLP applications in healthcare. Methods: A scoping review was conducted following PRISMA guidelines, analyzing studies from 2020 to 2024 across five databases. Studies were selected based on their use of NLP to address medically inaccurate information and were categorized by topic, tasks, document types, datasets, models, and evaluation metrics. Results: NLP has shown potential in addressing medically inaccurate information on the following tasks: (1) error detection (2) error correction (3) misinformation detection (4) misinformation correction (5) hallucination detection (6) hallucination mitigation. However, challenges remain with data privacy, context dependency, and evaluation standards. Conclusion: This review highlights the advancements in applying NLP to tackle medically inaccurate information while underscoring the need to address persistent challenges. Future efforts should focus on developing real-world datasets, refining contextual methods, and improving hallucination management to ensure reliable and transparent healthcare applications.
Does Data Contamination Detection Work (Well) for LLMs? A Survey and Evaluation on Detection Assumptions
Oct 24, 2024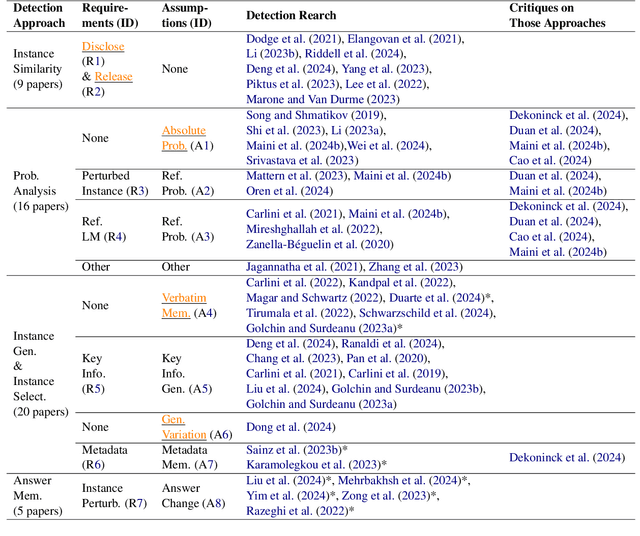
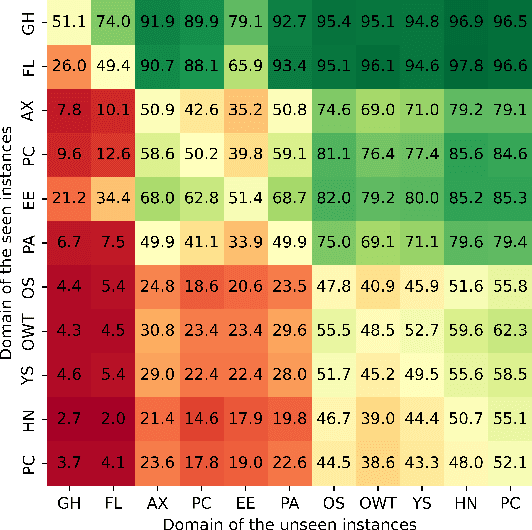
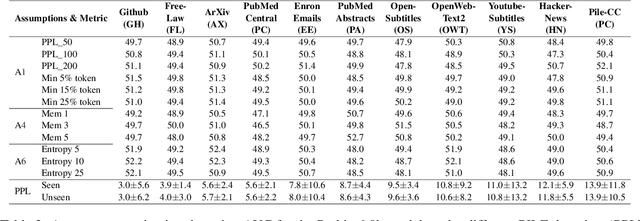
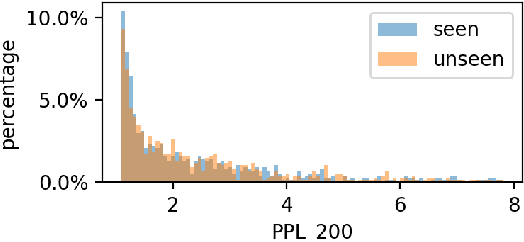
Large language models (LLMs) have demonstrated great performance across various benchmarks, showing potential as general-purpose task solvers. However, as LLMs are typically trained on vast amounts of data, a significant concern in their evaluation is data contamination, where overlap between training data and evaluation datasets inflates performance assessments. While multiple approaches have been developed to identify data contamination, these approaches rely on specific assumptions that may not hold universally across different settings. To bridge this gap, we systematically review 47 papers on data contamination detection, categorize the underlying assumptions, and assess whether they have been rigorously validated. We identify and analyze eight categories of assumptions and test three of them as case studies. Our analysis reveals that when classifying instances used for pretraining LLMs, detection approaches based on these three assumptions perform close to random guessing, suggesting that current LLMs learn data distributions rather than memorizing individual instances. Overall, this work underscores the importance of approaches clearly stating their underlying assumptions and testing their validity across various scenarios.
BioMistral-NLU: Towards More Generalizable Medical Language Understanding through Instruction Tuning
Oct 24, 2024



Large language models (LLMs) such as ChatGPT are fine-tuned on large and diverse instruction-following corpora, and can generalize to new tasks. However, those instruction-tuned LLMs often perform poorly in specialized medical natural language understanding (NLU) tasks that require domain knowledge, granular text comprehension, and structured data extraction. To bridge the gap, we: (1) propose a unified prompting format for 7 important NLU tasks, % through span extraction and multi-choice question-answering (QA), (2) curate an instruction-tuning dataset, MNLU-Instruct, utilizing diverse existing open-source medical NLU corpora, and (3) develop BioMistral-NLU, a generalizable medical NLU model, through fine-tuning BioMistral on MNLU-Instruct. We evaluate BioMistral-NLU in a zero-shot setting, across 6 important NLU tasks, from two widely adopted medical NLU benchmarks: Biomedical Language Understanding Evaluation (BLUE) and Biomedical Language Understanding and Reasoning Benchmark (BLURB). Our experiments show that our BioMistral-NLU outperforms the original BioMistral, as well as the proprietary LLMs - ChatGPT and GPT-4. Our dataset-agnostic prompting strategy and instruction tuning step over diverse NLU tasks enhance LLMs' generalizability across diverse medical NLU tasks. Our ablation experiments show that instruction-tuning on a wider variety of tasks, even when the total number of training instances remains constant, enhances downstream zero-shot generalization.
MasonTigers at SemEval-2024 Task 8: Performance Analysis of Transformer-based Models on Machine-Generated Text Detection
Apr 05, 2024This paper presents the MasonTigers entry to the SemEval-2024 Task 8 - Multigenerator, Multidomain, and Multilingual Black-Box Machine-Generated Text Detection. The task encompasses Binary Human-Written vs. Machine-Generated Text Classification (Track A), Multi-Way Machine-Generated Text Classification (Track B), and Human-Machine Mixed Text Detection (Track C). Our best performing approaches utilize mainly the ensemble of discriminator transformer models along with sentence transformer and statistical machine learning approaches in specific cases. Moreover, zero-shot prompting and fine-tuning of FLAN-T5 are used for Track A and B.
Extracting Social Determinants of Health from Pediatric Patient Notes Using Large Language Models: Novel Corpus and Methods
Apr 04, 2024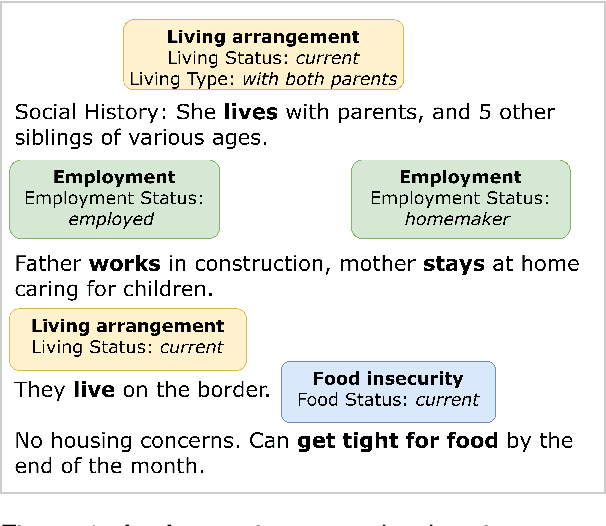
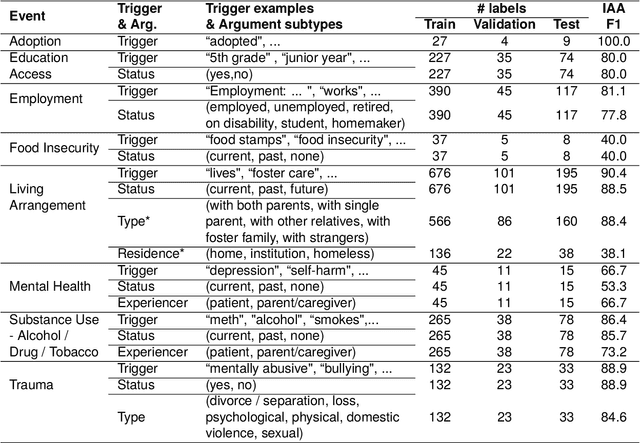
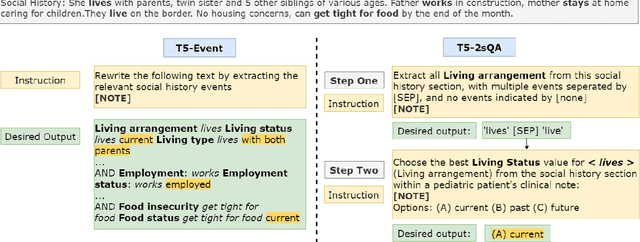
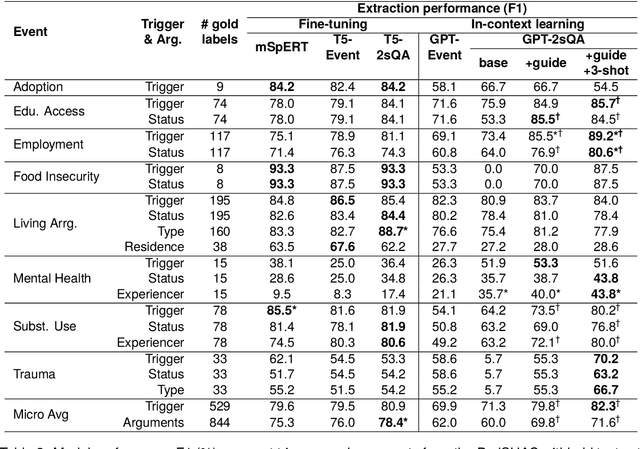
Social determinants of health (SDoH) play a critical role in shaping health outcomes, particularly in pediatric populations where interventions can have long-term implications. SDoH are frequently studied in the Electronic Health Record (EHR), which provides a rich repository for diverse patient data. In this work, we present a novel annotated corpus, the Pediatric Social History Annotation Corpus (PedSHAC), and evaluate the automatic extraction of detailed SDoH representations using fine-tuned and in-context learning methods with Large Language Models (LLMs). PedSHAC comprises annotated social history sections from 1,260 clinical notes obtained from pediatric patients within the University of Washington (UW) hospital system. Employing an event-based annotation scheme, PedSHAC captures ten distinct health determinants to encompass living and economic stability, prior trauma, education access, substance use history, and mental health with an overall annotator agreement of 81.9 F1. Our proposed fine-tuning LLM-based extractors achieve high performance at 78.4 F1 for event arguments. In-context learning approaches with GPT-4 demonstrate promise for reliable SDoH extraction with limited annotated examples, with extraction performance at 82.3 F1 for event triggers.
A Novel Corpus of Annotated Medical Imaging Reports and Information Extraction Results Using BERT-based Language Models
Mar 27, 2024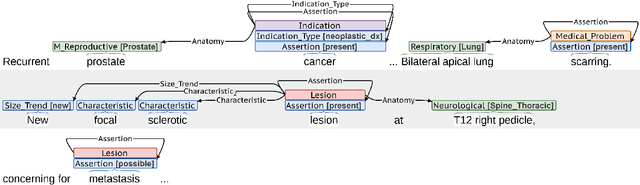
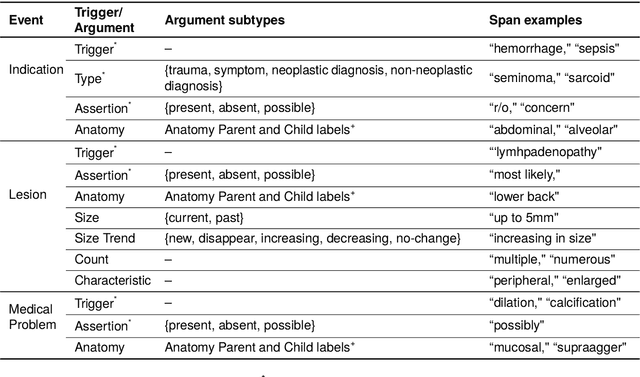
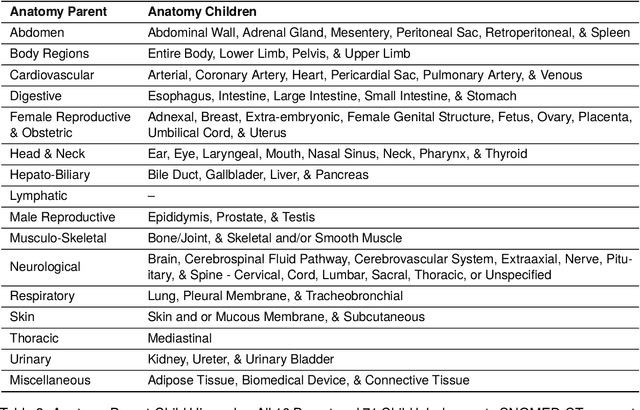
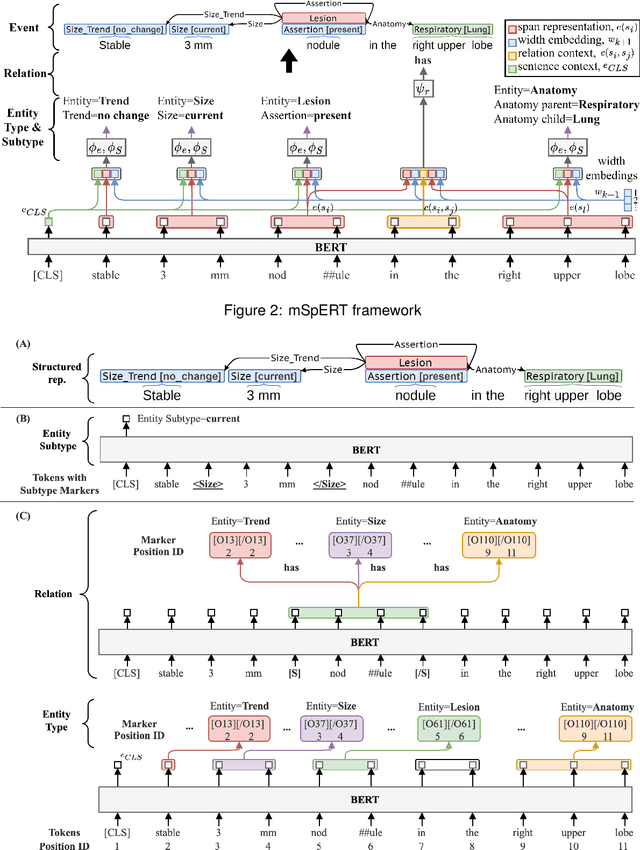
Medical imaging is critical to the diagnosis, surveillance, and treatment of many health conditions, including oncological, neurological, cardiovascular, and musculoskeletal disorders, among others. Radiologists interpret these complex, unstructured images and articulate their assessments through narrative reports that remain largely unstructured. This unstructured narrative must be converted into a structured semantic representation to facilitate secondary applications such as retrospective analyses or clinical decision support. Here, we introduce the Corpus of Annotated Medical Imaging Reports (CAMIR), which includes 609 annotated radiology reports from three imaging modality types: Computed Tomography, Magnetic Resonance Imaging, and Positron Emission Tomography-Computed Tomography. Reports were annotated using an event-based schema that captures clinical indications, lesions, and medical problems. Each event consists of a trigger and multiple arguments, and a majority of the argument types, including anatomy, normalize the spans to pre-defined concepts to facilitate secondary use. CAMIR uniquely combines a granular event structure and concept normalization. To extract CAMIR events, we explored two BERT (Bi-directional Encoder Representation from Transformers)-based architectures, including an existing architecture (mSpERT) that jointly extracts all event information and a multi-step approach (PL-Marker++) that we augmented for the CAMIR schema.
MASON-NLP at eRisk 2023: Deep Learning-Based Detection of Depression Symptoms from Social Media Texts
Oct 17, 2023


Depression is a mental health disorder that has a profound impact on people's lives. Recent research suggests that signs of depression can be detected in the way individuals communicate, both through spoken words and written texts. In particular, social media posts are a rich and convenient text source that we may examine for depressive symptoms. The Beck Depression Inventory (BDI) Questionnaire, which is frequently used to gauge the severity of depression, is one instrument that can aid in this study. We can narrow our study to only those symptoms since each BDI question is linked to a particular depressive symptom. It's important to remember that not everyone with depression exhibits all symptoms at once, but rather a combination of them. Therefore, it is extremely useful to be able to determine if a sentence or a piece of user-generated content is pertinent to a certain condition. With this in mind, the eRisk 2023 Task 1 was designed to do exactly that: assess the relevance of different sentences to the symptoms of depression as outlined in the BDI questionnaire. This report is all about how our team, Mason-NLP, participated in this subtask, which involved identifying sentences related to different depression symptoms. We used a deep learning approach that incorporated MentalBERT, RoBERTa, and LSTM. Despite our efforts, the evaluation results were lower than expected, underscoring the challenges inherent in ranking sentences from an extensive dataset about depression, which necessitates both appropriate methodological choices and significant computational resources. We anticipate that future iterations of this shared task will yield improved results as our understanding and techniques evolve.
MasonNLP+ at SemEval-2023 Task 8: Extracting Medical Questions, Experiences and Claims from Social Media using Knowledge-Augmented Pre-trained Language Models
Apr 26, 2023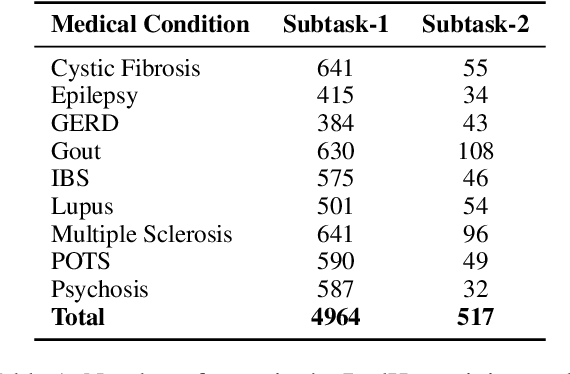



In online forums like Reddit, users share their experiences with medical conditions and treatments, including making claims, asking questions, and discussing the effects of treatments on their health. Building systems to understand this information can effectively monitor the spread of misinformation and verify user claims. The Task-8 of the 2023 International Workshop on Semantic Evaluation focused on medical applications, specifically extracting patient experience- and medical condition-related entities from user posts on social media. The Reddit Health Online Talk (RedHot) corpus contains posts from medical condition-related subreddits with annotations characterizing the patient experience and medical conditions. In Subtask-1, patient experience is characterized by personal experience, questions, and claims. In Subtask-2, medical conditions are characterized by population, intervention, and outcome. For the automatic extraction of patient experiences and medical condition information, as a part of the challenge, we proposed language-model-based extraction systems that ranked $3^{rd}$ on both subtasks' leaderboards. In this work, we describe our approach and, in addition, explore the automatic extraction of this information using domain-specific language models and the inclusion of external knowledge.
LeafAI: query generator for clinical cohort discovery rivaling a human programmer
Apr 13, 2023



Objective: Identifying study-eligible patients within clinical databases is a critical step in clinical research. However, accurate query design typically requires extensive technical and biomedical expertise. We sought to create a system capable of generating data model-agnostic queries while also providing novel logical reasoning capabilities for complex clinical trial eligibility criteria. Materials and Methods: The task of query creation from eligibility criteria requires solving several text-processing problems, including named entity recognition and relation extraction, sequence-to-sequence transformation, normalization, and reasoning. We incorporated hybrid deep learning and rule-based modules for these, as well as a knowledge base of the Unified Medical Language System (UMLS) and linked ontologies. To enable data-model agnostic query creation, we introduce a novel method for tagging database schema elements using UMLS concepts. To evaluate our system, called LeafAI, we compared the capability of LeafAI to a human database programmer to identify patients who had been enrolled in 8 clinical trials conducted at our institution. We measured performance by the number of actual enrolled patients matched by generated queries. Results: LeafAI matched a mean 43% of enrolled patients with 27,225 eligible across 8 clinical trials, compared to 27% matched and 14,587 eligible in queries by a human database programmer. The human programmer spent 26 total hours crafting queries compared to several minutes by LeafAI. Conclusions: Our work contributes a state-of-the-art data model-agnostic query generation system capable of conditional reasoning using a knowledge base. We demonstrate that LeafAI can rival a human programmer in finding patients eligible for clinical trials.