 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Data Contamination Detection Work (Well) for LLMs? A Survey and Evaluation on Detection Assumptions
Paper and Code
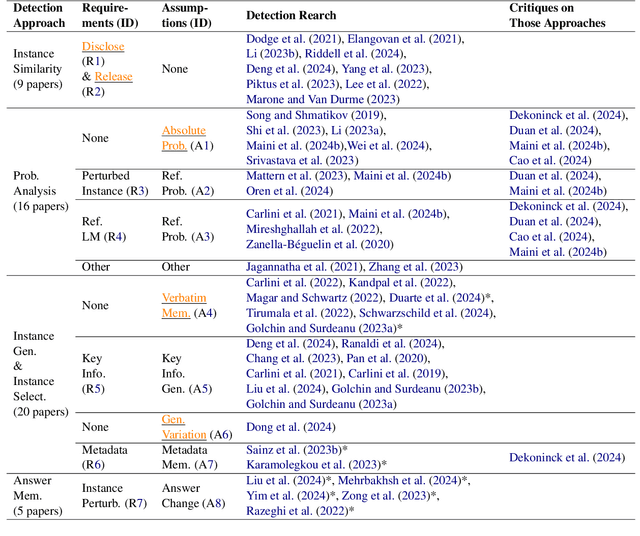
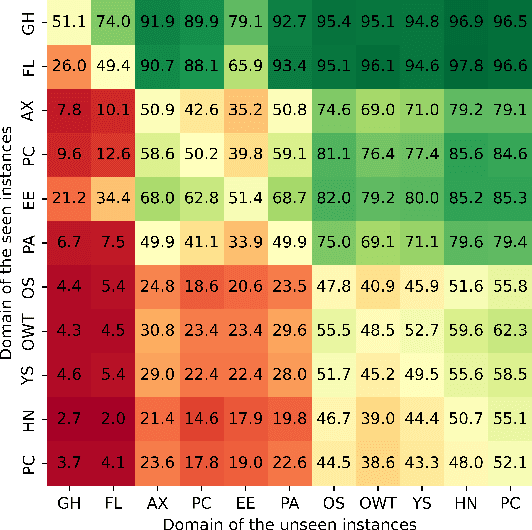
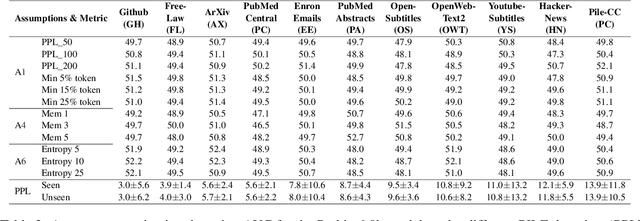
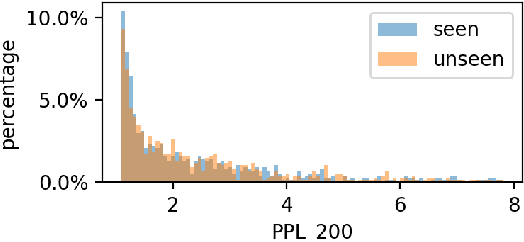
Large language models (LLMs) have demonstrated great performance across various benchmarks, showing potential as general-purpose task solvers. However, as LLMs are typically trained on vast amounts of data, a significant concern in their evaluation is data contamination, where overlap between training data and evaluation datasets inflates performance assessments. While multiple approaches have been developed to identify data contamination, these approaches rely on specific assumptions that may not hold universally across different settings. To bridge this gap, we systematically review 47 papers on data contamination detection, categorize the underlying assumptions, and assess whether they have been rigorously validated. We identify and analyze eight categories of assumptions and test three of them as case studies. Our analysis reveals that when classifying instances used for pretraining LLMs, detection approaches based on these three assumptions perform close to random guessing, suggesting that current LLMs learn data distributions rather than memorizing individual instances. Overall, this work underscores the importance of approaches clearly stating their underlying assumptions and testing their validity across various scenarios.