 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMASON-NLP at eRisk 2023: Deep Learning-Based Detection of Depression Symptoms from Social Media Texts
Oct 17, 2023


Depression is a mental health disorder that has a profound impact on people's lives. Recent research suggests that signs of depression can be detected in the way individuals communicate, both through spoken words and written texts. In particular, social media posts are a rich and convenient text source that we may examine for depressive symptoms. The Beck Depression Inventory (BDI) Questionnaire, which is frequently used to gauge the severity of depression, is one instrument that can aid in this study. We can narrow our study to only those symptoms since each BDI question is linked to a particular depressive symptom. It's important to remember that not everyone with depression exhibits all symptoms at once, but rather a combination of them. Therefore, it is extremely useful to be able to determine if a sentence or a piece of user-generated content is pertinent to a certain condition. With this in mind, the eRisk 2023 Task 1 was designed to do exactly that: assess the relevance of different sentences to the symptoms of depression as outlined in the BDI questionnaire. This report is all about how our team, Mason-NLP, participated in this subtask, which involved identifying sentences related to different depression symptoms. We used a deep learning approach that incorporated MentalBERT, RoBERTa, and LSTM. Despite our efforts, the evaluation results were lower than expected, underscoring the challenges inherent in ranking sentences from an extensive dataset about depression, which necessitates both appropriate methodological choices and significant computational resources. We anticipate that future iterations of this shared task will yield improved results as our understanding and techniques evolve.
Intent Detection and Slot Filling for Home Assistants: Dataset and Analysis for Bangla and Sylheti
Oct 17, 2023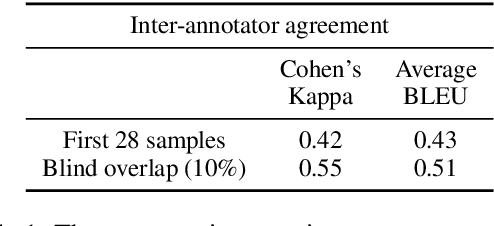
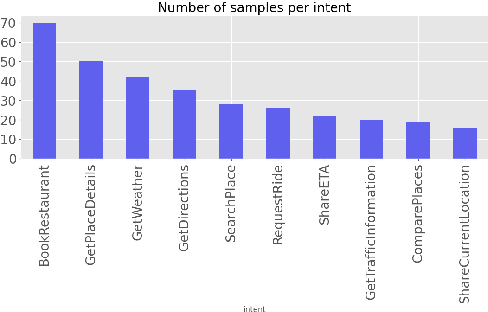
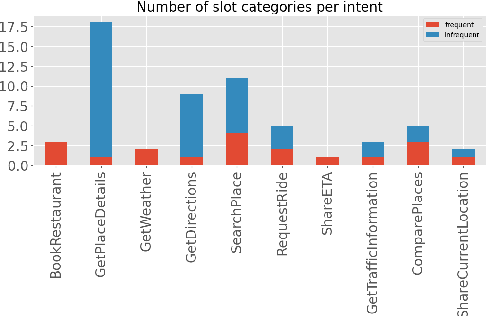
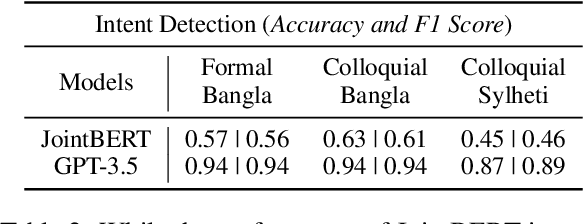
As voice assistants cement their place in our technologically advanced society, there remains a need to cater to the diverse linguistic landscape, including colloquial forms of low-resource languages. Our study introduces the first-ever comprehensive dataset for intent detection and slot filling in formal Bangla, colloquial Bangla, and Sylheti languages, totaling 984 samples across 10 unique intents. Our analysis reveals the robustness of large language models for tackling downstream tasks with inadequate data. The GPT-3.5 model achieves an impressive F1 score of 0.94 in intent detection and 0.51 in slot filling for colloquial Bangla.
To token or not to token: A Comparative Study of Text Representations for Cross-Lingual Transfer
Oct 12, 2023



Choosing an appropriate tokenization scheme is often a bottleneck in low-resource cross-lingual transfer. To understand the downstream implications of text representation choices, we perform a comparative analysis on language models having diverse text representation modalities including 2 segmentation-based models (\texttt{BERT}, \texttt{mBERT}), 1 image-based model (\texttt{PIXEL}), and 1 character-level model (\texttt{CANINE}). First, we propose a scoring Language Quotient (LQ) metric capable of providing a weighted representation of both zero-shot and few-shot evaluation combined. Utilizing this metric, we perform experiments comprising 19 source languages and 133 target languages on three tasks (POS tagging, Dependency parsing, and NER). Our analysis reveals that image-based models excel in cross-lingual transfer when languages are closely related and share visually similar scripts. However, for tasks biased toward word meaning (POS, NER), segmentation-based models prove to be superior. Furthermore, in dependency parsing tasks where word relationships play a crucial role, models with their character-level focus, outperform others. Finally, we propose a recommendation scheme based on our findings to guide model selection according to task and language requirements.
Extending the Frontier of ChatGPT: Code Generation and Debugging
Jul 17, 2023Large-scale language models (LLMs) have emerged as a groundbreaking innovation in the realm of question-answering and conversational agents. These models, leveraging different deep learning architectures such as Transformers, are trained on vast corpora to predict sentences based on given queries. Among these LLMs, ChatGPT, developed by OpenAI, has ushered in a new era by utilizing artificial intelligence (AI) to tackle diverse problem domains, ranging from composing essays and biographies to solving intricate mathematical integrals. The versatile applications enabled by ChatGPT offer immense value to users. However, assessing the performance of ChatGPT's output poses a challenge, particularly in scenarios where queries lack clear objective criteria for correctness. For instance, evaluating the quality of generated essays becomes arduous and relies heavily on manual labor, in stark contrast to evaluating solutions to well-defined, closed-ended questions such as mathematical problems. This research paper delves into the efficacy of ChatGPT in solving programming problems, examining both the correctness and the efficiency of its solution in terms of time and memory complexity. The research reveals a commendable overall success rate of 71.875\%, denoting the proportion of problems for which ChatGPT was able to provide correct solutions that successfully satisfied all the test cases present in Leetcode. It exhibits strengths in structured problems and shows a linear correlation between its success rate and problem acceptance rates. However, it struggles to improve solutions based on feedback, pointing to potential shortcomings in debugging tasks. These findings provide a compact yet insightful glimpse into ChatGPT's capabilities and areas for improvement.
Predicting User-specific Future Activities using LSTM-based Multi-label Classification
Nov 06, 2022User-specific future activity prediction in the healthcare domain based on previous activities can drastically improve the services provided by the nurses. It is challenging because, unlike other domains, activities in healthcare involve both nurses and patients, and they also vary from hour to hour. In this paper, we employ various data processing techniques to organize and modify the data structure and an LSTM-based multi-label classifier for a novel 2-stage training approach (user-agnostic pre-training and user-specific fine-tuning). Our experiment achieves a validation accuracy of 31.58\%, precision 57.94%, recall 68.31%, and F1 score 60.38%. We concluded that proper data pre-processing and a 2-stage training process resulted in better performance. This experiment is a part of the "Fourth Nurse Care Activity Recognition Challenge" by our team "Not A Fan of Local Minima".