 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDF-RAG: Query-Aware Diversity for Retrieval-Augmented Generation
Jan 23, 2026Retrieval-augmented generation (RAG) is a common technique for grounding language model outputs in domain-specific information. However, RAG is often challenged by reasoning-intensive question-answering (QA), since common retrieval methods like cosine similarity maximize relevance at the cost of introducing redundant content, which can reduce information recall. To address this, we introduce Diversity-Focused Retrieval-Augmented Generation (DF-RAG), which systematically incorporates diversity into the retrieval step to improve performance on complex, reasoning-intensive QA benchmarks. DF-RAG builds upon the Maximal Marginal Relevance framework to select information chunks that are both relevant to the query and maximally dissimilar from each other. A key innovation of DF-RAG is its ability to optimize the level of diversity for each query dynamically at test time without requiring any additional fine-tuning or prior information. We show that DF-RAG improves F1 performance on reasoning-intensive QA benchmarks by 4-10 percent over vanilla RAG using cosine similarity and also outperforms other established baselines. Furthermore, we estimate an Oracle ceiling of up to 18 percent absolute F1 gains over vanilla RAG, of which DF-RAG captures up to 91.3 percent.
Intent Detection and Slot Filling for Home Assistants: Dataset and Analysis for Bangla and Sylheti
Oct 17, 2023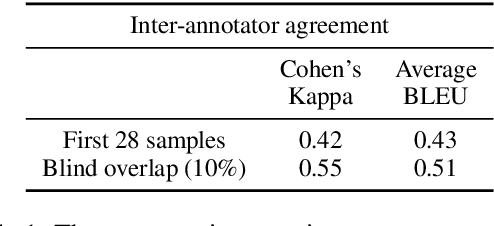
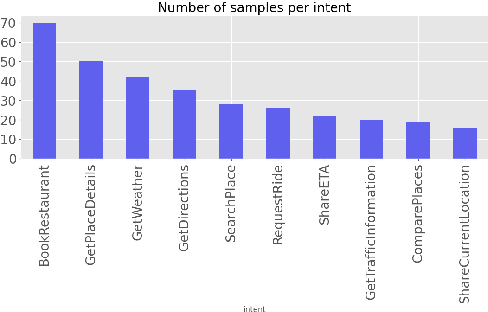
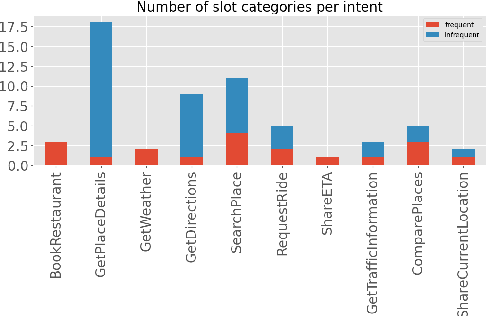
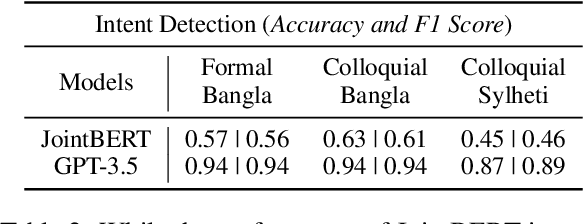
As voice assistants cement their place in our technologically advanced society, there remains a need to cater to the diverse linguistic landscape, including colloquial forms of low-resource languages. Our study introduces the first-ever comprehensive dataset for intent detection and slot filling in formal Bangla, colloquial Bangla, and Sylheti languages, totaling 984 samples across 10 unique intents. Our analysis reveals the robustness of large language models for tackling downstream tasks with inadequate data. The GPT-3.5 model achieves an impressive F1 score of 0.94 in intent detection and 0.51 in slot filling for colloquial Bangla.
Extending the Frontier of ChatGPT: Code Generation and Debugging
Jul 17, 2023Large-scale language models (LLMs) have emerged as a groundbreaking innovation in the realm of question-answering and conversational agents. These models, leveraging different deep learning architectures such as Transformers, are trained on vast corpora to predict sentences based on given queries. Among these LLMs, ChatGPT, developed by OpenAI, has ushered in a new era by utilizing artificial intelligence (AI) to tackle diverse problem domains, ranging from composing essays and biographies to solving intricate mathematical integrals. The versatile applications enabled by ChatGPT offer immense value to users. However, assessing the performance of ChatGPT's output poses a challenge, particularly in scenarios where queries lack clear objective criteria for correctness. For instance, evaluating the quality of generated essays becomes arduous and relies heavily on manual labor, in stark contrast to evaluating solutions to well-defined, closed-ended questions such as mathematical problems. This research paper delves into the efficacy of ChatGPT in solving programming problems, examining both the correctness and the efficiency of its solution in terms of time and memory complexity. The research reveals a commendable overall success rate of 71.875\%, denoting the proportion of problems for which ChatGPT was able to provide correct solutions that successfully satisfied all the test cases present in Leetcode. It exhibits strengths in structured problems and shows a linear correlation between its success rate and problem acceptance rates. However, it struggles to improve solutions based on feedback, pointing to potential shortcomings in debugging tasks. These findings provide a compact yet insightful glimpse into ChatGPT's capabilities and areas for improvement.