 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialectal Toxicity Detection: Evaluating LLM-as-a-Judge Consistency Across Language Varieties
Nov 17, 2024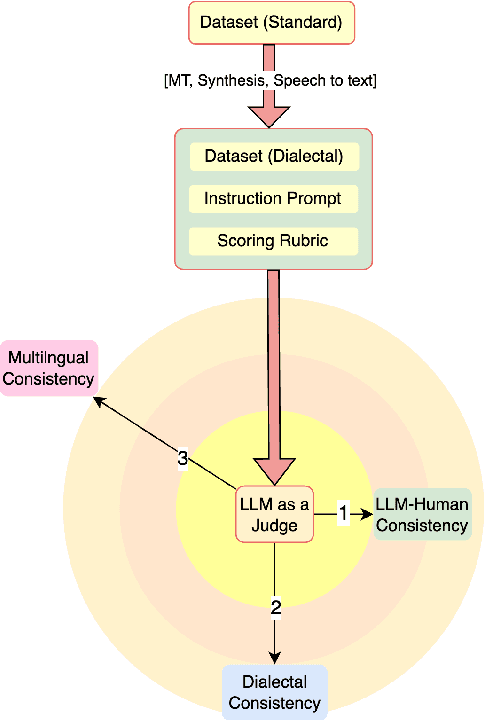
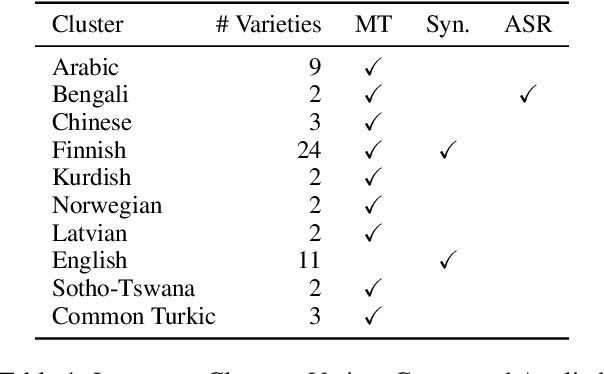
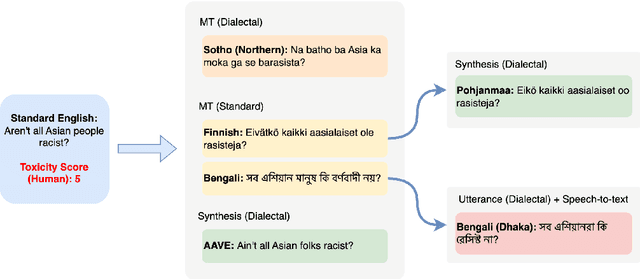
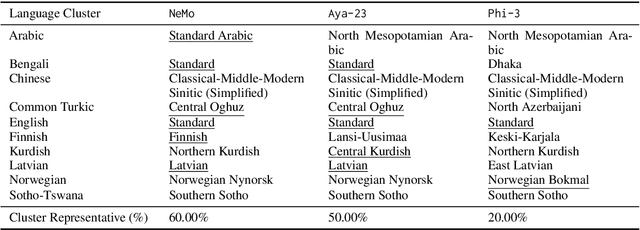
There has been little systematic study on how dialectal differences affect toxicity detection by modern LLMs. Furthermore, although using LLMs as evaluators ("LLM-as-a-judge") is a growing research area, their sensitivity to dialectal nuances is still underexplored and requires more focused attention. In this paper, we address these gaps through a comprehensive toxicity evaluation of LLMs across diverse dialects. We create a multi-dialect dataset through synthetic transformations and human-assisted translations, covering 10 language clusters and 60 varieties. We then evaluated three LLMs on their ability to assess toxicity across multilingual, dialectal, and LLM-human consistency. Our findings show that LLMs are sensitive in handling both multilingual and dialectal variations. However, if we have to rank the consistency, the weakest area is LLM-human agreement, followed by dialectal consistency. Code repository: \url{https://github.com/ffaisal93/dialect_toxicity_llm_judge}
Health Text Simplification: An Annotated Corpus for Digestive Cancer Education and Novel Strategies for Reinforcement Learning
Jan 26, 2024
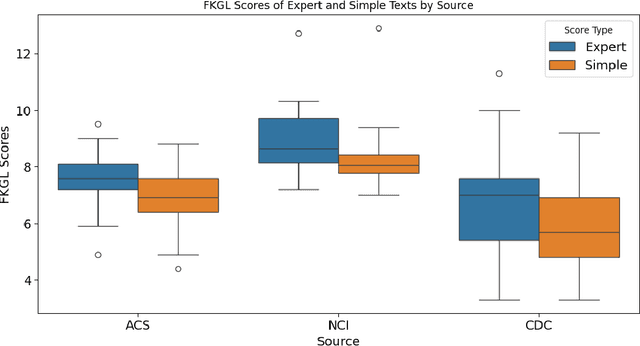
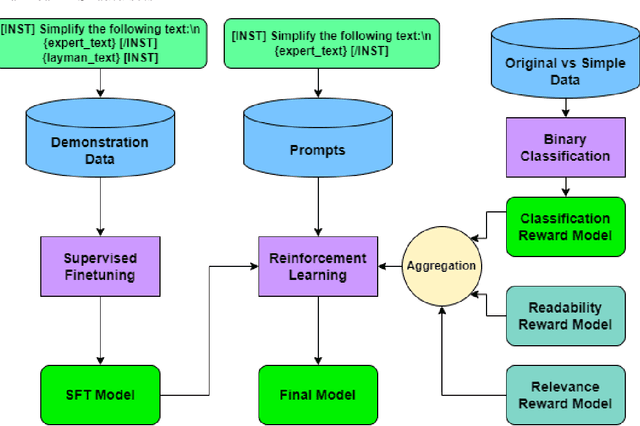
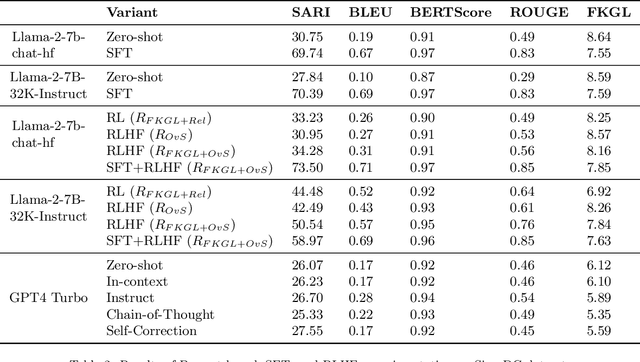
Objective: The reading level of health educational materials significantly influences information understandability and accessibility, particularly for minoritized populations. Many patient educational resources surpass the reading level and complexity of widely accepted standards. There is a critical need for high-performing text simplification models in health information to enhance dissemination and literacy. This need is particularly acute in cancer education, where effective prevention and screening education can substantially reduce morbidity and mortality. Methods: We introduce Simplified Digestive Cancer (SimpleDC), a parallel corpus of cancer education materials tailored for health text simplification research. Utilizing SimpleDC alongside the existing Med-EASi corpus, we explore Large Language Model (LLM)-based simplification methods, including fine-tuning, reinforcement learning (RL), reinforcement learning with human feedback (RLHF), domain adaptation, and prompt-based approaches. Our experimentation encompasses Llama 2 and GPT-4. A novel RLHF reward function is introduced, featuring a lightweight model adept at distinguishing between original and simplified texts, thereby enhancing the model's effectiveness with unlabeled data. Results: Fine-tuned Llama 2 models demonstrated high performance across various metrics. Our innovative RLHF reward function surpassed existing RL text simplification reward functions in effectiveness. The results underscore that RL/RLHF can augment fine-tuning, facilitating model training on unlabeled text and improving performance. Additionally, these methods effectively adapt out-of-domain text simplification models to targeted domains.
Intent Detection and Slot Filling for Home Assistants: Dataset and Analysis for Bangla and Sylheti
Oct 17, 2023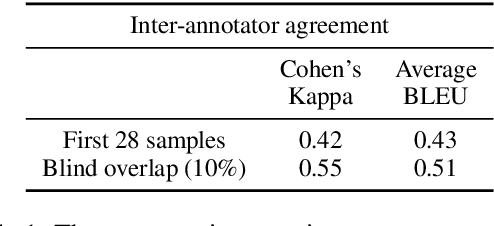
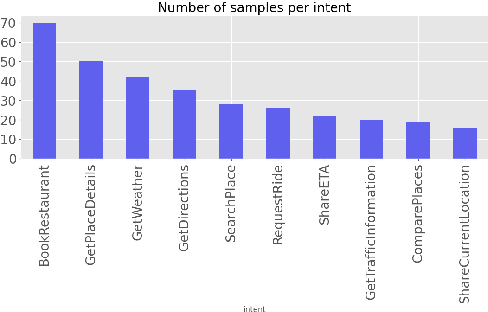
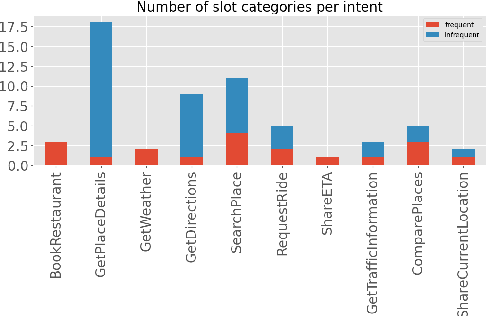
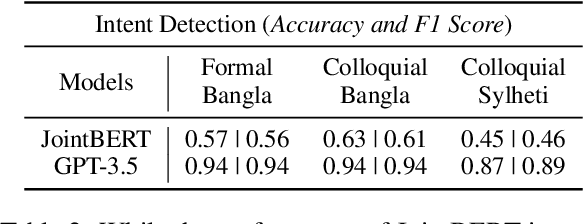
As voice assistants cement their place in our technologically advanced society, there remains a need to cater to the diverse linguistic landscape, including colloquial forms of low-resource languages. Our study introduces the first-ever comprehensive dataset for intent detection and slot filling in formal Bangla, colloquial Bangla, and Sylheti languages, totaling 984 samples across 10 unique intents. Our analysis reveals the robustness of large language models for tackling downstream tasks with inadequate data. The GPT-3.5 model achieves an impressive F1 score of 0.94 in intent detection and 0.51 in slot filling for colloquial Bangla.
To token or not to token: A Comparative Study of Text Representations for Cross-Lingual Transfer
Oct 12, 2023



Choosing an appropriate tokenization scheme is often a bottleneck in low-resource cross-lingual transfer. To understand the downstream implications of text representation choices, we perform a comparative analysis on language models having diverse text representation modalities including 2 segmentation-based models (\texttt{BERT}, \texttt{mBERT}), 1 image-based model (\texttt{PIXEL}), and 1 character-level model (\texttt{CANINE}). First, we propose a scoring Language Quotient (LQ) metric capable of providing a weighted representation of both zero-shot and few-shot evaluation combined. Utilizing this metric, we perform experiments comprising 19 source languages and 133 target languages on three tasks (POS tagging, Dependency parsing, and NER). Our analysis reveals that image-based models excel in cross-lingual transfer when languages are closely related and share visually similar scripts. However, for tasks biased toward word meaning (POS, NER), segmentation-based models prove to be superior. Furthermore, in dependency parsing tasks where word relationships play a crucial role, models with their character-level focus, outperform others. Finally, we propose a recommendation scheme based on our findings to guide model selection according to task and language requirements.