 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing AI Trustworthiness Through Patient Simulation: Risk Assessment of Conversational Agents for Antidepressant Selection
Feb 11, 2026Objective: This paper introduces a patient simulator designed to enable scalable, automated evaluation of healthcare conversational agents. The simulator generates realistic, controllable patient interactions that systematically vary across medical, linguistic, and behavioral dimensions, allowing annotators and an independent AI judge to assess agent performance, identify hallucinations and inaccuracies, and characterize risk patterns across diverse patient populations. Methods: The simulator is grounded in the NIST AI Risk Management Framework and integrates three profile components reflecting different dimensions of patient variation: (1) medical profiles constructed from electronic health records in the All of Us Research Program; (2) linguistic profiles modeling variation in health literacy and condition-specific communication patterns; and (3) behavioral profiles representing empirically observed interaction patterns, including cooperation, distraction, and adversarial engagement. We evaluated the simulator's effectiveness in identifying errors in an AI decision aid for antidepressant selection. Results: We generated 500 conversations between the patient simulator and the AI decision aid across systematic combinations of five linguistic and three behavioral profiles. Human annotators assessed 1,787 medical concepts across 100 conversations, achieving high agreement (F1=0.94, \k{appa}=0.73), and the LLM judge achieved comparable agreement with human annotators (F1=0.94, \k{appa}=0.78; paired bootstrap p=0.21). The simulator revealed a monotonic degradation in AI decision aid performance across the health literacy spectrum: rank-one concept retrieval accuracy increased from 47.9% for limited health literacy to 69.1% for functional and 81.6% for proficient.
Health Text Simplification: An Annotated Corpus for Digestive Cancer Education and Novel Strategies for Reinforcement Learning
Jan 26, 2024
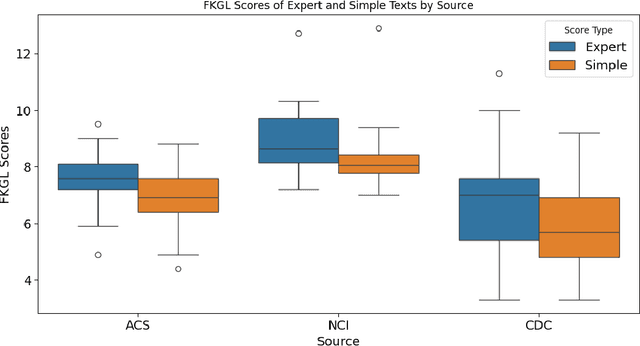
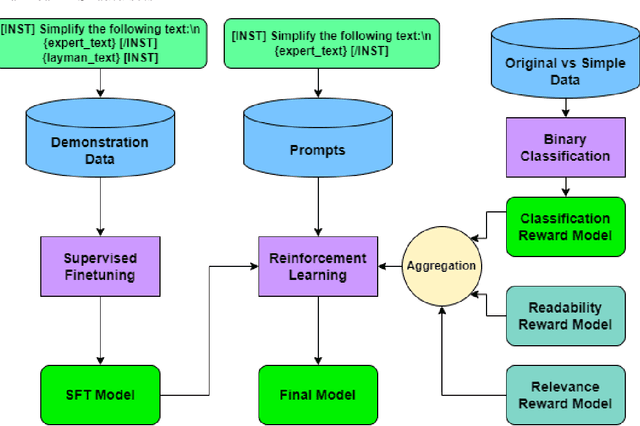
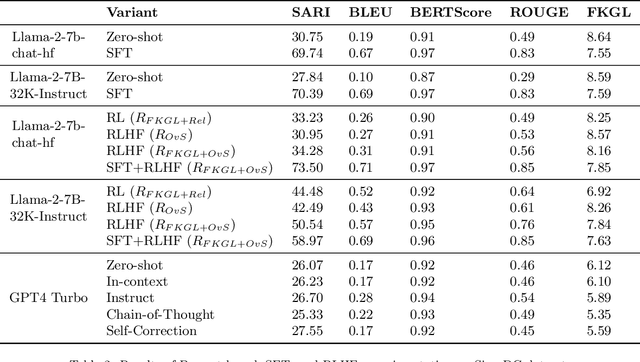
Objective: The reading level of health educational materials significantly influences information understandability and accessibility, particularly for minoritized populations. Many patient educational resources surpass the reading level and complexity of widely accepted standards. There is a critical need for high-performing text simplification models in health information to enhance dissemination and literacy. This need is particularly acute in cancer education, where effective prevention and screening education can substantially reduce morbidity and mortality. Methods: We introduce Simplified Digestive Cancer (SimpleDC), a parallel corpus of cancer education materials tailored for health text simplification research. Utilizing SimpleDC alongside the existing Med-EASi corpus, we explore Large Language Model (LLM)-based simplification methods, including fine-tuning, reinforcement learning (RL), reinforcement learning with human feedback (RLHF), domain adaptation, and prompt-based approaches. Our experimentation encompasses Llama 2 and GPT-4. A novel RLHF reward function is introduced, featuring a lightweight model adept at distinguishing between original and simplified texts, thereby enhancing the model's effectiveness with unlabeled data. Results: Fine-tuned Llama 2 models demonstrated high performance across various metrics. Our innovative RLHF reward function surpassed existing RL text simplification reward functions in effectiveness. The results underscore that RL/RLHF can augment fine-tuning, facilitating model training on unlabeled text and improving performance. Additionally, these methods effectively adapt out-of-domain text simplification models to targeted domains.
Predicting User-specific Future Activities using LSTM-based Multi-label Classification
Nov 06, 2022User-specific future activity prediction in the healthcare domain based on previous activities can drastically improve the services provided by the nurses. It is challenging because, unlike other domains, activities in healthcare involve both nurses and patients, and they also vary from hour to hour. In this paper, we employ various data processing techniques to organize and modify the data structure and an LSTM-based multi-label classifier for a novel 2-stage training approach (user-agnostic pre-training and user-specific fine-tuning). Our experiment achieves a validation accuracy of 31.58\%, precision 57.94%, recall 68.31%, and F1 score 60.38%. We concluded that proper data pre-processing and a 2-stage training process resulted in better performance. This experiment is a part of the "Fourth Nurse Care Activity Recognition Challenge" by our team "Not A Fan of Local Minima".
End-to-End License Plate Recognition Pipeline for Real-time Low Resource Video Based Applications
Aug 18, 2021

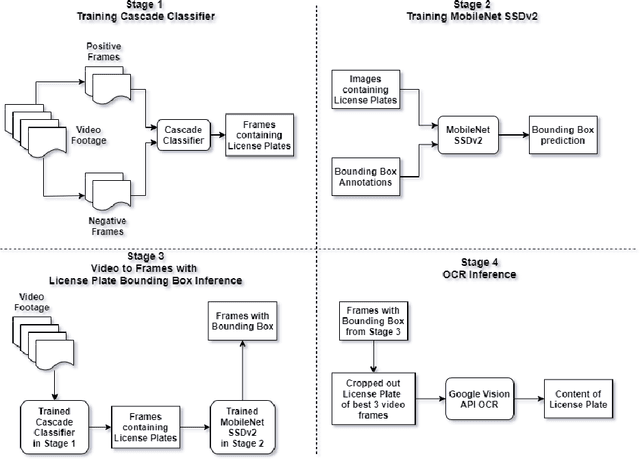
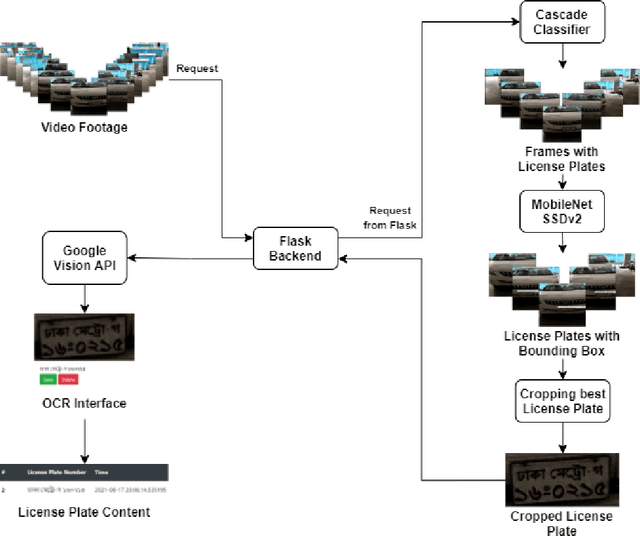
Automatic License Plate Recognition systems aim to provide an end-to-end solution towards detecting, localizing, and recognizing license plate characters from vehicles appearing in video frames. However, deploying such systems in the real world requires real-time performance in low-resource environments. In our paper, we propose a novel two-stage detection pipeline paired with Vision API that aims to provide real-time inference speed along with consistently accurate detection and recognition performance. We used a haar-cascade classifier as a filter on top of our backbone MobileNet SSDv2 detection model. This reduces inference time by only focusing on high confidence detections and using them for recognition. We also impose a temporal frame separation strategy to identify multiple vehicle license plates in the same clip. Furthermore, there are no publicly available Bangla license plate datasets, for which we created an image dataset and a video dataset containing license plates in the wild. We trained our models on the image dataset and achieved an AP(0.5) score of 86% and tested our pipeline on the video dataset and observed reasonable detection and recognition performance (82.7% detection rate, and 60.8% OCR F1 score) with real-time processing speed (27.2 frames per second).
End-to-End Natural Language Understanding Pipeline for Bangla Conversational Agents
Jul 15, 2021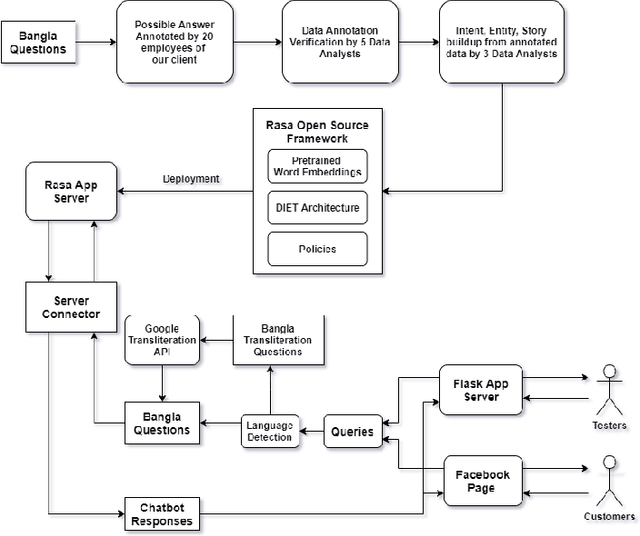
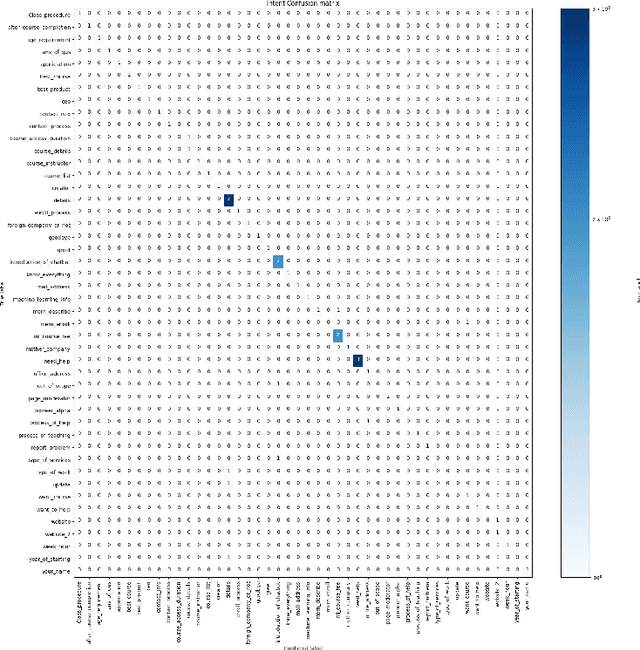
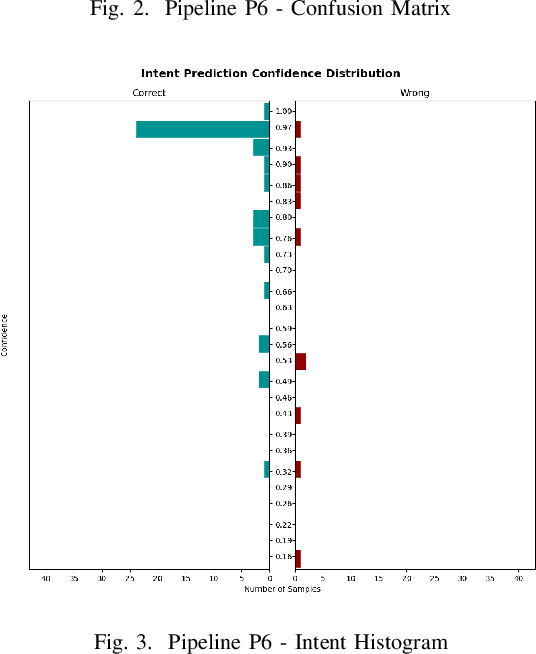
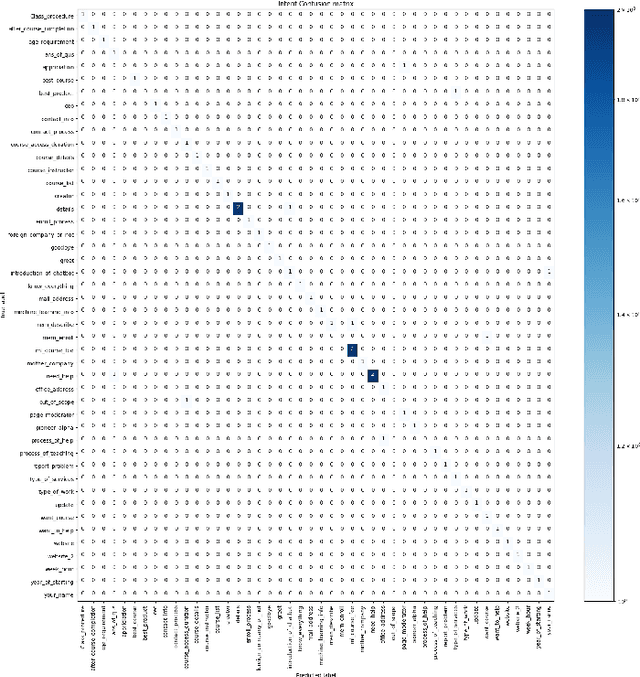
Chatbots are intelligent software built to be used as a replacement for human interaction. However, existing studies typically do not provide enough support for low-resource languages like Bangla. Moreover, due to the increasing popularity of social media, we can also see the rise of interactions in Bangla transliteration (mostly in English) among the native Bangla speakers. In this paper, we propose a novel approach to build a Bangla chatbot aimed to be used as a business assistant which can communicate in Bangla and Bangla Transliteration in English with high confidence consistently. Since annotated data was not available for this purpose, we had to work on the whole machine learning life cycle (data preparation, machine learning modeling, and model deployment) using Rasa Open Source Framework, fastText embeddings, Polyglot embeddings, Flask, and other systems as building blocks. While working with the skewed annotated dataset, we try out different setups and pipelines to evaluate which works best and provide possible reasoning behind the observed results. Finally, we present a pipeline for intent classification and entity extraction which achieves reasonable performance (accuracy: 83.02%, precision: 80.82%, recall: 83.02%, F1-score: 80%).
Real-Time Face Recognition System for Remote Employee Tracking
Jul 15, 2021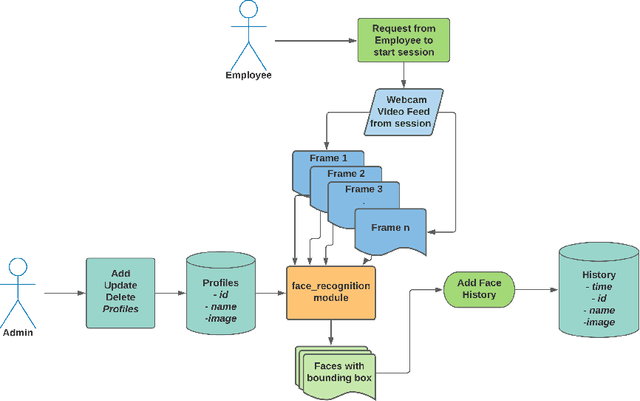
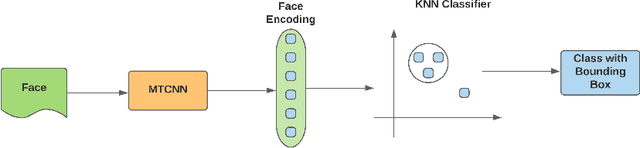
During the COVID-19 pandemic, most of the human-to-human interactions have been stopped. To mitigate the spread of deadly coronavirus, many offices took the initiative so that the employees can work from home. But, tracking the employees and finding out if they are really performing what they were supposed to turn out to be a serious challenge for all the companies and organizations who are facilitating "Work From Home". To deal with the challenge effectively, we came up with a solution to track the employees with face recognition. We have been testing this system experimentally for our office. To train the face recognition module, we used FaceNet with KNN using the Labeled Faces in the Wild (LFW) dataset and achieved 97.8% accuracy. We integrated the trained model into our central system, where the employees log their time. In this paper, we discuss in brief the system we have been experimenting with and the pros and cons of the system.