 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHolistic Continual Learning under Concept Drift with Adaptive Memory Realignment
Jul 03, 2025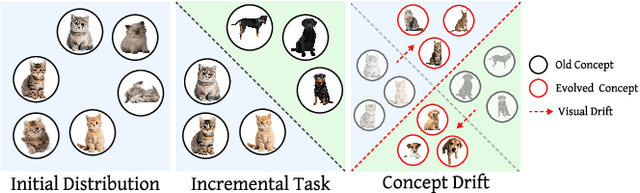
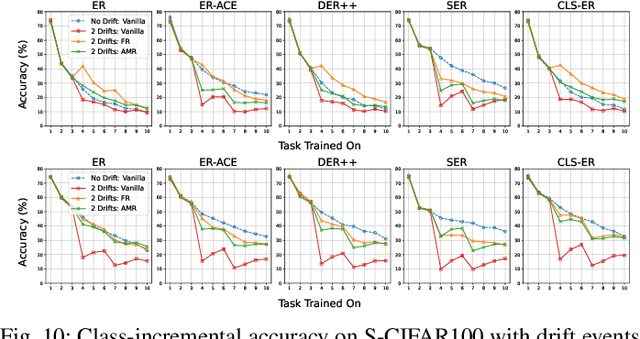
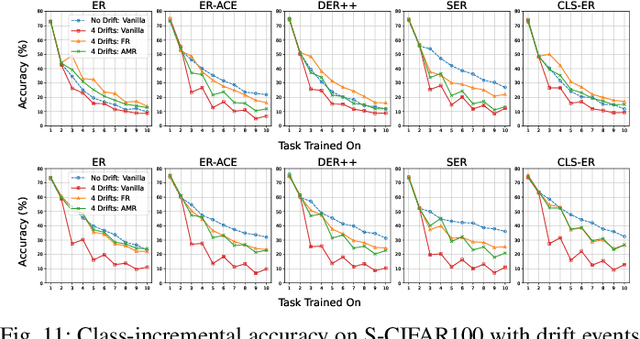
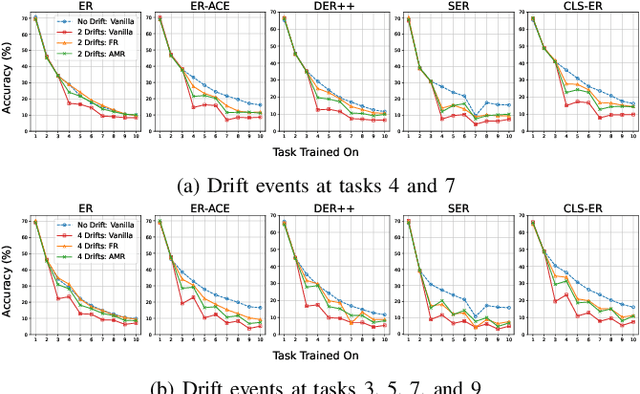
Traditional continual learning methods prioritize knowledge retention and focus primarily on mitigating catastrophic forgetting, implicitly assuming that the data distribution of previously learned tasks remains static. This overlooks the dynamic nature of real-world data streams, where concept drift permanently alters previously seen data and demands both stability and rapid adaptation. We introduce a holistic framework for continual learning under concept drift that simulates realistic scenarios by evolving task distributions. As a baseline, we consider Full Relearning (FR), in which the model is retrained from scratch on newly labeled samples from the drifted distribution. While effective, this approach incurs substantial annotation and computational overhead. To address these limitations, we propose Adaptive Memory Realignment (AMR), a lightweight alternative that equips rehearsal-based learners with a drift-aware adaptation mechanism. AMR selectively removes outdated samples of drifted classes from the replay buffer and repopulates it with a small number of up-to-date instances, effectively realigning memory with the new distribution. This targeted resampling matches the performance of FR while reducing the need for labeled data and computation by orders of magnitude. To enable reproducible evaluation, we introduce four concept-drift variants of standard vision benchmarks: Fashion-MNIST-CD, CIFAR10-CD, CIFAR100-CD, and Tiny-ImageNet-CD, where previously seen classes reappear with shifted representations. Comprehensive experiments on these datasets using several rehearsal-based baselines show that AMR consistently counters concept drift, maintaining high accuracy with minimal overhead. These results position AMR as a scalable solution that reconciles stability and plasticity in non-stationary continual learning environments.
What is the role of memorization in Continual Learning?
May 23, 2025Memorization impacts the performance of deep learning algorithms. Prior works have studied memorization primarily in the context of generalization and privacy. This work studies the memorization effect on incremental learning scenarios. Forgetting prevention and memorization seem similar. However, one should discuss their differences. We designed extensive experiments to evaluate the impact of memorization on continual learning. We clarified that learning examples with high memorization scores are forgotten faster than regular samples. Our findings also indicated that memorization is necessary to achieve the highest performance. However, at low memory regimes, forgetting regular samples is more important. We showed that the importance of a high-memorization score sample rises with an increase in the buffer size. We introduced a memorization proxy and employed it in the buffer policy problem to showcase how memorization could be used during incremental training. We demonstrated that including samples with a higher proxy memorization score is beneficial when the buffer size is large.
AttResDU-Net: Medical Image Segmentation Using Attention-based Residual Double U-Net
Jun 25, 2023Manually inspecting polyps from a colonoscopy for colorectal cancer or performing a biopsy on skin lesions for skin cancer are time-consuming, laborious, and complex procedures. Automatic medical image segmentation aims to expedite this diagnosis process. However, numerous challenges exist due to significant variations in the appearance and sizes of objects with no distinct boundaries. This paper proposes an attention-based residual Double U-Net architecture (AttResDU-Net) that improves on the existing medical image segmentation networks. Inspired by the Double U-Net, this architecture incorporates attention gates on the skip connections and residual connections in the convolutional blocks. The attention gates allow the model to retain more relevant spatial information by suppressing irrelevant feature representation from the down-sampling path for which the model learns to focus on target regions of varying shapes and sizes. Moreover, the residual connections help to train deeper models by ensuring better gradient flow. We conducted experiments on three datasets: CVC Clinic-DB, ISIC 2018, and the 2018 Data Science Bowl datasets and achieved Dice Coefficient scores of 94.35%, 91.68% and 92.45% respectively. Our results suggest that AttResDU-Net can be facilitated as a reliable method for automatic medical image segmentation in practice.
Rethinking Cooking State Recognition with Vision Transformers
Dec 24, 2022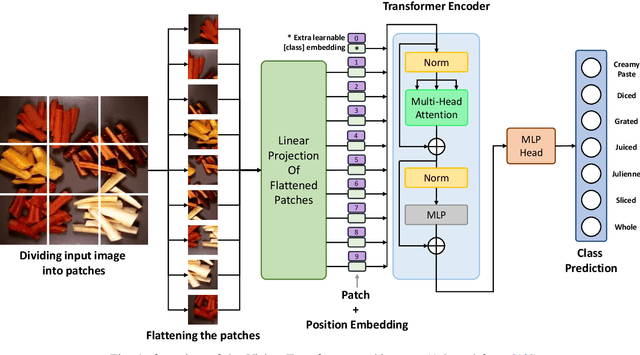

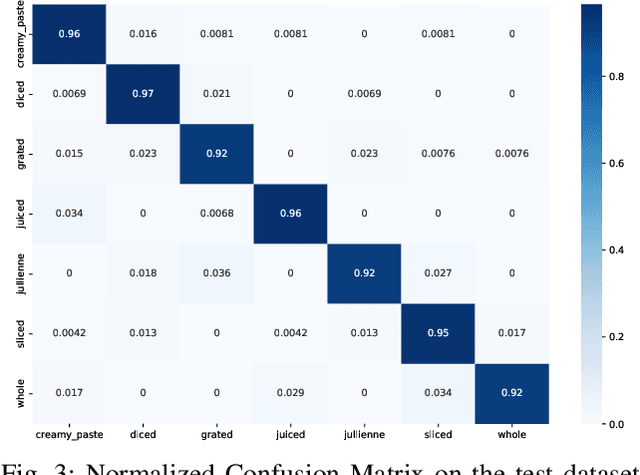
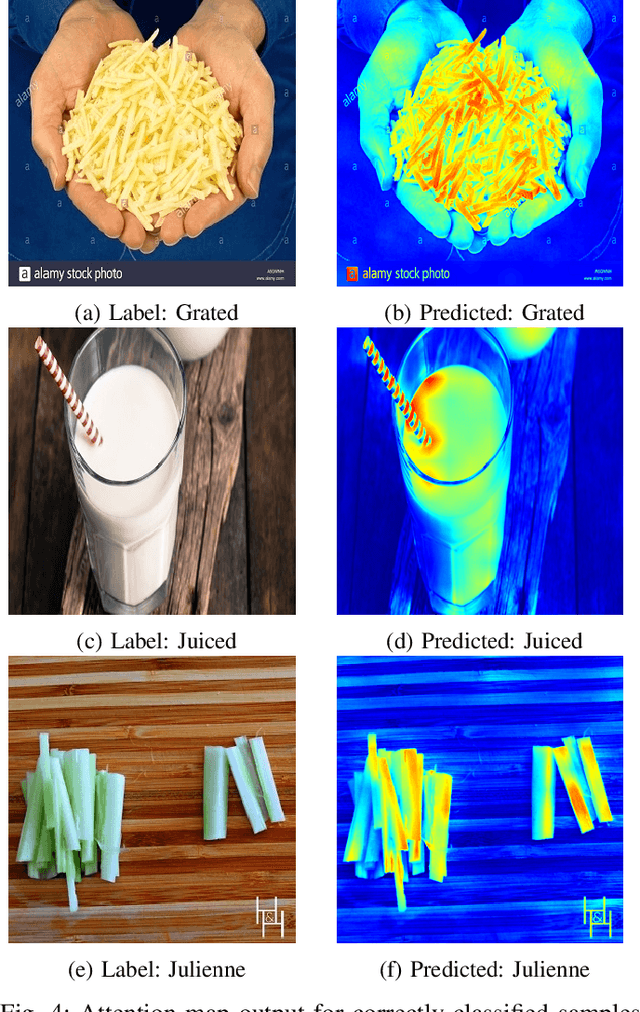
To ensure proper knowledge representation of the kitchen environment, it is vital for kitchen robots to recognize the states of the food items that are being cooked. Although the domain of object detection and recognition has been extensively studied, the task of object state classification has remained relatively unexplored. The high intra-class similarity of ingredients during different states of cooking makes the task even more challenging. Researchers have proposed adopting Deep Learning based strategies in recent times, however, they are yet to achieve high performance. In this study, we utilized the self-attention mechanism of the Vision Transformer (ViT) architecture for the Cooking State Recognition task. The proposed approach encapsulates the globally salient features from images, while also exploiting the weights learned from a larger dataset. This global attention allows the model to withstand the similarities between samples of different cooking objects, while the employment of transfer learning helps to overcome the lack of inductive bias by utilizing pretrained weights. To improve recognition accuracy, several augmentation techniques have been employed as well. Evaluation of our proposed framework on the `Cooking State Recognition Challenge Dataset' has achieved an accuracy of 94.3%, which significantly outperforms the state-of-the-art.
End-to-End License Plate Recognition Pipeline for Real-time Low Resource Video Based Applications
Aug 18, 2021

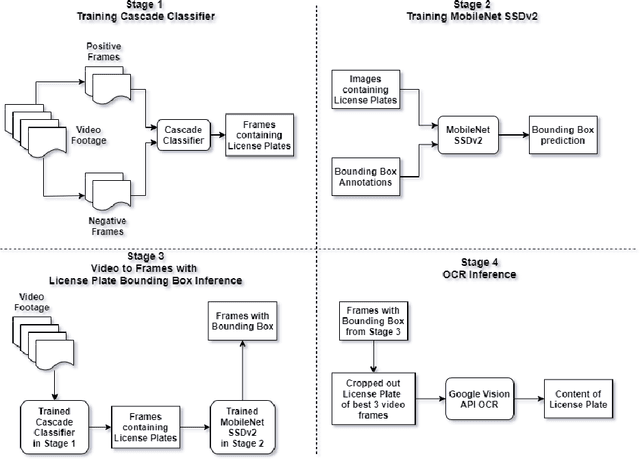
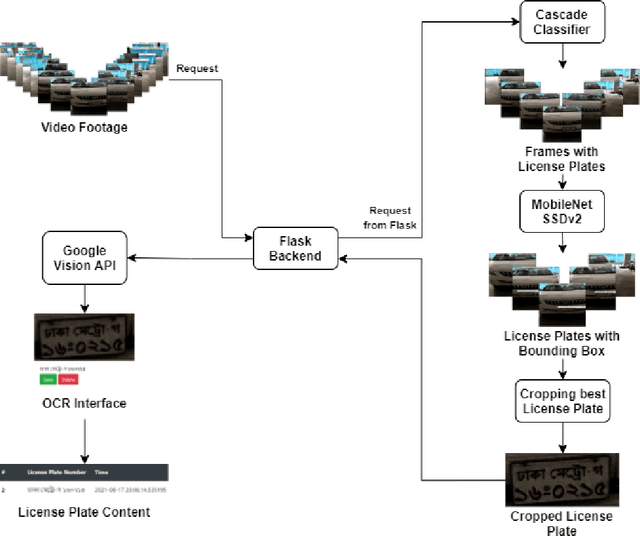
Automatic License Plate Recognition systems aim to provide an end-to-end solution towards detecting, localizing, and recognizing license plate characters from vehicles appearing in video frames. However, deploying such systems in the real world requires real-time performance in low-resource environments. In our paper, we propose a novel two-stage detection pipeline paired with Vision API that aims to provide real-time inference speed along with consistently accurate detection and recognition performance. We used a haar-cascade classifier as a filter on top of our backbone MobileNet SSDv2 detection model. This reduces inference time by only focusing on high confidence detections and using them for recognition. We also impose a temporal frame separation strategy to identify multiple vehicle license plates in the same clip. Furthermore, there are no publicly available Bangla license plate datasets, for which we created an image dataset and a video dataset containing license plates in the wild. We trained our models on the image dataset and achieved an AP(0.5) score of 86% and tested our pipeline on the video dataset and observed reasonable detection and recognition performance (82.7% detection rate, and 60.8% OCR F1 score) with real-time processing speed (27.2 frames per second).