 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Domain-Adapted Lightweight Ensemble for Resource-Efficient Few-Shot Plant Disease Classification
Dec 15, 2025Accurate and timely identification of plant leaf diseases is essential for resilient and sustainable agriculture, yet most deep learning approaches rely on large annotated datasets and computationally intensive models that are unsuitable for data-scarce and resource-constrained environments. To address these challenges we present a few-shot learning approach within a lightweight yet efficient framework that combines domain-adapted MobileNetV2 and MobileNetV3 models as feature extractors, along with a feature fusion technique to generate robust feature representation. For the classification task, the fused features are passed through a Bi-LSTM classifier enhanced with attention mechanisms to capture sequential dependencies and focus on the most relevant features, thereby achieving optimal classification performance even in complex, real-world environments with noisy or cluttered backgrounds. The proposed framework was evaluated across multiple experimental setups, including both laboratory-controlled and field-captured datasets. On tomato leaf diseases from the PlantVillage dataset, it consistently improved performance across 1 to 15 shot scenarios, reaching 98.23+-0.33% at 15 shot, closely approaching the 99.98% SOTA benchmark achieved by a Transductive LSTM with attention, while remaining lightweight and mobile-friendly. Under real-world conditions using field images from the Dhan Shomadhan dataset, it maintained robust performance, reaching 69.28+-1.49% at 15-shot and demonstrating strong resilience to complex backgrounds. Notably, it also outperformed the previous SOTA accuracy of 96.0% on six diseases from PlantVillage, achieving 99.72% with only 15-shot learning. With a compact model size of approximately 40 MB and inference complexity of approximately 1.12 GFLOPs, this work establishes a scalable, mobile-ready foundation for precise plant disease diagnostics in data-scarce regions.
AttResDU-Net: Medical Image Segmentation Using Attention-based Residual Double U-Net
Jun 25, 2023Manually inspecting polyps from a colonoscopy for colorectal cancer or performing a biopsy on skin lesions for skin cancer are time-consuming, laborious, and complex procedures. Automatic medical image segmentation aims to expedite this diagnosis process. However, numerous challenges exist due to significant variations in the appearance and sizes of objects with no distinct boundaries. This paper proposes an attention-based residual Double U-Net architecture (AttResDU-Net) that improves on the existing medical image segmentation networks. Inspired by the Double U-Net, this architecture incorporates attention gates on the skip connections and residual connections in the convolutional blocks. The attention gates allow the model to retain more relevant spatial information by suppressing irrelevant feature representation from the down-sampling path for which the model learns to focus on target regions of varying shapes and sizes. Moreover, the residual connections help to train deeper models by ensuring better gradient flow. We conducted experiments on three datasets: CVC Clinic-DB, ISIC 2018, and the 2018 Data Science Bowl datasets and achieved Dice Coefficient scores of 94.35%, 91.68% and 92.45% respectively. Our results suggest that AttResDU-Net can be facilitated as a reliable method for automatic medical image segmentation in practice.
An Efficient Transfer Learning-based Approach for Apple Leaf Disease Classification
Apr 10, 2023
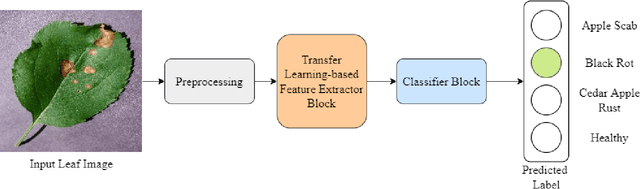
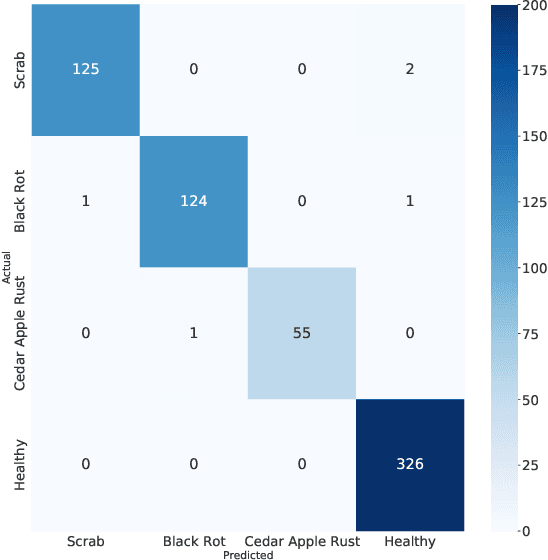
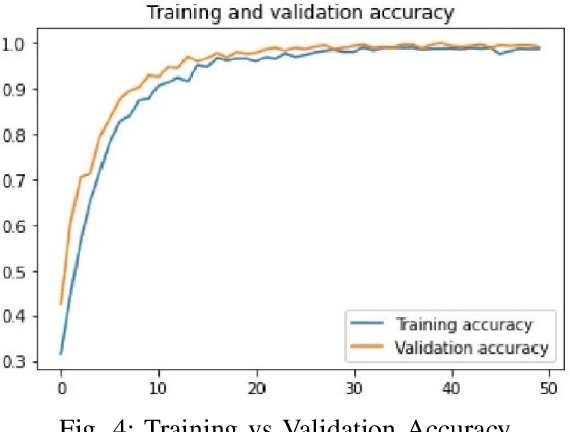
Correct identification and categorization of plant diseases are crucial for ensuring the safety of the global food supply and the overall financial success of stakeholders. In this regard, a wide range of solutions has been made available by introducing deep learning-based classification systems for different staple crops. Despite being one of the most important commercial crops in many parts of the globe, research proposing a smart solution for automatically classifying apple leaf diseases remains relatively unexplored. This study presents a technique for identifying apple leaf diseases based on transfer learning. The system extracts features using a pretrained EfficientNetV2S architecture and passes to a classifier block for effective prediction. The class imbalance issues are tackled by utilizing runtime data augmentation. The effect of various hyperparameters, such as input resolution, learning rate, number of epochs, etc., has been investigated carefully. The competence of the proposed pipeline has been evaluated on the apple leaf disease subset from the publicly available `PlantVillage' dataset, where it achieved an accuracy of 99.21%, outperforming the existing works.
DEPTWEET: A Typology for Social Media Texts to Detect Depression Severities
Oct 10, 2022Mental health research through data-driven methods has been hindered by a lack of standard typology and scarcity of adequate data. In this study, we leverage the clinical articulation of depression to build a typology for social media texts for detecting the severity of depression. It emulates the standard clinical assessment procedure Diagnostic and Statistical Manual of Mental Disorders (DSM-5) and Patient Health Questionnaire (PHQ-9) to encompass subtle indications of depressive disorders from tweets. Along with the typology, we present a new dataset of 40191 tweets labeled by expert annotators. Each tweet is labeled as 'non-depressed' or 'depressed'. Moreover, three severity levels are considered for 'depressed' tweets: (1) mild, (2) moderate, and (3) severe. An associated confidence score is provided with each label to validate the quality of annotation. We examine the quality of the dataset via representing summary statistics while setting strong baseline results using attention-based models like BERT and DistilBERT. Finally, we extensively address the limitations of the study to provide directions for further research.
* 17 pages, 6 figures, 6 tables, Accepted in Computers in Human Behavior
Multiple Object Tracking in Recent Times: A Literature Review
Sep 11, 2022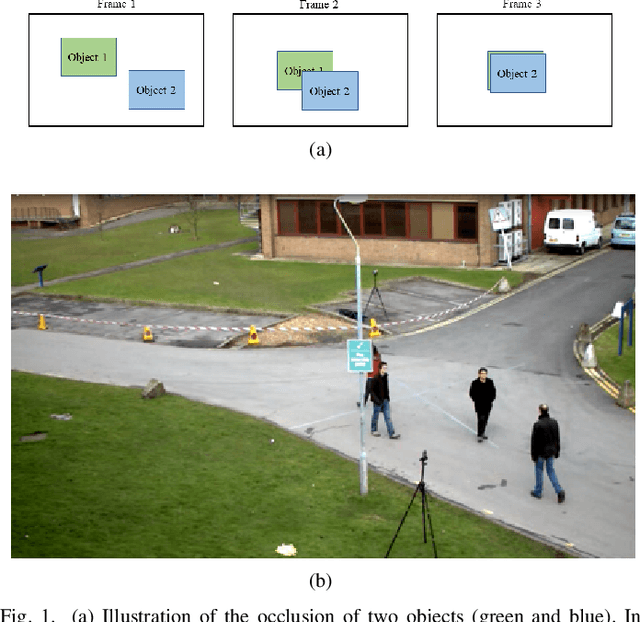
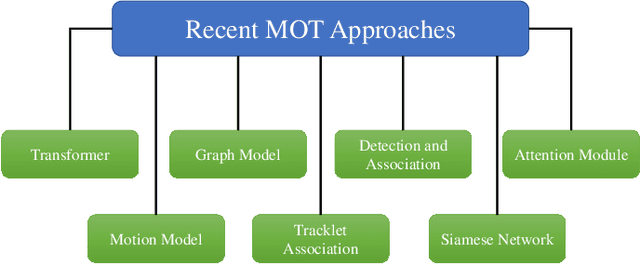
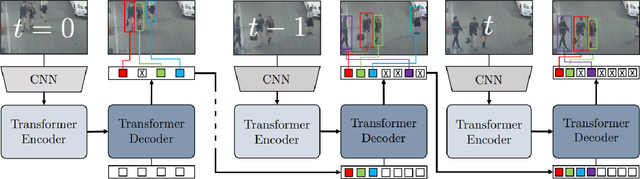
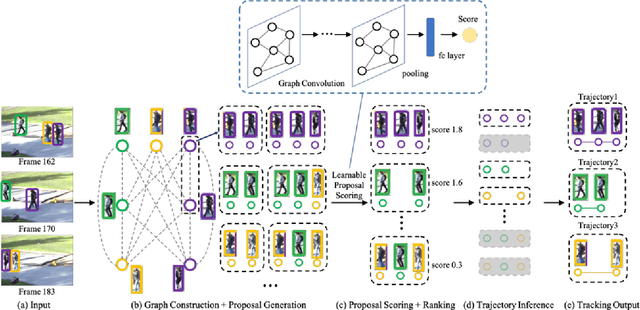
Multiple object tracking gained a lot of interest from researchers in recent years, and it has become one of the trending problems in computer vision, especially with the recent advancement of autonomous driving. MOT is one of the critical vision tasks for different issues like occlusion in crowded scenes, similar appearance, small object detection difficulty, ID switching, etc. To tackle these challenges, as researchers tried to utilize the attention mechanism of transformer, interrelation of tracklets with graph convolutional neural network, appearance similarity of objects in different frames with the siamese network, they also tried simple IOU matching based CNN network, motion prediction with LSTM. To take these scattered techniques under an umbrella, we have studied more than a hundred papers published over the last three years and have tried to extract the techniques that are more focused on by researchers in recent times to solve the problems of MOT. We have enlisted numerous applications, possibilities, and how MOT can be related to real life. Our review has tried to show the different perspectives of techniques that researchers used overtimes and give some future direction for the potential researchers. Moreover, we have included popular benchmark datasets and metrics in this review.
Two Decades of Bengali Handwritten Digit Recognition: A Survey
Jun 05, 2022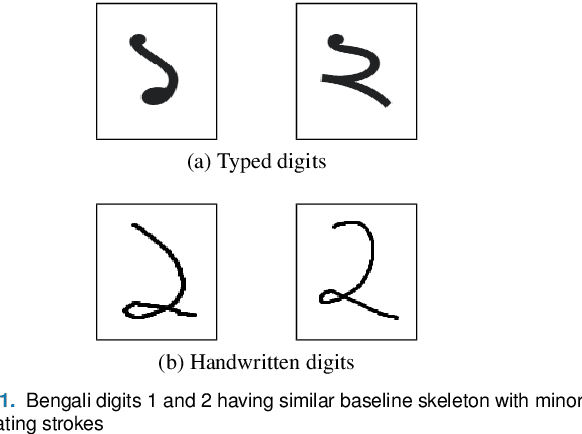
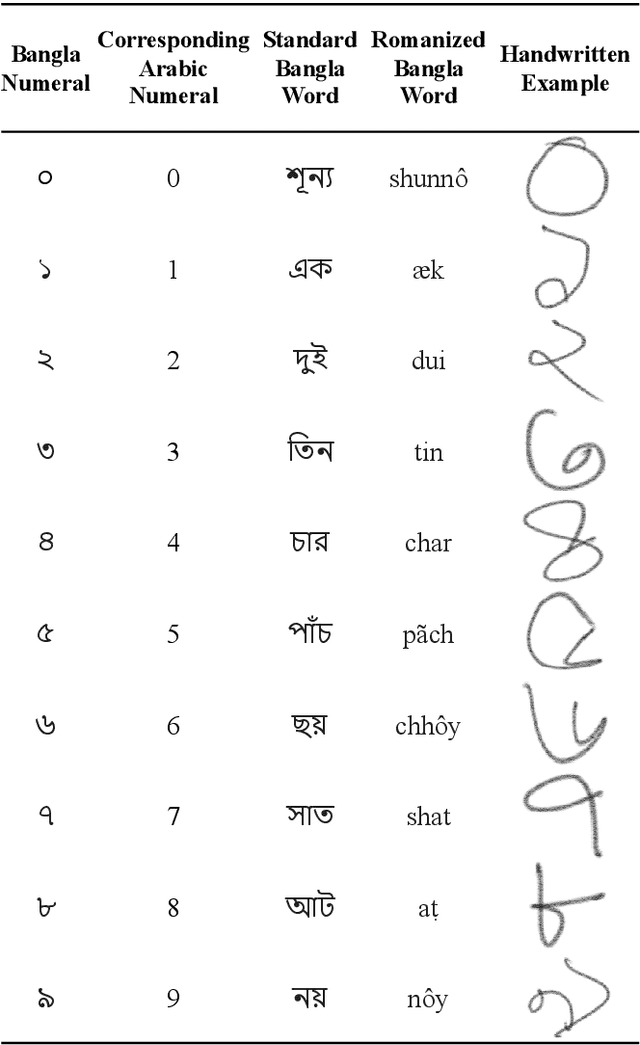
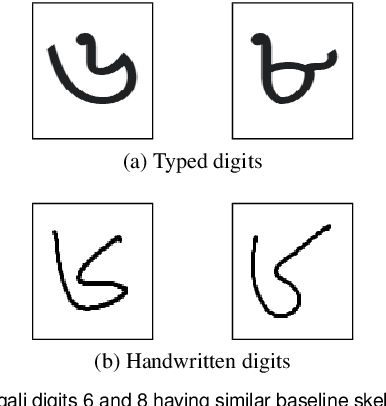

Handwritten Digit Recognition (HDR) is one of the most challenging tasks in the domain of Optical Character Recognition (OCR). Irrespective of language, there are some inherent challenges of HDR, which mostly arise due to the variations in writing styles across individuals, writing medium and environment, inability to maintain the same strokes while writing any digit repeatedly, etc. In addition to that, the structural complexities of the digits of a particular language may lead to ambiguous scenarios of HDR. Over the years, researchers have developed numerous offline and online HDR pipelines, where different image processing techniques are combined with traditional Machine Learning (ML)-based and/or Deep Learning (DL)-based architectures. Although evidence of extensive review studies on HDR exists in the literature for languages, such as: English, Arabic, Indian, Farsi, Chinese, etc., few surveys on Bengali HDR (BHDR) can be found, which lack a comprehensive analysis of the challenges, the underlying recognition process, and possible future directions. In this paper, the characteristics and inherent ambiguities of Bengali handwritten digits along with a comprehensive insight of two decades of the state-of-the-art datasets and approaches towards offline BHDR have been analyzed. Furthermore, several real-life application-specific studies, which involve BHDR, have also been discussed in detail. This paper will also serve as a compendium for researchers interested in the science behind offline BHDR, instigating the exploration of newer avenues of relevant research that may further lead to better offline recognition of Bengali handwritten digits in different application areas.
HEATGait: Hop-Extracted Adjacency Technique in Graph Convolution based Gait Recognition
Apr 21, 2022
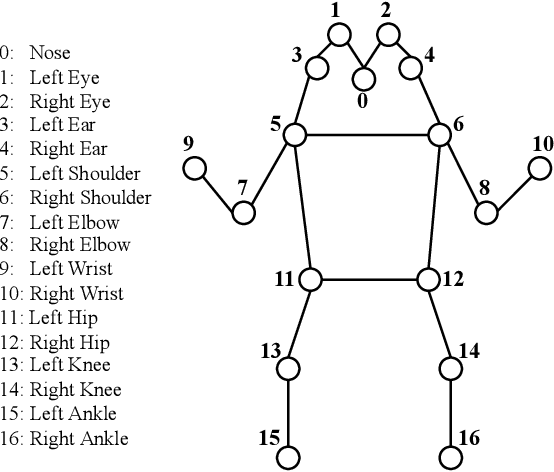
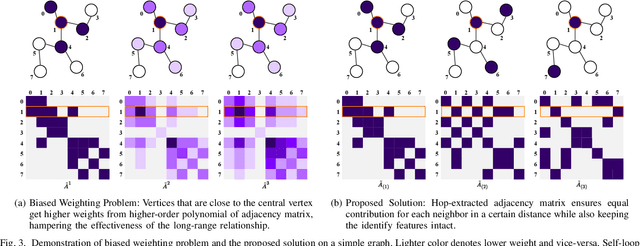
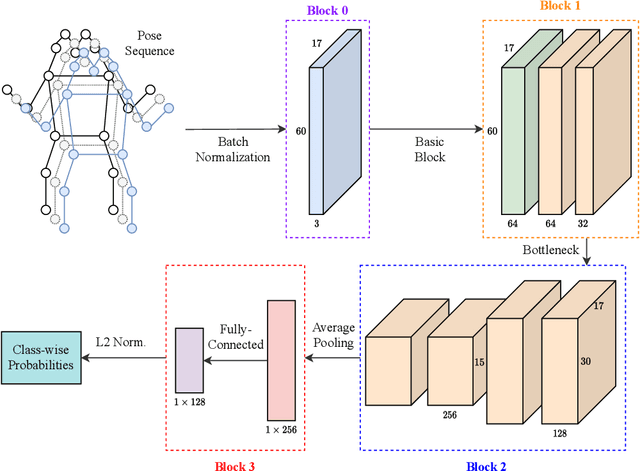
Biometric authentication using gait has become a promising field due to its unobtrusive nature. Recent approaches in model-based gait recognition techniques utilize spatio-temporal graphs for the elegant extraction of gait features. However, existing methods often rely on multi-scale operators for extracting long-range relationships among joints resulting in biased weighting. In this paper, we present HEATGait, a gait recognition system that improves the existing multi-scale graph convolution by efficient hop-extraction technique to alleviate the issue. Combined with preprocessing and augmentation techniques, we propose a powerful feature extractor that utilizes ResGCN to achieve state-of-the-art performance in model-based gait recognition on the CASIA-B gait dataset.
Less is More: Lighter and Faster Deep Neural Architecture for Tomato Leaf Disease Classification
Sep 06, 2021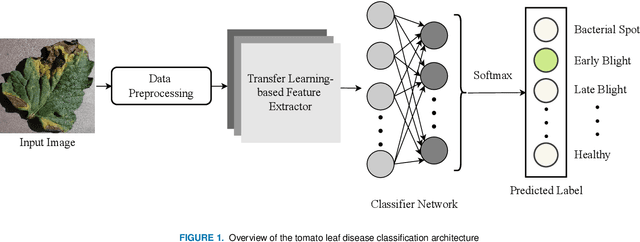
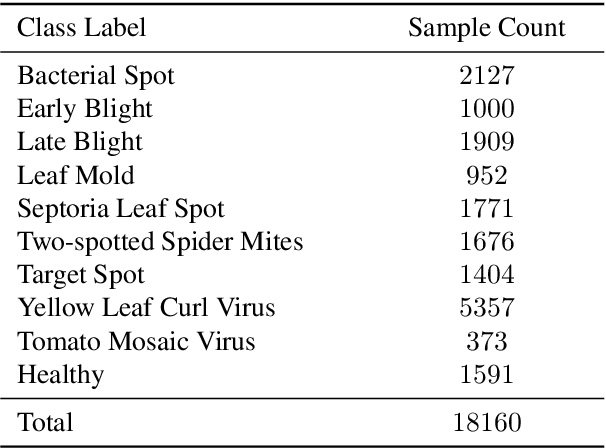

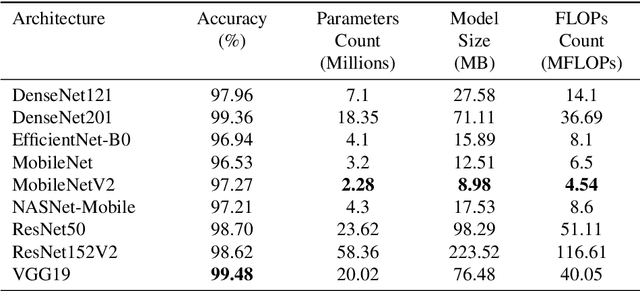
To ensure global food security and the overall profit of stakeholders, the importance of correctly detecting and classifying plant diseases is paramount. In this connection, the emergence of deep learning-based image classification has introduced a substantial number of solutions. However, the applicability of these solutions in low-end devices requires fast, accurate, and computationally inexpensive systems. This work proposes a lightweight transfer learning-based approach for detecting diseases from tomato leaves. It utilizes an effective preprocessing method to enhance the leaf images with illumination correction for improved classification. Our system extracts features using a combined model consisting of a pretrained MobileNetV2 architecture and a classifier network for effective prediction. Traditional augmentation approaches are replaced by runtime augmentation to avoid data leakage and address the class imbalance issue. Evaluation on tomato leaf images from the PlantVillage dataset shows that the proposed architecture achieves 99.30% accuracy with a model size of 9.60MB and 4.87M floating-point operations, making it a suitable choice for real-life applications in low-end devices. Our codes and models will be made available upon publication.
Densely-Populated Traffic Detection using YOLOv5 and Non-Maximum Suppression Ensembling
Aug 27, 2021Vehicular object detection is the heart of any intelligent traffic system. It is essential for urban traffic management. R-CNN, Fast R-CNN, Faster R-CNN and YOLO were some of the earlier state-of-the-art models. Region based CNN methods have the problem of higher inference time which makes it unrealistic to use the model in real-time. YOLO on the other hand struggles to detect small objects that appear in groups. In this paper, we propose a method that can locate and classify vehicular objects from a given densely crowded image using YOLOv5. The shortcoming of YOLO was solved my ensembling 4 different models. Our proposed model performs well on images taken from both top view and side view of the street in both day and night. The performance of our proposed model was measured on Dhaka AI dataset which contains densely crowded vehicular images. Our experiment shows that our model achieved mAP@0.5 of 0.458 with inference time of 0.75 sec which outperforms other state-of-the-art models on performance. Hence, the model can be implemented in the street for real-time traffic detection which can be used for traffic control and data collection.