 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBanglaLorica: Design and Evaluation of a Robust Watermarking Algorithm for Large Language Models in Bangla Text Generation
Jan 08, 2026As large language models (LLMs) are increasingly deployed for text generation, watermarking has become essential for authorship attribution, intellectual property protection, and misuse detection. While existing watermarking methods perform well in high-resource languages, their robustness in low-resource languages remains underexplored. This work presents the first systematic evaluation of state-of-the-art text watermarking methods: KGW, Exponential Sampling (EXP), and Waterfall, for Bangla LLM text generation under cross-lingual round-trip translation (RTT) attacks. Under benign conditions, KGW and EXP achieve high detection accuracy (>88%) with negligible perplexity and ROUGE degradation. However, RTT causes detection accuracy to collapse below RTT causes detection accuracy to collapse to 9-13%, indicating a fundamental failure of token-level watermarking. To address this, we propose a layered watermarking strategy that combines embedding-time and post-generation watermarks. Experimental results show that layered watermarking improves post-RTT detection accuracy by 25-35%, achieving 40-50% accuracy, representing a 3$\times$ to 4$\times$ relative improvement over single-layer methods, at the cost of controlled semantic degradation. Our findings quantify the robustness-quality trade-off in multilingual watermarking and establish layered watermarking as a practical, training-free solution for low-resource languages such as Bangla. Our code and data will be made public.
Human-Robo-advisor collaboration in decision-making: Evidence from a multiphase mixed methods experimental study
Oct 02, 2025


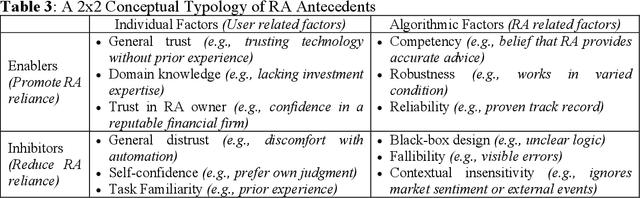
Robo-advisors (RAs) are cost-effective, bias-resistant alternatives to human financial advisors, yet adoption remains limited. While prior research has examined user interactions with RAs, less is known about how individuals interpret RA roles and integrate their advice into decision-making. To address this gap, this study employs a multiphase mixed methods design integrating a behavioral experiment (N = 334), thematic analysis, and follow-up quantitative testing. Findings suggest that people tend to rely on RAs, with reliance shaped by information about RA performance and the framing of advice as gains or losses. Thematic analysis reveals three RA roles in decision-making and four user types, each reflecting distinct patterns of advice integration. In addition, a 2 x 2 typology categorizes antecedents of acceptance into enablers and inhibitors at both the individual and algorithmic levels. By combining behavioral, interpretive, and confirmatory evidence, this study advances understanding of human-RA collaboration and provides actionable insights for designing more trustworthy and adaptive RA systems.
PhysicsEval: Inference-Time Techniques to Improve the Reasoning Proficiency of Large Language Models on Physics Problems
Jul 31, 2025The discipline of physics stands as a cornerstone of human intellect, driving the evolution of technology and deepening our understanding of the fundamental principles of the cosmos. Contemporary literature includes some works centered on the task of solving physics problems - a crucial domain of natural language reasoning. In this paper, we evaluate the performance of frontier LLMs in solving physics problems, both mathematical and descriptive. We also employ a plethora of inference-time techniques and agentic frameworks to improve the performance of the models. This includes the verification of proposed solutions in a cumulative fashion by other, smaller LLM agents, and we perform a comparative analysis of the performance that the techniques entail. There are significant improvements when the multi-agent framework is applied to problems that the models initially perform poorly on. Furthermore, we introduce a new evaluation benchmark for physics problems, ${\rm P{\small HYSICS}E{\small VAL}}$, consisting of 19,609 problems sourced from various physics textbooks and their corresponding correct solutions scraped from physics forums and educational websites. Our code and data are publicly available at https://github.com/areebuzair/PhysicsEval.
Fine-Tuning Video Transformers for Word-Level Bangla Sign Language: A Comparative Analysis for Classification Tasks
Jun 04, 2025Sign Language Recognition (SLR) involves the automatic identification and classification of sign gestures from images or video, converting them into text or speech to improve accessibility for the hearing-impaired community. In Bangladesh, Bangla Sign Language (BdSL) serves as the primary mode of communication for many individuals with hearing impairments. This study fine-tunes state-of-the-art video transformer architectures -- VideoMAE, ViViT, and TimeSformer -- on BdSLW60 (arXiv:2402.08635), a small-scale BdSL dataset with 60 frequent signs. We standardized the videos to 30 FPS, resulting in 9,307 user trial clips. To evaluate scalability and robustness, the models were also fine-tuned on BdSLW401 (arXiv:2503.02360), a large-scale dataset with 401 sign classes. Additionally, we benchmark performance against public datasets, including LSA64 and WLASL. Data augmentation techniques such as random cropping, horizontal flipping, and short-side scaling were applied to improve model robustness. To ensure balanced evaluation across folds during model selection, we employed 10-fold stratified cross-validation on the training set, while signer-independent evaluation was carried out using held-out test data from unseen users U4 and U8. Results show that video transformer models significantly outperform traditional machine learning and deep learning approaches. Performance is influenced by factors such as dataset size, video quality, frame distribution, frame rate, and model architecture. Among the models, the VideoMAE variant (MCG-NJU/videomae-base-finetuned-kinetics) achieved the highest accuracies of 95.5% on the frame rate corrected BdSLW60 dataset and 81.04% on the front-facing signs of BdSLW401 -- demonstrating strong potential for scalable and accurate BdSL recognition.
BdSLW401: Transformer-Based Word-Level Bangla Sign Language Recognition Using Relative Quantization Encoding (RQE)
Mar 04, 2025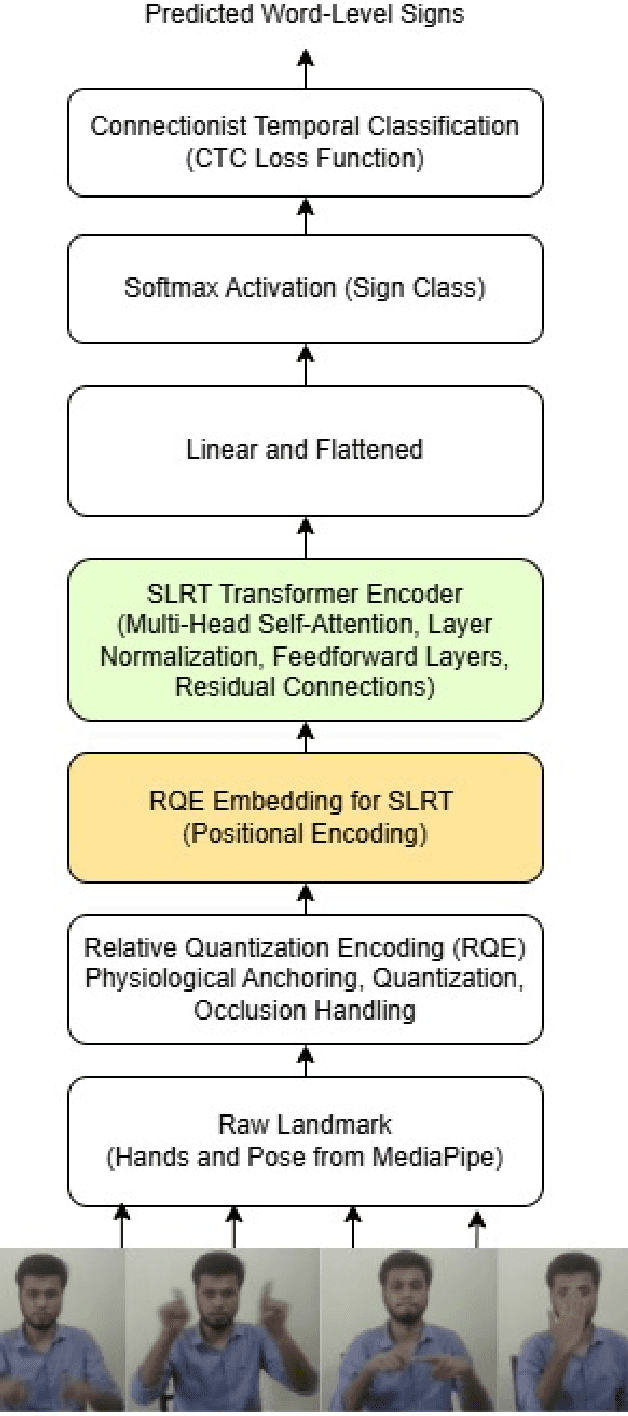
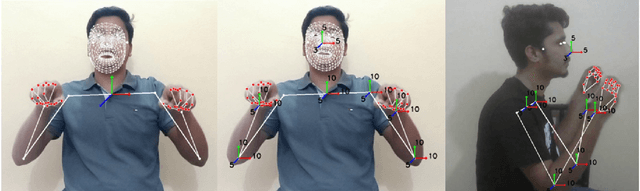
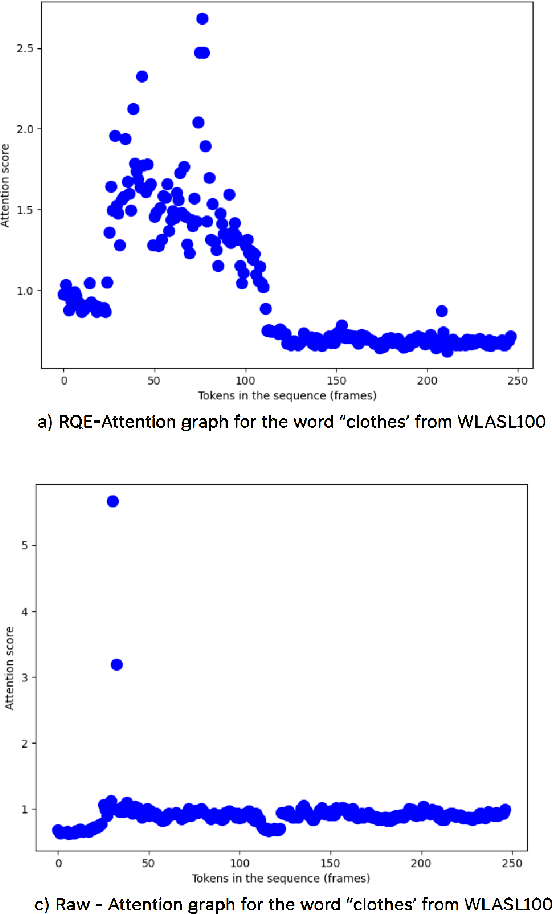

Sign language recognition (SLR) for low-resource languages like Bangla suffers from signer variability, viewpoint variations, and limited annotated datasets. In this paper, we present BdSLW401, a large-scale, multi-view, word-level Bangla Sign Language (BdSL) dataset with 401 signs and 102,176 video samples from 18 signers in front and lateral views. To improve transformer-based SLR, we introduce Relative Quantization Encoding (RQE), a structured embedding approach anchoring landmarks to physiological reference points and quantize motion trajectories. RQE improves attention allocation by decreasing spatial variability, resulting in 44.3% WER reduction in WLASL100, 21.0% in SignBD-200, and significant gains in BdSLW60 and SignBD-90. However, fixed quantization becomes insufficient on large-scale datasets (e.g., WLASL2000), indicating the need for adaptive encoding strategies. Further, RQE-SF, an extended variant that stabilizes shoulder landmarks, achieves improvements in pose consistency at the cost of small trade-offs in lateral view recognition. The attention graphs prove that RQE improves model interpretability by focusing on the major articulatory features (fingers, wrists) and the more distinctive frames instead of global pose changes. Introducing BdSLW401 and demonstrating the effectiveness of RQE-enhanced structured embeddings, this work advances transformer-based SLR for low-resource languages and sets a benchmark for future research in this area.
BDA: Bangla Text Data Augmentation Framework
Dec 11, 2024



Data augmentation involves generating synthetic samples that resemble those in a given dataset. In resource-limited fields where high-quality data is scarce, augmentation plays a crucial role in increasing the volume of training data. This paper introduces a Bangla Text Data Augmentation (BDA) Framework that uses both pre-trained models and rule-based methods to create new variants of the text. A filtering process is included to ensure that the new text keeps the same meaning as the original while also adding variety in the words used. We conduct a comprehensive evaluation of the framework's effectiveness in Bangla text classification tasks. Our framework achieved significant improvement in F1 scores across five distinct datasets, delivering performance equivalent to models trained on 100\% of the data while utilizing only 50\% of the training dataset. Additionally, we explore the impact of data scarcity by progressively reducing the training data and augmenting it through BDA, resulting in notable F1 score enhancements. The study offers a thorough examination of BDA's performance, identifying key factors for optimal results and addressing its limitations through detailed analysis.
Enhancing Sentiment Analysis in Bengali Texts: A Hybrid Approach Using Lexicon-Based Algorithm and Pretrained Language Model Bangla-BERT
Nov 29, 2024Sentiment analysis (SA) is a process of identifying the emotional tone or polarity within a given text and aims to uncover the user's complex emotions and inner feelings. While sentiment analysis has been extensively studied for languages like English, research in Bengali, remains limited, particularly for fine-grained sentiment categorization. This work aims to connect this gap by developing a novel approach that integrates rule-based algorithms with pre-trained language models. We developed a dataset from scratch, comprising over 15,000 manually labeled reviews. Next, we constructed a Lexicon Data Dictionary, assigning polarity scores to the reviews. We developed a novel rule based algorithm Bangla Sentiment Polarity Score (BSPS), an approach capable of generating sentiment scores and classifying reviews into nine distinct sentiment categories. To assess the performance of this method, we evaluated the classified sentiments using BanglaBERT, a pre-trained transformer-based language model. We also performed sentiment classification directly with BanglaBERT on the original data and evaluated this model's results. Our analysis revealed that the BSPS + BanglaBERT hybrid approach outperformed the standalone BanglaBERT model, achieving higher accuracy, precision, and nuanced classification across the nine sentiment categories. The results of our study emphasize the value and effectiveness of combining rule-based and pre-trained language model approaches for enhanced sentiment analysis in Bengali and suggest pathways for future research and application in languages with similar linguistic complexities.
BdSLW60: A Word-Level Bangla Sign Language Dataset
Feb 13, 2024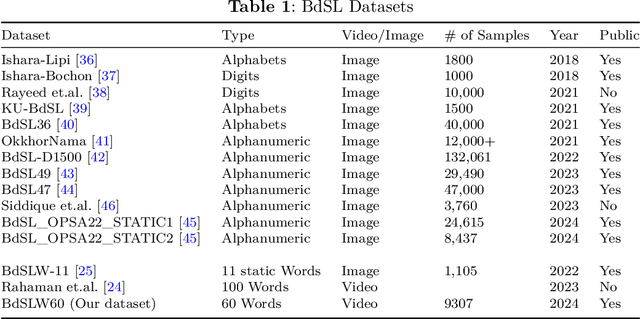


Sign language discourse is an essential mode of daily communication for the deaf and hard-of-hearing people. However, research on Bangla Sign Language (BdSL) faces notable limitations, primarily due to the lack of datasets. Recognizing wordlevel signs in BdSL (WL-BdSL) presents a multitude of challenges, including the need for well-annotated datasets, capturing the dynamic nature of sign gestures from facial or hand landmarks, developing suitable machine learning or deep learning-based models with substantial video samples, and so on. In this paper, we address these challenges by creating a comprehensive BdSL word-level dataset named BdSLW60 in an unconstrained and natural setting, allowing positional and temporal variations and allowing sign users to change hand dominance freely. The dataset encompasses 60 Bangla sign words, with a significant scale of 9307 video trials provided by 18 signers under the supervision of a sign language professional. The dataset was rigorously annotated and cross-checked by 60 annotators. We also introduced a unique approach of a relative quantization-based key frame encoding technique for landmark based sign gesture recognition. We report the benchmarking of our BdSLW60 dataset using the Support Vector Machine (SVM) with testing accuracy up to 67.6% and an attention-based bi-LSTM with testing accuracy up to 75.1%. The dataset is available at https://www.kaggle.com/datasets/hasaniut/bdslw60 and the code base is accessible from https://github.com/hasanssl/BdSLW60_Code.
Towards Automated Recipe Genre Classification using Semi-Supervised Learning
Oct 24, 2023
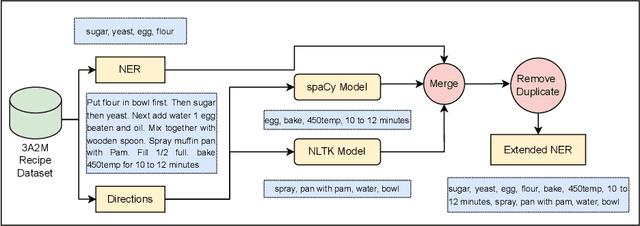

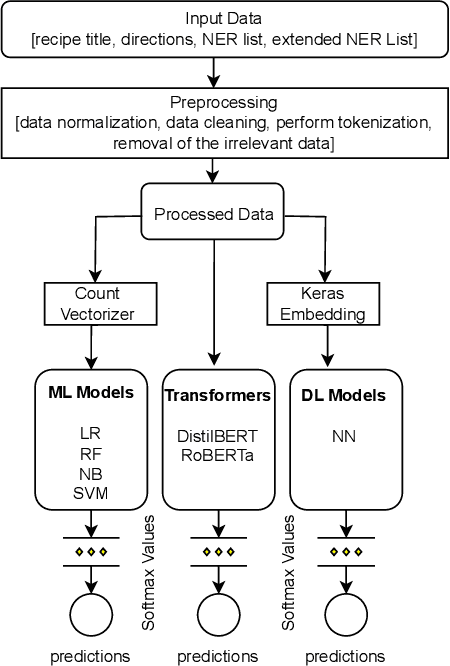
Sharing cooking recipes is a great way to exchange culinary ideas and provide instructions for food preparation. However, categorizing raw recipes found online into appropriate food genres can be challenging due to a lack of adequate labeled data. In this study, we present a dataset named the ``Assorted, Archetypal, and Annotated Two Million Extended (3A2M+) Cooking Recipe Dataset" that contains two million culinary recipes labeled in respective categories with extended named entities extracted from recipe descriptions. This collection of data includes various features such as title, NER, directions, and extended NER, as well as nine different labels representing genres including bakery, drinks, non-veg, vegetables, fast food, cereals, meals, sides, and fusions. The proposed pipeline named 3A2M+ extends the size of the Named Entity Recognition (NER) list to address missing named entities like heat, time or process from the recipe directions using two NER extraction tools. 3A2M+ dataset provides a comprehensive solution to the various challenging recipe-related tasks, including classification, named entity recognition, and recipe generation. Furthermore, we have demonstrated traditional machine learning, deep learning and pre-trained language models to classify the recipes into their corresponding genre and achieved an overall accuracy of 98.6\%. Our investigation indicates that the title feature played a more significant role in classifying the genre.
Math Word Problem Solving by Generating Linguistic Variants of Problem Statements
Jun 24, 2023



The art of mathematical reasoning stands as a fundamental pillar of intellectual progress and is a central catalyst in cultivating human ingenuity. Researchers have recently published a plethora of works centered around the task of solving Math Word Problems (MWP) $-$ a crucial stride towards general AI. These existing models are susceptible to dependency on shallow heuristics and spurious correlations to derive the solution expressions. In order to ameliorate this issue, in this paper, we propose a framework for MWP solvers based on the generation of linguistic variants of the problem text. The approach involves solving each of the variant problems and electing the predicted expression with the majority of the votes. We use DeBERTa (Decoding-enhanced BERT with disentangled attention) as the encoder to leverage its rich textual representations and enhanced mask decoder to construct the solution expressions. Furthermore, we introduce a challenging dataset, $\mathrm{P\small{ARA}\normalsize{MAWPS}}$, consisting of paraphrased, adversarial, and inverse variants of selectively sampled MWPs from the benchmark $\mathrm{M\small{AWPS}}$ dataset. We extensively experiment on this dataset along with other benchmark datasets using some baseline MWP solver models. We show that training on linguistic variants of problem statements and voting on candidate predictions improve the mathematical reasoning and robustness of the model. We make our code and data publicly available.