 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Automated Recipe Genre Classification using Semi-Supervised Learning
Paper and Code
Oct 24, 2023
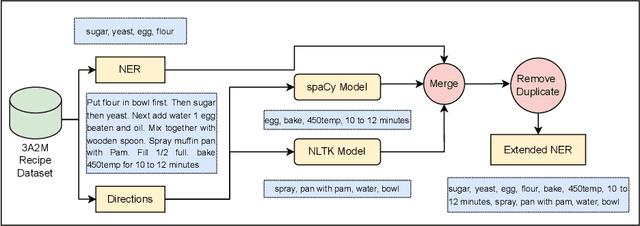

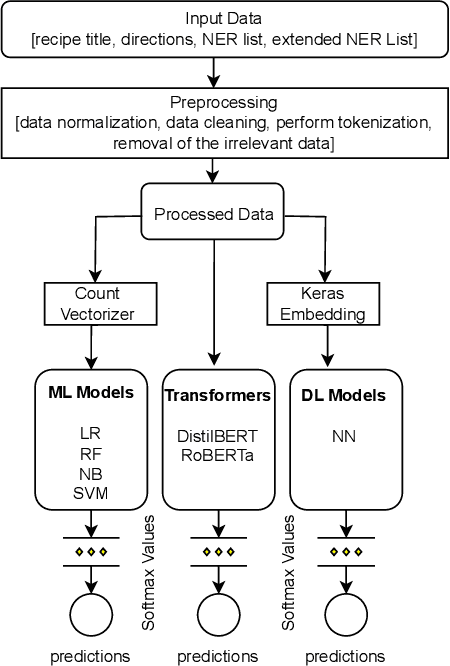
Sharing cooking recipes is a great way to exchange culinary ideas and provide instructions for food preparation. However, categorizing raw recipes found online into appropriate food genres can be challenging due to a lack of adequate labeled data. In this study, we present a dataset named the ``Assorted, Archetypal, and Annotated Two Million Extended (3A2M+) Cooking Recipe Dataset" that contains two million culinary recipes labeled in respective categories with extended named entities extracted from recipe descriptions. This collection of data includes various features such as title, NER, directions, and extended NER, as well as nine different labels representing genres including bakery, drinks, non-veg, vegetables, fast food, cereals, meals, sides, and fusions. The proposed pipeline named 3A2M+ extends the size of the Named Entity Recognition (NER) list to address missing named entities like heat, time or process from the recipe directions using two NER extraction tools. 3A2M+ dataset provides a comprehensive solution to the various challenging recipe-related tasks, including classification, named entity recognition, and recipe generation. Furthermore, we have demonstrated traditional machine learning, deep learning and pre-trained language models to classify the recipes into their corresponding genre and achieved an overall accuracy of 98.6\%. Our investigation indicates that the title feature played a more significant role in classifying the genre.