 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtecting and Preserving Protest Dynamics for Responsible Analysis
Apr 06, 2026Protest-related social media data are valuable for understanding collective action but inherently high-risk due to concerns surrounding surveillance, repression, and individual privacy. Contemporary AI systems can identify individuals, infer sensitive attributes, and cross-reference visual information across platforms, enabling surveillance that poses risks to protesters and bystanders. In such contexts, large foundation models trained on protest imagery risk memorizing and disclosing sensitive information, leading to cross-platform identity leakage and retroactive participant identification. Existing approaches to automated protest analysis do not provide a holistic pipeline that integrates privacy risk assessment, downstream analysis, and fairness considerations. To address this gap, we propose a responsible computing framework for analyzing collective protest dynamics while reducing risks to individual privacy. Our framework replaces sensitive protest imagery with well-labeled synthetic reproductions using conditional image synthesis, enabling analysis of collective patterns without direct exposure of identifiable individuals. We demonstrate that our approach produces realistic and diverse synthetic imagery while balancing downstream analytical utility with reductions in privacy risk. We further assess demographic fairness in the generated data, examining whether synthetic representations disproportionately affect specific subgroups. Rather than offering absolute privacy guarantees, our method adopts a pragmatic, harm-mitigating approach that enables socially sensitive analysis while acknowledging residual risks.
Towards Automated Recipe Genre Classification using Semi-Supervised Learning
Oct 24, 2023

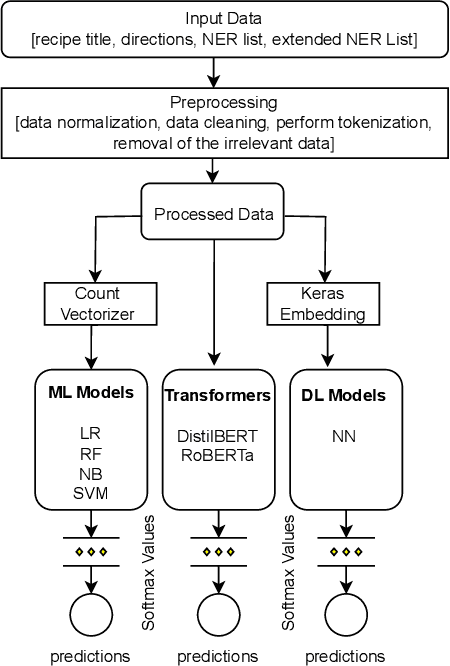
Sharing cooking recipes is a great way to exchange culinary ideas and provide instructions for food preparation. However, categorizing raw recipes found online into appropriate food genres can be challenging due to a lack of adequate labeled data. In this study, we present a dataset named the ``Assorted, Archetypal, and Annotated Two Million Extended (3A2M+) Cooking Recipe Dataset" that contains two million culinary recipes labeled in respective categories with extended named entities extracted from recipe descriptions. This collection of data includes various features such as title, NER, directions, and extended NER, as well as nine different labels representing genres including bakery, drinks, non-veg, vegetables, fast food, cereals, meals, sides, and fusions. The proposed pipeline named 3A2M+ extends the size of the Named Entity Recognition (NER) list to address missing named entities like heat, time or process from the recipe directions using two NER extraction tools. 3A2M+ dataset provides a comprehensive solution to the various challenging recipe-related tasks, including classification, named entity recognition, and recipe generation. Furthermore, we have demonstrated traditional machine learning, deep learning and pre-trained language models to classify the recipes into their corresponding genre and achieved an overall accuracy of 98.6\%. Our investigation indicates that the title feature played a more significant role in classifying the genre.
Uncovering Promises and Challenges of Federated Learning to Detect Cardiovascular Diseases: A Scoping Literature Review
Aug 26, 2023Cardiovascular diseases (CVD) are the leading cause of death globally, and early detection can significantly improve outcomes for patients. Machine learning (ML) models can help diagnose CVDs early, but their performance is limited by the data available for model training. Privacy concerns in healthcare make it harder to acquire data to train accurate ML models. Federated learning (FL) is an emerging approach to machine learning that allows models to be trained on data from multiple sources without compromising the privacy of the individual data owners. This survey paper provides an overview of the current state-of-the-art in FL for CVD detection. We review the different FL models proposed in various papers and discuss their advantages and challenges. We also compare FL with traditional centralized learning approaches and highlight the differences in terms of model accuracy, privacy, and data distribution handling capacity. Finally, we provide a critical analysis of FL's current challenges and limitations for CVD detection and discuss potential avenues for future research. Overall, this survey paper aims to provide a comprehensive overview of the current state-of-the-art in FL for CVD detection and to highlight its potential for improving the accuracy and privacy of CVD detection models.
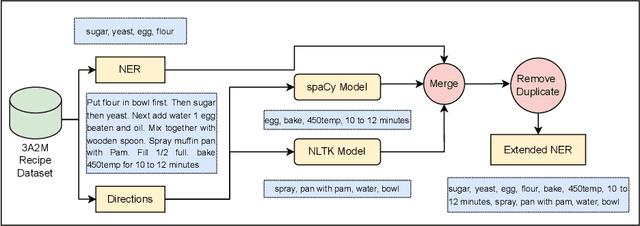
Assorted, Archetypal and Annotated Two Million (3A2M) Cooking Recipes Dataset based on Active Learning
Mar 27, 2023Cooking recipes allow individuals to exchange culinary ideas and provide food preparation instructions. Due to a lack of adequate labeled data, categorizing raw recipes found online to the appropriate food genres is a challenging task in this domain. Utilizing the knowledge of domain experts to categorize recipes could be a solution. In this study, we present a novel dataset of two million culinary recipes labeled in respective categories leveraging the knowledge of food experts and an active learning technique. To construct the dataset, we collect the recipes from the RecipeNLG dataset. Then, we employ three human experts whose trustworthiness score is higher than 86.667% to categorize 300K recipe by their Named Entity Recognition (NER) and assign it to one of the nine categories: bakery, drinks, non-veg, vegetables, fast food, cereals, meals, sides and fusion. Finally, we categorize the remaining 1900K recipes using Active Learning method with a blend of Query-by-Committee and Human In The Loop (HITL) approaches. There are more than two million recipes in our dataset, each of which is categorized and has a confidence score linked with it. For the 9 genres, the Fleiss Kappa score of this massive dataset is roughly 0.56026. We believe that the research community can use this dataset to perform various machine learning tasks such as recipe genre classification, recipe generation of a specific genre, new recipe creation, etc. The dataset can also be used to train and evaluate the performance of various NLP tasks such as named entity recognition, part-of-speech tagging, semantic role labeling, and so on. The dataset will be available upon publication: https://tinyurl.com/3zu4778y.
Mapless Navigation among Dynamics with Social-safety-awareness: a reinforcement learning approach from 2D laser scans
Nov 08, 2019
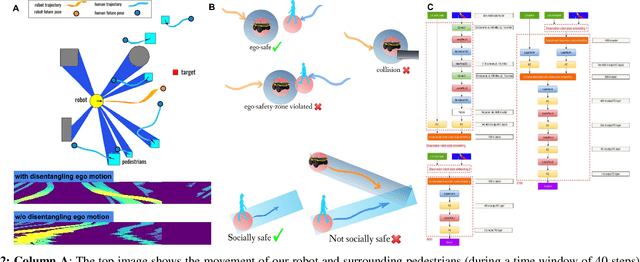
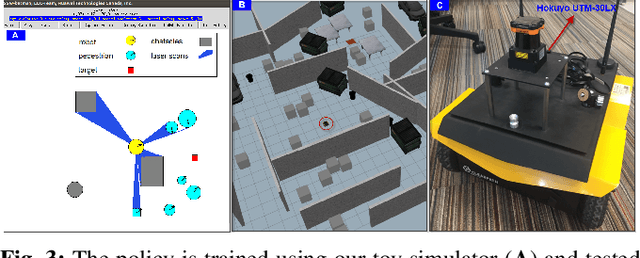
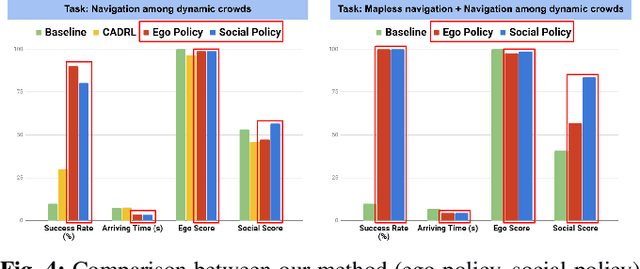
We propose a method to tackle the problem of mapless collision-avoidance navigation where humans are present using 2D laser scans. Our proposed method uses ego-safety to measure collision from the robot's perspective while social-safety to measure the impact of our robot's actions on surrounding pedestrians. Specifically, the social-safety part predicts the intrusion impact of our robot's action into the interaction area with surrounding humans. We train the policy using reinforcement learning on a simple simulator and directly evaluate the learned policy in Gazebo and real robot tests. Experiments show the learned policy can be smoothly transferred without any fine tuning. We observe that our method demonstrates time-efficient path planning behavior with high success rate in mapless navigation tasks. Furthermore, we test our method in a navigation among dynamic crowds task considering both low and high volume traffic. Our learned policy demonstrates cooperative behavior that actively drives our robot into traffic flows while showing respect to nearby pedestrians. Evaluation videos are at https://sites.google.com/view/ssw-batman
A Novel Technique of Noninvasive Hemoglobin Level Measurement Using HSV Value of Fingertip Image
Oct 07, 2019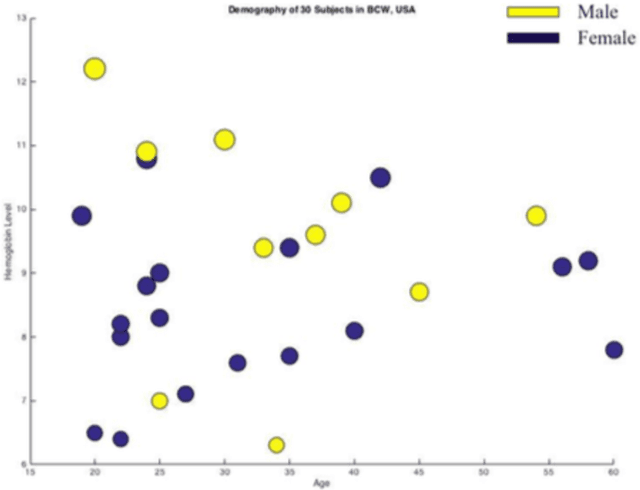
Over the last decade, smartphones have changed radically to support us with mHealth technology, cloud computing, and machine learning algorithm. Having its multifaceted facilities, we present a novel smartphone-based noninvasive hemoglobin (Hb) level prediction model by analyzing hue, saturation and value (HSV) of a fingertip video. Here, we collect 60 videos of 60 subjects from two different locations: Blood Center of Wisconsin, USA and AmaderGram, Bangladesh. We extract red, green, and blue (RGB) pixel intensities of selected images of those videos captured by the smartphone camera with flash on. Then we convert RGB values of selected video frames of a fingertip video into HSV color space and we generate histogram values of these HSV pixel intensities. We average these histogram values of a fingertip video and consider as an observation against the gold standard Hb concentration. We generate two input feature matrices based on observation of two different data sets. Partial Least Squares (PLS) algorithm is applied on the input feature matrix. We observe R2=0.95 in both data sets through our research. We analyze our data using Python OpenCV, Matlab, and R statistics tool.
Reinforcing Classical Planning for Adversary Driving Scenarios
Mar 20, 2019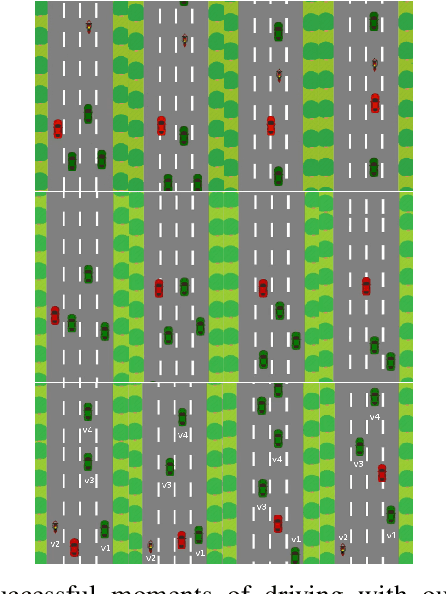
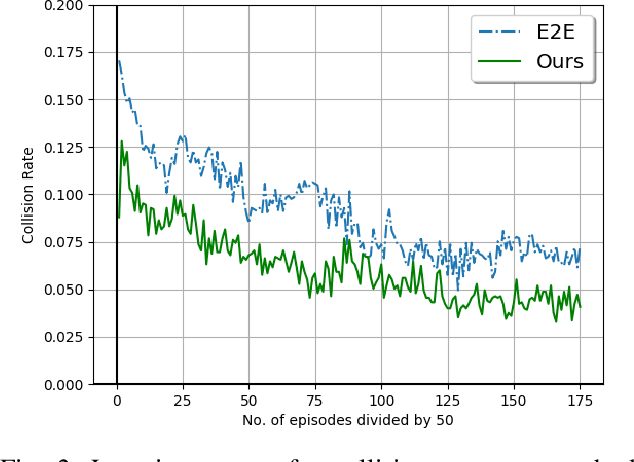
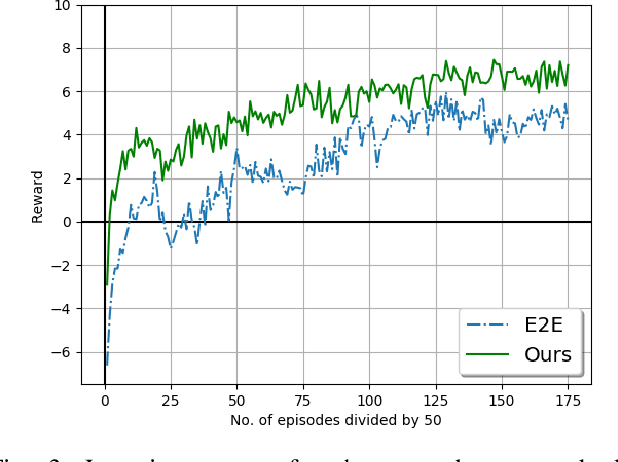

Adversary scenarios in driving, where the other vehicles may make mistakes or have a competing or malicious intent, have to be studied not only for our safety but also for addressing the concerns from public in order to push the technology forward. Classical planning solutions for adversary driving do not exist so far, especially when the vehicles do not communicate their intent. Given recent success in solving hard problems in artificial intelligence (AI), it is worth studying the potential of reinforcement learning for safety driving in adversary settings. In most recent reinforcement learning applications, there is a deep neural networks that maps an input state to an optimal policy over primitive actions. However, learning a policy over primitive actions is very difficult and inefficient. On the other hand, the knowledge already learned in classical planning methods should be inherited and reused. In order to take advantage of reinforcement learning good at exploring the action space for safety and classical planning skill models good at handling most driving scenarios, we propose to learn a policy over an action space of primitive actions augmented with classical planning methods. We show two advantages by doing so. First, training this reinforcement learning agent is easier and faster than training the primitive-action agent. Second, our new agent outperforms the primitive-action reinforcement learning agent, human testers as well as the classical planning methods that our agent queries as skills.