 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcing Classical Planning for Adversary Driving Scenarios
Paper and Code
Mar 20, 2019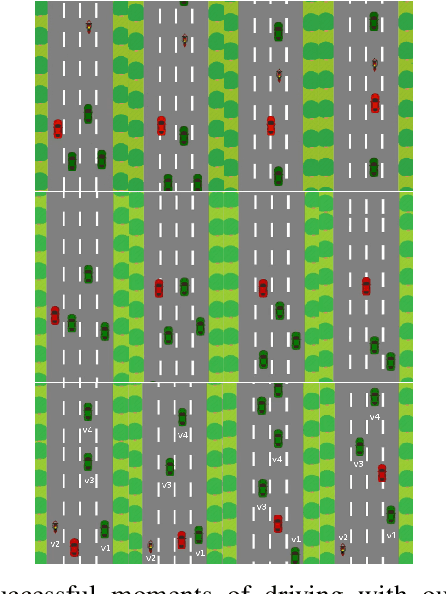
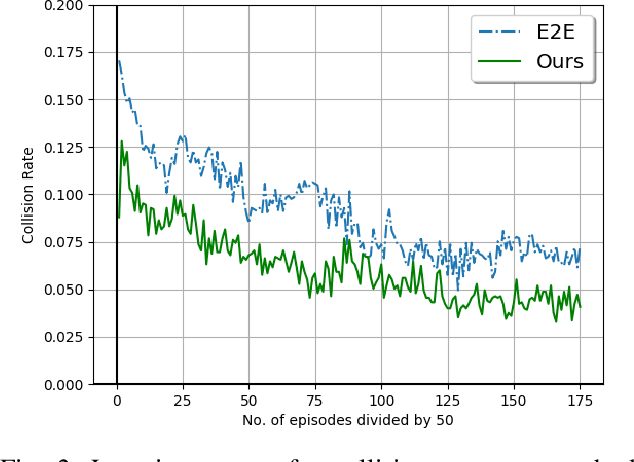
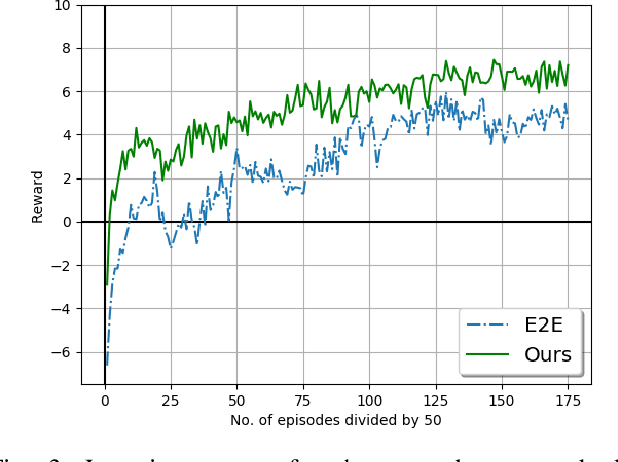

Adversary scenarios in driving, where the other vehicles may make mistakes or have a competing or malicious intent, have to be studied not only for our safety but also for addressing the concerns from public in order to push the technology forward. Classical planning solutions for adversary driving do not exist so far, especially when the vehicles do not communicate their intent. Given recent success in solving hard problems in artificial intelligence (AI), it is worth studying the potential of reinforcement learning for safety driving in adversary settings. In most recent reinforcement learning applications, there is a deep neural networks that maps an input state to an optimal policy over primitive actions. However, learning a policy over primitive actions is very difficult and inefficient. On the other hand, the knowledge already learned in classical planning methods should be inherited and reused. In order to take advantage of reinforcement learning good at exploring the action space for safety and classical planning skill models good at handling most driving scenarios, we propose to learn a policy over an action space of primitive actions augmented with classical planning methods. We show two advantages by doing so. First, training this reinforcement learning agent is easier and faster than training the primitive-action agent. Second, our new agent outperforms the primitive-action reinforcement learning agent, human testers as well as the classical planning methods that our agent queries as skills.