 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering Promises and Challenges of Federated Learning to Detect Cardiovascular Diseases: A Scoping Literature Review
Aug 26, 2023Cardiovascular diseases (CVD) are the leading cause of death globally, and early detection can significantly improve outcomes for patients. Machine learning (ML) models can help diagnose CVDs early, but their performance is limited by the data available for model training. Privacy concerns in healthcare make it harder to acquire data to train accurate ML models. Federated learning (FL) is an emerging approach to machine learning that allows models to be trained on data from multiple sources without compromising the privacy of the individual data owners. This survey paper provides an overview of the current state-of-the-art in FL for CVD detection. We review the different FL models proposed in various papers and discuss their advantages and challenges. We also compare FL with traditional centralized learning approaches and highlight the differences in terms of model accuracy, privacy, and data distribution handling capacity. Finally, we provide a critical analysis of FL's current challenges and limitations for CVD detection and discuss potential avenues for future research. Overall, this survey paper aims to provide a comprehensive overview of the current state-of-the-art in FL for CVD detection and to highlight its potential for improving the accuracy and privacy of CVD detection models.
Communication Efficiency in Federated Learning: Achievements and Challenges
Jul 23, 2021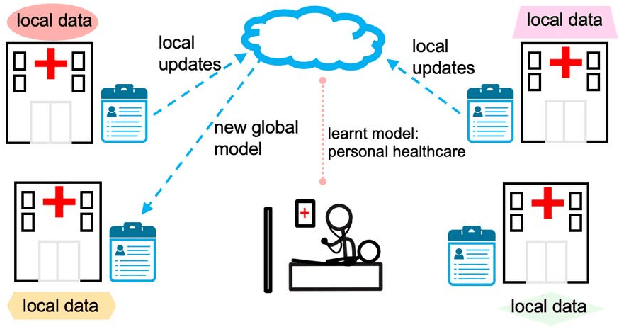
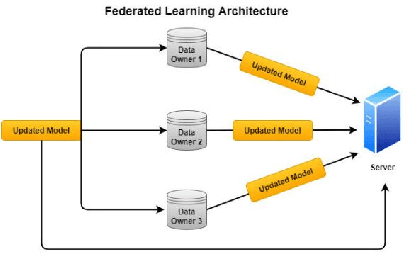
Federated Learning (FL) is known to perform Machine Learning tasks in a distributed manner. Over the years, this has become an emerging technology especially with various data protection and privacy policies being imposed FL allows performing machine learning tasks whilst adhering to these challenges. As with the emerging of any new technology, there are going to be challenges and benefits. A challenge that exists in FL is the communication costs, as FL takes place in a distributed environment where devices connected over the network have to constantly share their updates this can create a communication bottleneck. In this paper, we present a survey of the research that is performed to overcome the communication constraints in an FL setting.
A Review of the Non-Invasive Techniques for Monitoring Different Aspects of Sleep
Apr 27, 2021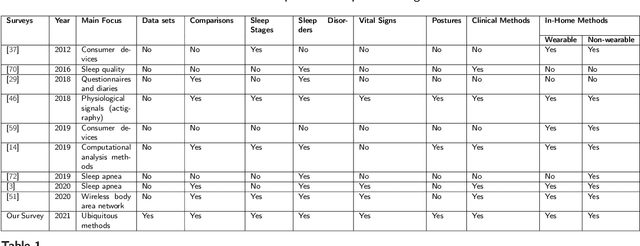
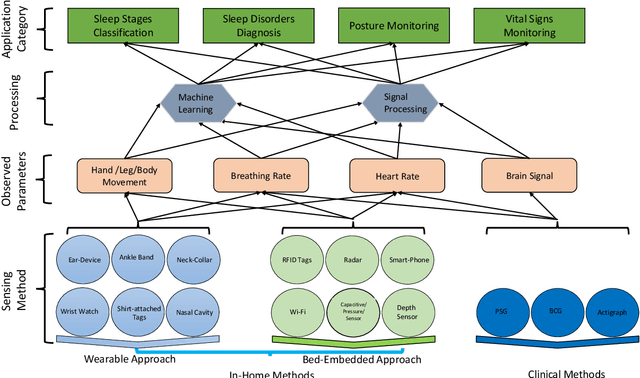
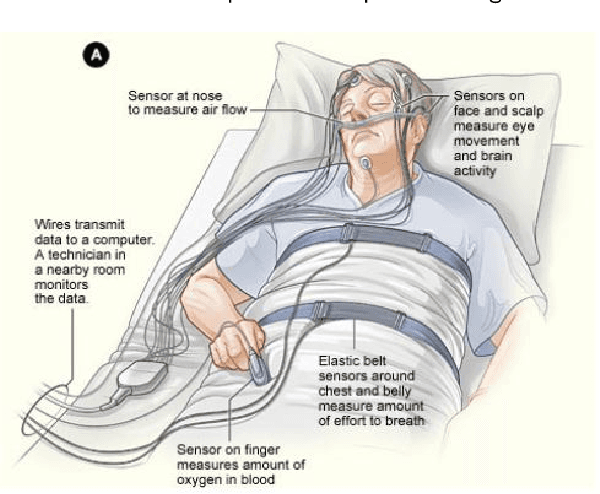
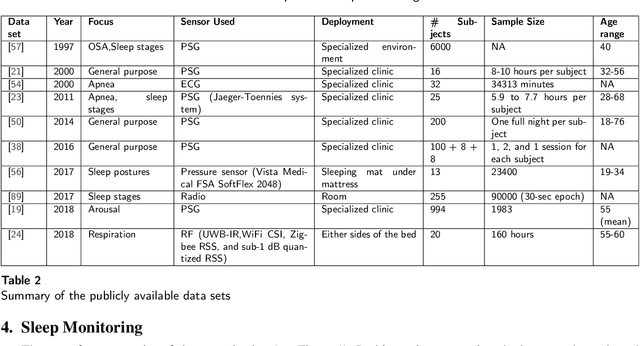
Quality sleep is very important for a healthy life. Nowadays, many people around the world are not getting enough sleep which is having negative impacts on their lifestyles. Studies are being conducted for sleep monitoring and have now become an important tool for understanding sleep behavior. The gold standard method for sleep analysis is polysomnography (PSG) conducted in a clinical environment but this method is both expensive and complex for long-term use. With the advancements in the field of sensors and the introduction of off-the-shelf technologies, unobtrusive solutions are becoming common as alternatives for in-home sleep monitoring. Various solutions have been proposed using both wearable and non-wearable methods which are cheap and easy to use for in-home sleep monitoring. In this paper, we present a comprehensive survey of the latest research works (2015 and after) conducted in various categories of sleep monitoring including sleep stage classification, sleep posture recognition, sleep disorders detection, and vital signs monitoring. We review the latest works done using the non-invasive approach and cover both wearable and non-wearable methods. We discuss the design approaches and key attributes of the work presented and provide an extensive analysis based on 10 key factors, to give a comprehensive overview of the recent developments and trends in all four categories of sleep monitoring. We also present some publicly available datasets for different categories of sleep monitoring. In the end, we discuss several open issues and provide future research directions in the area of sleep monitoring.
A Comprehensive Survey of Ontology Summarization: Measures and Methods
Jan 05, 2018
The Semantic Web is becoming a large scale framework that enables data to be published, shared, and reused in the form of ontologies. The ontology which is considered as basic building block of semantic web consists of two layers including data and schema layer. With the current exponential development of ontologies in both data size and complexity of schemas, ontology understanding which is playing an important role in different tasks such as ontology engineering, ontology learning, etc., is becoming more difficult. Ontology summarization as a way to distill knowledge from an ontology and generate an abridge version to facilitate a better understanding is getting more attention recently. There are various approaches available for ontology summarization which are focusing on different measures in order to produce a proper summary for a given ontology. In this paper, we mainly focus on the common metrics which are using for ontology summarization and meet the state-of-the-art in ontology summarization.
Text Summarization Techniques: A Brief Survey
Jul 28, 2017In recent years, there has been a explosion in the amount of text data from a variety of sources. This volume of text is an invaluable source of information and knowledge which needs to be effectively summarized to be useful. In this review, the main approaches to automatic text summarization are described. We review the different processes for summarization and describe the effectiveness and shortcomings of the different methods.
A Brief Survey of Text Mining: Classification, Clustering and Extraction Techniques
Jul 28, 2017
The amount of text that is generated every day is increasing dramatically. This tremendous volume of mostly unstructured text cannot be simply processed and perceived by computers. Therefore, efficient and effective techniques and algorithms are required to discover useful patterns. Text mining is the task of extracting meaningful information from text, which has gained significant attentions in recent years. In this paper, we describe several of the most fundamental text mining tasks and techniques including text pre-processing, classification and clustering. Additionally, we briefly explain text mining in biomedical and health care domains.