 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Recent Random Walk-based Methods for Embedding Knowledge Graphs
Jun 11, 2024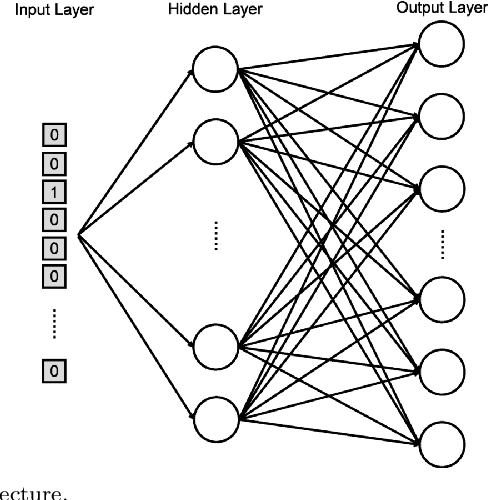
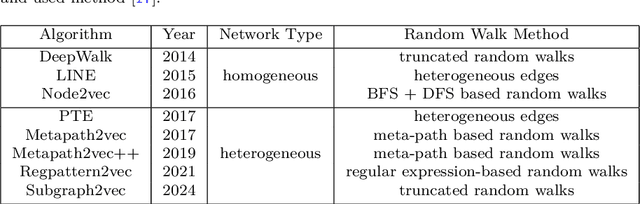
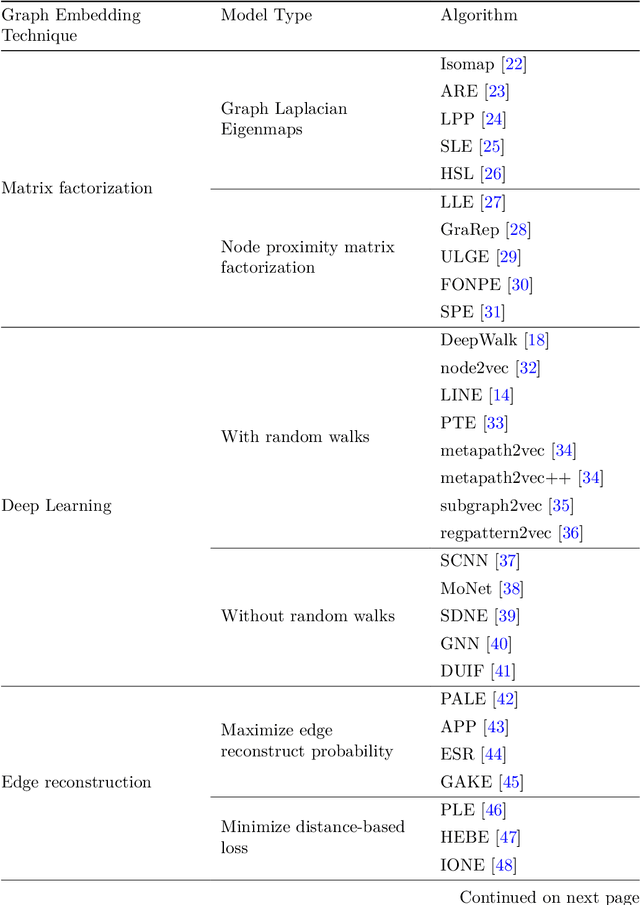

Machine learning, deep learning, and NLP methods on knowledge graphs are present in different fields and have important roles in various domains from self-driving cars to friend recommendations on social media platforms. However, to apply these methods to knowledge graphs, the data usually needs to be in an acceptable size and format. In fact, knowledge graphs normally have high dimensions and therefore we need to transform them to a low-dimensional vector space. An embedding is a low-dimensional space into which you can translate high dimensional vectors in a way that intrinsic features of the input data are preserved. In this review, we first explain knowledge graphs and their embedding and then review some of the random walk-based embedding methods that have been developed recently.
Subgraph2vec: A random walk-based algorithm for embedding knowledge graphs
May 03, 2024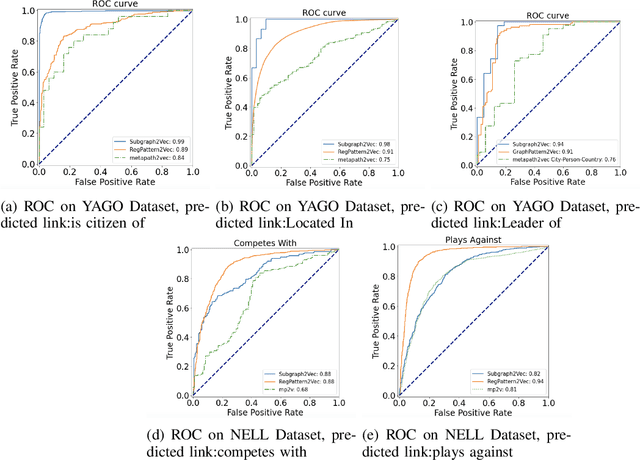
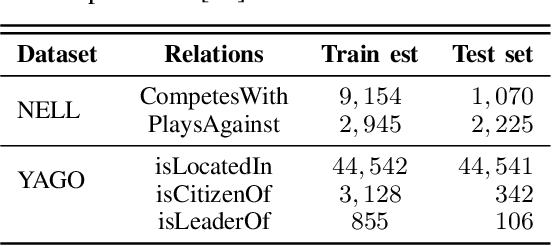
Graph is an important data representation which occurs naturally in the real world applications \cite{goyal2018graph}. Therefore, analyzing graphs provides users with better insights in different areas such as anomaly detection \cite{ma2021comprehensive}, decision making \cite{fan2023graph}, clustering \cite{tsitsulin2023graph}, classification \cite{wang2021mixup} and etc. However, most of these methods require high levels of computational time and space. We can use other ways like embedding to reduce these costs. Knowledge graph (KG) embedding is a technique that aims to achieve the vector representation of a KG. It represents entities and relations of a KG in a low-dimensional space while maintaining the semantic meanings of them. There are different methods for embedding graphs including random walk-based methods such as node2vec, metapath2vec and regpattern2vec. However, most of these methods bias the walks based on a rigid pattern usually hard-coded in the algorithm. In this work, we introduce \textit{subgraph2vec} for embedding KGs where walks are run inside a user-defined subgraph. We use this embedding for link prediction and prove our method has better performance in most cases in comparison with the previous ones.
A Comparative Study of Machine Learning Models for Tabular Data Through Challenge of Monitoring Parkinson's Disease Progression Using Voice Recordings
May 27, 2020

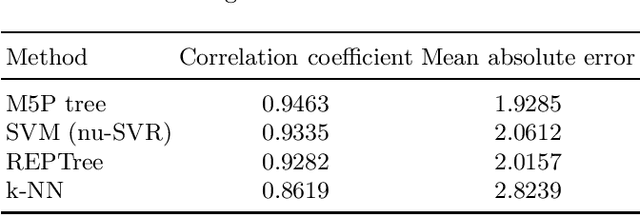

People with Parkinson's disease must be regularly monitored by their physician to observe how the disease is progressing and potentially adjust treatment plans to mitigate the symptoms. Monitoring the progression of the disease through a voice recording captured by the patient at their own home can make the process faster and less stressful. Using a dataset of voice recordings of 42 people with early-stage Parkinson's disease over a time span of 6 months, we applied multiple machine learning techniques to find a correlation between the voice recording and the patient's motor UPDRS score. We approached this problem using a multitude of both regression and classification techniques. Much of this paper is dedicated to mapping the voice data to motor UPDRS scores using regression techniques in order to obtain a more precise value for unknown instances. Through this comparative study of variant machine learning methods, we realized some old machine learning methods like trees outperform cutting edge deep learning models on numerous tabular datasets.
A Comprehensive Survey of Ontology Summarization: Measures and Methods
Jan 05, 2018
The Semantic Web is becoming a large scale framework that enables data to be published, shared, and reused in the form of ontologies. The ontology which is considered as basic building block of semantic web consists of two layers including data and schema layer. With the current exponential development of ontologies in both data size and complexity of schemas, ontology understanding which is playing an important role in different tasks such as ontology engineering, ontology learning, etc., is becoming more difficult. Ontology summarization as a way to distill knowledge from an ontology and generate an abridge version to facilitate a better understanding is getting more attention recently. There are various approaches available for ontology summarization which are focusing on different measures in order to produce a proper summary for a given ontology. In this paper, we mainly focus on the common metrics which are using for ontology summarization and meet the state-of-the-art in ontology summarization.