 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Recent Random Walk-based Methods for Embedding Knowledge Graphs
Jun 11, 2024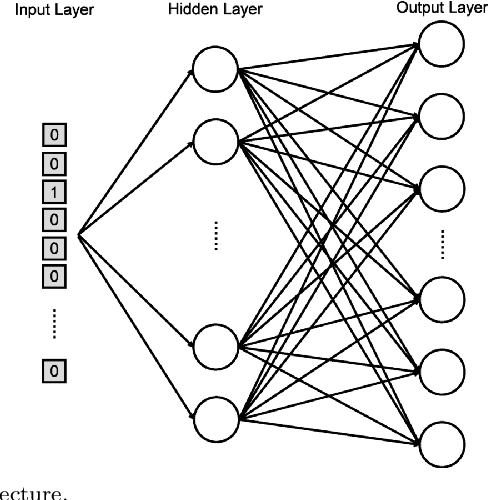

Machine learning, deep learning, and NLP methods on knowledge graphs are present in different fields and have important roles in various domains from self-driving cars to friend recommendations on social media platforms. However, to apply these methods to knowledge graphs, the data usually needs to be in an acceptable size and format. In fact, knowledge graphs normally have high dimensions and therefore we need to transform them to a low-dimensional vector space. An embedding is a low-dimensional space into which you can translate high dimensional vectors in a way that intrinsic features of the input data are preserved. In this review, we first explain knowledge graphs and their embedding and then review some of the random walk-based embedding methods that have been developed recently.
Relations Prediction for Knowledge Graph Completion using Large Language Models
May 04, 2024
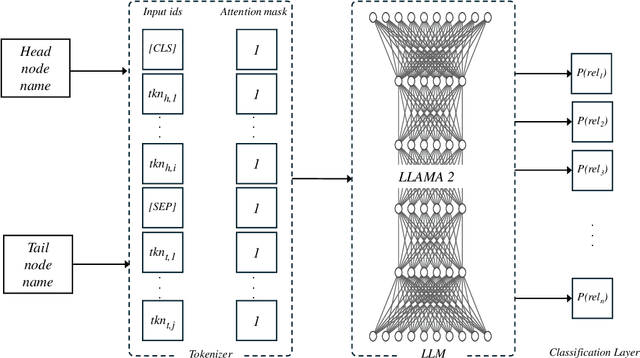

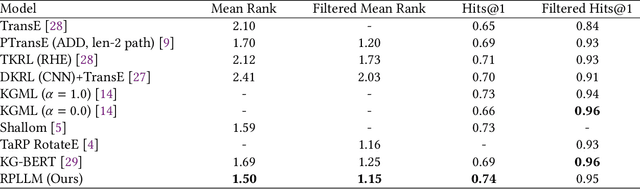
Knowledge Graphs have been widely used to represent facts in a structured format. Due to their large scale applications, knowledge graphs suffer from being incomplete. The relation prediction task obtains knowledge graph completion by assigning one or more possible relations to each pair of nodes. In this work, we make use of the knowledge graph node names to fine-tune a large language model for the relation prediction task. By utilizing the node names only we enable our model to operate sufficiently in the inductive settings. Our experiments show that we accomplish new scores on a widely used knowledge graph benchmark.
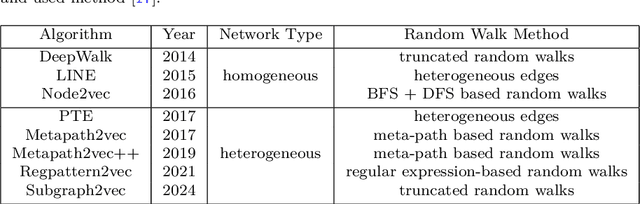
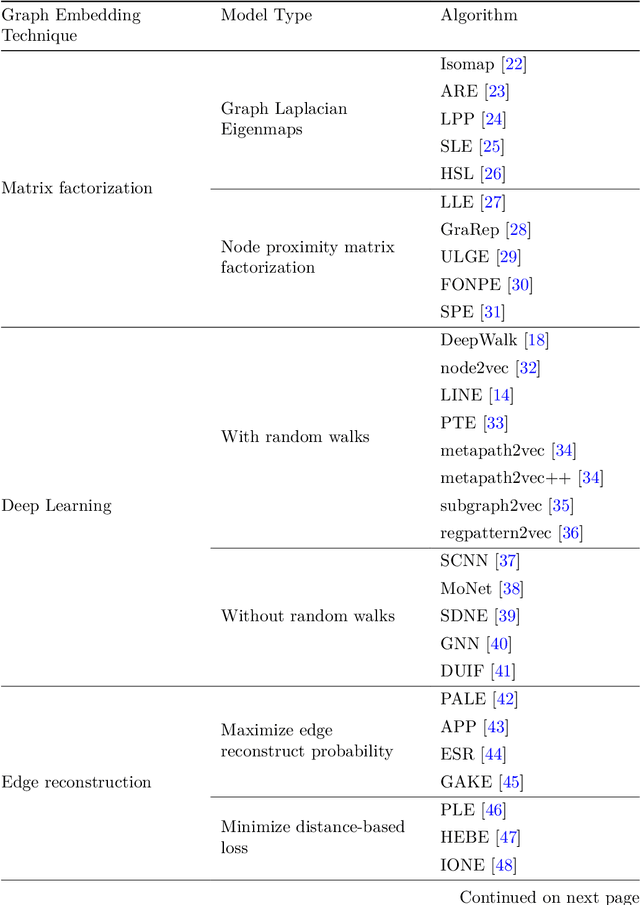
Subgraph2vec: A random walk-based algorithm for embedding knowledge graphs
May 03, 2024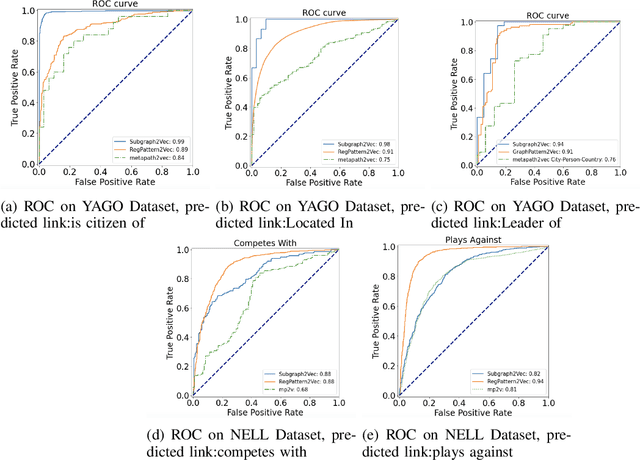
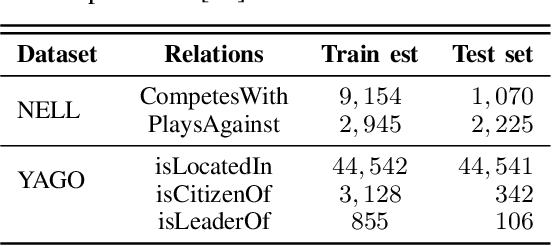
Graph is an important data representation which occurs naturally in the real world applications \cite{goyal2018graph}. Therefore, analyzing graphs provides users with better insights in different areas such as anomaly detection \cite{ma2021comprehensive}, decision making \cite{fan2023graph}, clustering \cite{tsitsulin2023graph}, classification \cite{wang2021mixup} and etc. However, most of these methods require high levels of computational time and space. We can use other ways like embedding to reduce these costs. Knowledge graph (KG) embedding is a technique that aims to achieve the vector representation of a KG. It represents entities and relations of a KG in a low-dimensional space while maintaining the semantic meanings of them. There are different methods for embedding graphs including random walk-based methods such as node2vec, metapath2vec and regpattern2vec. However, most of these methods bias the walks based on a rigid pattern usually hard-coded in the algorithm. In this work, we introduce \textit{subgraph2vec} for embedding KGs where walks are run inside a user-defined subgraph. We use this embedding for link prediction and prove our method has better performance in most cases in comparison with the previous ones.
Knowledge Graph Completion using Structural and Textual Embeddings
Apr 24, 2024Knowledge Graphs (KGs) are widely employed in artificial intelligence applications, such as question-answering and recommendation systems. However, KGs are frequently found to be incomplete. While much of the existing literature focuses on predicting missing nodes for given incomplete KG triples, there remains an opportunity to complete KGs by exploring relations between existing nodes, a task known as relation prediction. In this study, we propose a relations prediction model that harnesses both textual and structural information within KGs. Our approach integrates walks-based embeddings with language model embeddings to effectively represent nodes. We demonstrate that our model achieves competitive results in the relation prediction task when evaluated on a widely used dataset.