 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Recent Random Walk-based Methods for Embedding Knowledge Graphs
Jun 11, 2024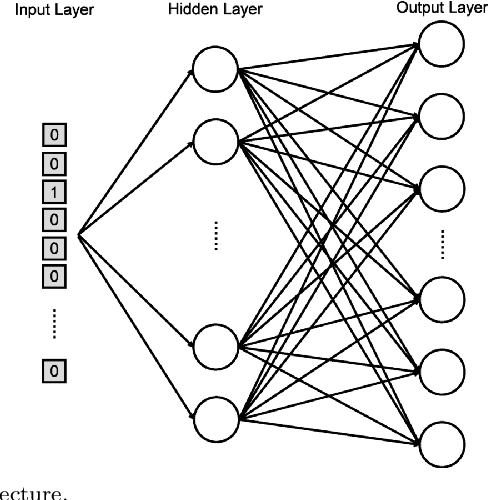
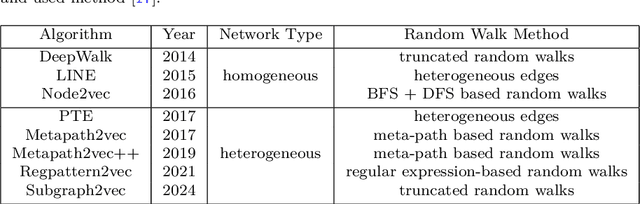
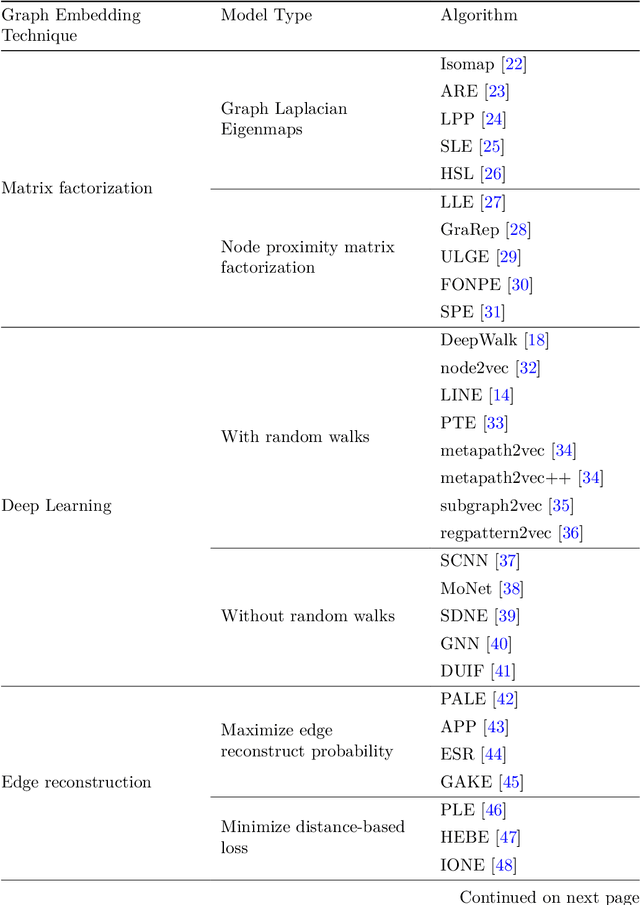

Machine learning, deep learning, and NLP methods on knowledge graphs are present in different fields and have important roles in various domains from self-driving cars to friend recommendations on social media platforms. However, to apply these methods to knowledge graphs, the data usually needs to be in an acceptable size and format. In fact, knowledge graphs normally have high dimensions and therefore we need to transform them to a low-dimensional vector space. An embedding is a low-dimensional space into which you can translate high dimensional vectors in a way that intrinsic features of the input data are preserved. In this review, we first explain knowledge graphs and their embedding and then review some of the random walk-based embedding methods that have been developed recently.
Subgraph2vec: A random walk-based algorithm for embedding knowledge graphs
May 03, 2024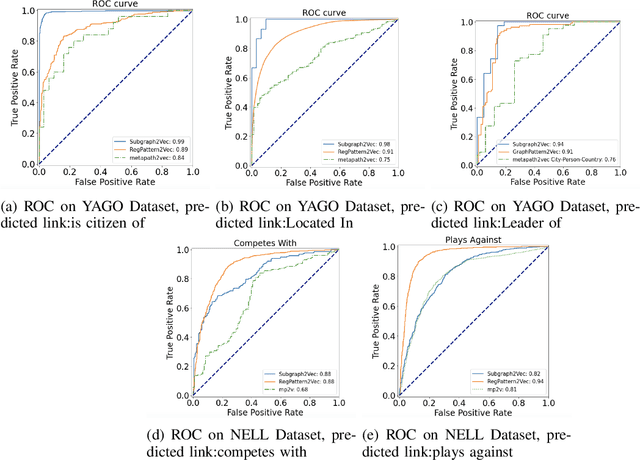
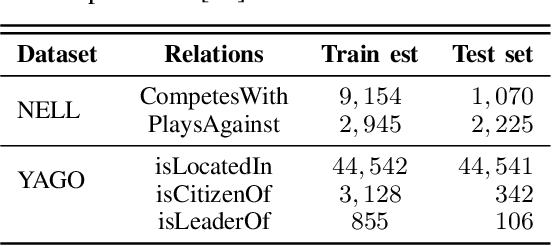
Graph is an important data representation which occurs naturally in the real world applications \cite{goyal2018graph}. Therefore, analyzing graphs provides users with better insights in different areas such as anomaly detection \cite{ma2021comprehensive}, decision making \cite{fan2023graph}, clustering \cite{tsitsulin2023graph}, classification \cite{wang2021mixup} and etc. However, most of these methods require high levels of computational time and space. We can use other ways like embedding to reduce these costs. Knowledge graph (KG) embedding is a technique that aims to achieve the vector representation of a KG. It represents entities and relations of a KG in a low-dimensional space while maintaining the semantic meanings of them. There are different methods for embedding graphs including random walk-based methods such as node2vec, metapath2vec and regpattern2vec. However, most of these methods bias the walks based on a rigid pattern usually hard-coded in the algorithm. In this work, we introduce \textit{subgraph2vec} for embedding KGs where walks are run inside a user-defined subgraph. We use this embedding for link prediction and prove our method has better performance in most cases in comparison with the previous ones.
A Survey on Recent Named Entity Recognition and Relation Classification Methods with Focus on Few-Shot Learning Approaches
Oct 29, 2023Named entity recognition and relation classification are key stages for extracting information from unstructured text. Several natural language processing applications utilize the two tasks, such as information retrieval, knowledge graph construction and completion, question answering and other domain-specific applications, such as biomedical data mining. We present a survey of recent approaches in the two tasks with focus on few-shot learning approaches. Our work compares the main approaches followed in the two paradigms. Additionally, we report the latest metric scores in the two tasks with a structured analysis that considers the results in the few-shot learning scope.
Multiple Relations Classification using Imbalanced Predictions Adaptation
Sep 24, 2023The relation classification task assigns the proper semantic relation to a pair of subject and object entities; the task plays a crucial role in various text mining applications, such as knowledge graph construction and entities interaction discovery in biomedical text. Current relation classification models employ additional procedures to identify multiple relations in a single sentence. Furthermore, they overlook the imbalanced predictions pattern. The pattern arises from the presence of a few valid relations that need positive labeling in a relatively large predefined relations set. We propose a multiple relations classification model that tackles these issues through a customized output architecture and by exploiting additional input features. Our findings suggest that handling the imbalanced predictions leads to significant improvements, even on a modest training design. The results demonstrate superiority performance on benchmark datasets commonly used in relation classification. To the best of our knowledge, this work is the first that recognizes the imbalanced predictions within the relation classification task.