 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple Relations Classification using Imbalanced Predictions Adaptation
Sep 24, 2023The relation classification task assigns the proper semantic relation to a pair of subject and object entities; the task plays a crucial role in various text mining applications, such as knowledge graph construction and entities interaction discovery in biomedical text. Current relation classification models employ additional procedures to identify multiple relations in a single sentence. Furthermore, they overlook the imbalanced predictions pattern. The pattern arises from the presence of a few valid relations that need positive labeling in a relatively large predefined relations set. We propose a multiple relations classification model that tackles these issues through a customized output architecture and by exploiting additional input features. Our findings suggest that handling the imbalanced predictions leads to significant improvements, even on a modest training design. The results demonstrate superiority performance on benchmark datasets commonly used in relation classification. To the best of our knowledge, this work is the first that recognizes the imbalanced predictions within the relation classification task.
WawPart: Workload-Aware Partitioning of Knowledge Graphs
Mar 28, 2022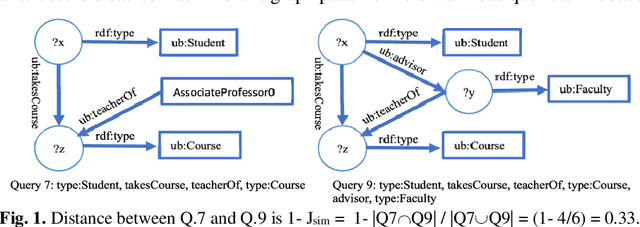
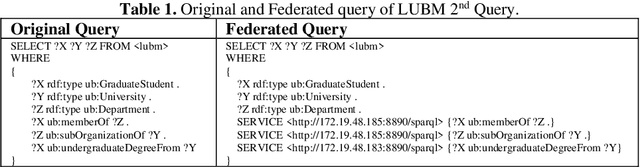
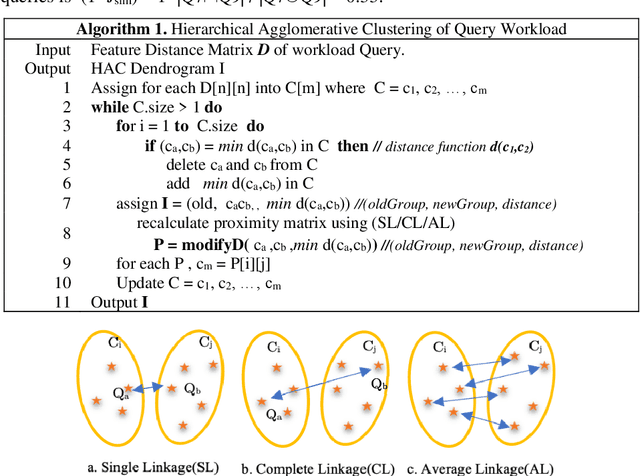
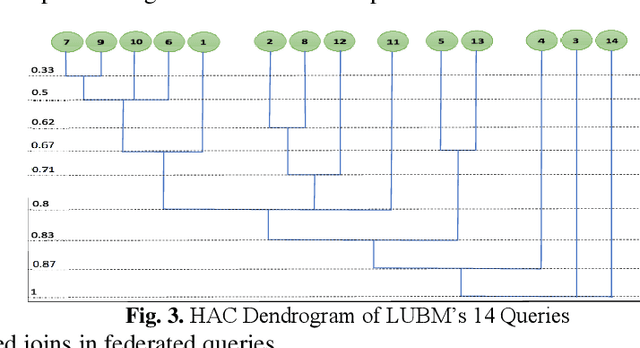
Large-scale datasets in the form of knowledge graphs are often used in numerous domains, today. A knowledge graphs size often exceeds the capacity of a single computer system, especially if the graph must be stored in main memory. To overcome this, knowledge graphs can be partitioned into multiple sub-graphs and distributed as shards among many computing nodes. However, performance of many common tasks performed on graphs, such as querying, suffers, as a result. This is due to distributed joins mandated by graph edges crossing (cutting) the partitions. In this paper, we propose a method of knowledge graph partitioning that takes into account a set of queries (workload). The resulting partitioning aims to reduces the number of distributed joins and improve the workload performance. Critical features identified in the query workload and the knowledge graph are used to cluster the queries and then partition the graph. Queries are rewritten to account for the graph partitioning. Our evaluation results demonstrate the performance improvement in workload processing time.
AWAPart: Adaptive Workload-Aware Partitioning of Knowledge Graphs
Mar 28, 2022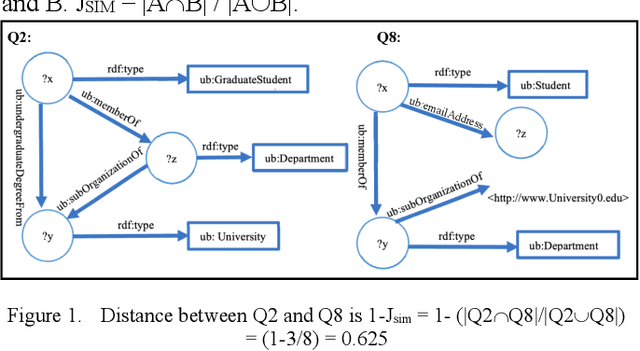
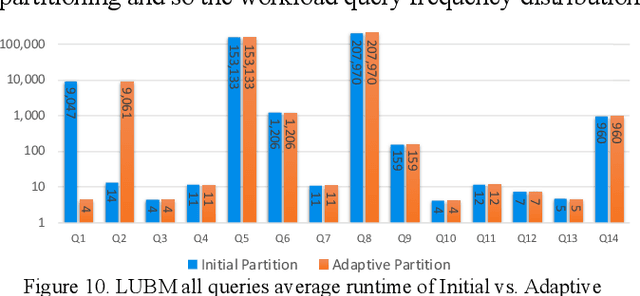
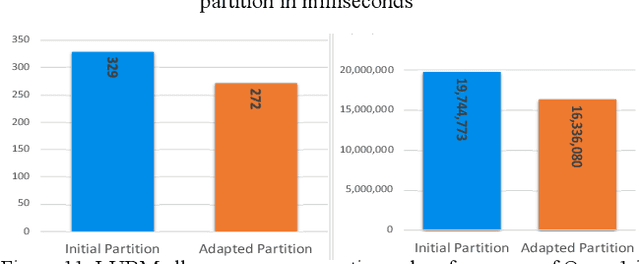

Large-scale knowledge graphs are increasingly common in many domains. Their large sizes often exceed the limits of systems storing the graphs in a centralized data store, especially if placed in main memory. To overcome this, large knowledge graphs need to be partitioned into multiple sub-graphs and placed in nodes in a distributed system. But querying these fragmented sub-graphs poses new challenges, such as increased communication costs, due to distributed joins involving cut edges. To combat these problems, a good partitioning should reduce the edge cuts while considering a given query workload. However, a partitioned graph needs to be continually re-partitioned to accommodate changes in the query workload and maintain a good average processing time. In this paper, an adaptive partitioning method for large-scale knowledge graphs is introduced, which adapts the partitioning in response to changes in the query workload. Our evaluation demonstrates that the performance of processing time for queries is improved after dynamically adapting the partitioning of knowledge graph triples.