 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWawPart: Workload-Aware Partitioning of Knowledge Graphs
Paper and Code
Mar 28, 2022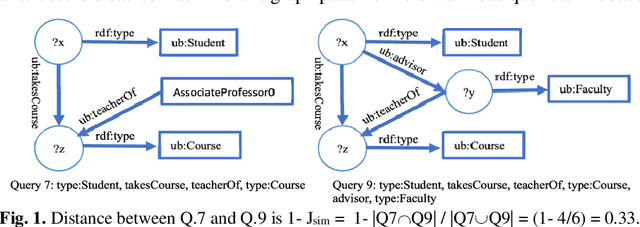
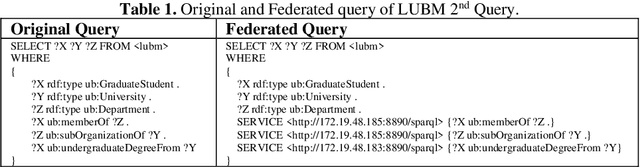
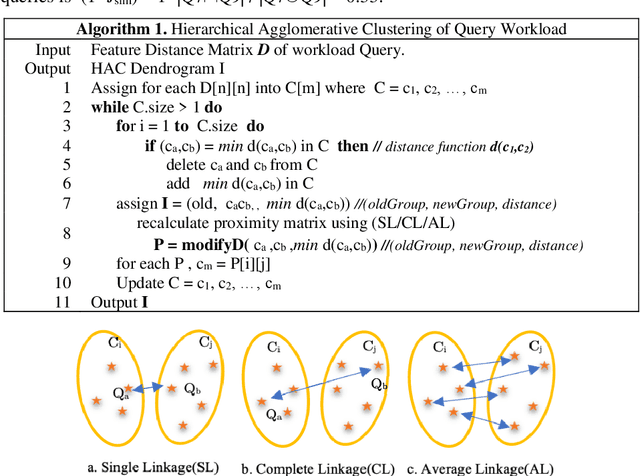
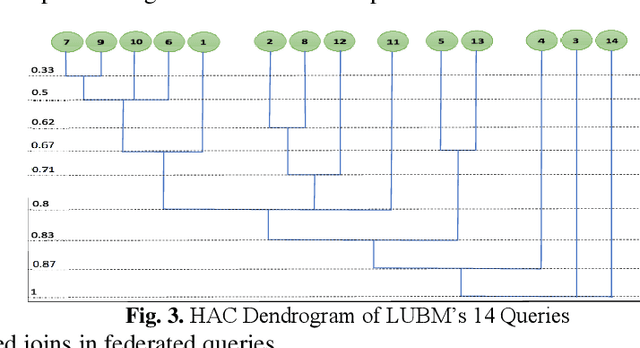
Large-scale datasets in the form of knowledge graphs are often used in numerous domains, today. A knowledge graphs size often exceeds the capacity of a single computer system, especially if the graph must be stored in main memory. To overcome this, knowledge graphs can be partitioned into multiple sub-graphs and distributed as shards among many computing nodes. However, performance of many common tasks performed on graphs, such as querying, suffers, as a result. This is due to distributed joins mandated by graph edges crossing (cutting) the partitions. In this paper, we propose a method of knowledge graph partitioning that takes into account a set of queries (workload). The resulting partitioning aims to reduces the number of distributed joins and improve the workload performance. Critical features identified in the query workload and the knowledge graph are used to cluster the queries and then partition the graph. Queries are rewritten to account for the graph partitioning. Our evaluation results demonstrate the performance improvement in workload processing time.