 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEXPANSE: A Deep Continual / Progressive Learning System for Deep Transfer Learning
May 24, 2022
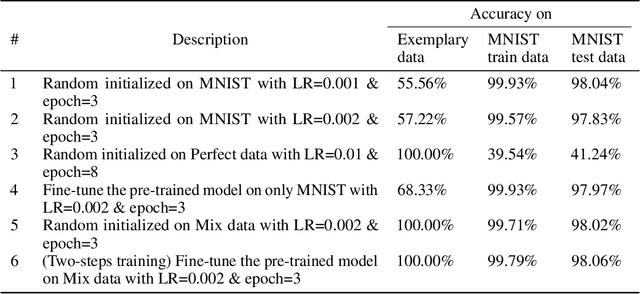
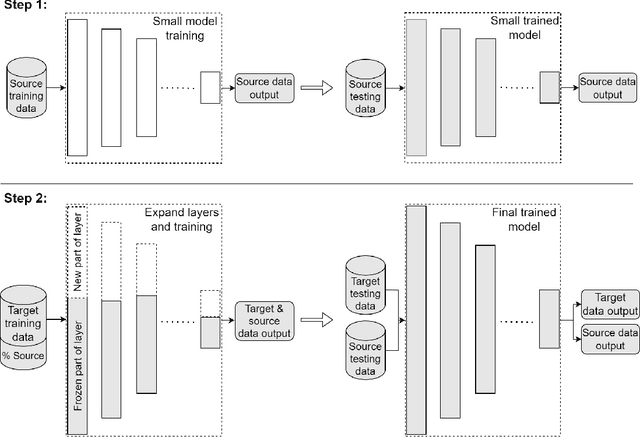
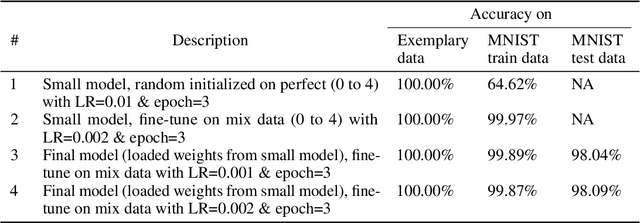
Deep transfer learning techniques try to tackle the limitations of deep learning, the dependency on extensive training data and the training costs, by reusing obtained knowledge. However, the current DTL techniques suffer from either catastrophic forgetting dilemma (losing the previously obtained knowledge) or overly biased pre-trained models (harder to adapt to target data) in finetuning pre-trained models or freezing a part of the pre-trained model, respectively. Progressive learning, a sub-category of DTL, reduces the effect of the overly biased model in the case of freezing earlier layers by adding a new layer to the end of a frozen pre-trained model. Even though it has been successful in many cases, it cannot yet handle distant source and target data. We propose a new continual/progressive learning approach for deep transfer learning to tackle these limitations. To avoid both catastrophic forgetting and overly biased-model problems, we expand the pre-trained model by expanding pre-trained layers (adding new nodes to each layer) in the model instead of only adding new layers. Hence the method is named EXPANSE. Our experimental results confirm that we can tackle distant source and target data using this technique. At the same time, the final model is still valid on the source data, achieving a promising deep continual learning approach. Moreover, we offer a new way of training deep learning models inspired by the human education system. We termed this two-step training: learning basics first, then adding complexities and uncertainties. The evaluation implies that the two-step training extracts more meaningful features and a finer basin on the error surface since it can achieve better accuracy in comparison to regular training. EXPANSE (model expansion and two-step training) is a systematic continual learning approach applicable to different problems and DL models.
A Review of Deep Transfer Learning and Recent Advancements
Jan 19, 2022A successful deep learning model is dependent on extensive training data and processing power and time (known as training costs). There exist many tasks without enough number of labeled data to train a deep learning model. Further, the demand is rising for running deep learning models on edge devices with limited processing capacity and training time. Deep transfer learning (DTL) methods are the answer to tackle such limitations, e.g., fine-tuning a pre-trained model on a massive semi-related dataset proved to be a simple and effective method for many problems. DTLs handle limited target data concerns as well as drastically reduce the training costs. In this paper, the definition and taxonomy of deep transfer learning is reviewed. Then we focus on the sub-category of network-based DTLs since it is the most common types of DTLs that have been applied to various applications in the last decade.
A Comparative Study of Machine Learning Models for Tabular Data Through Challenge of Monitoring Parkinson's Disease Progression Using Voice Recordings
May 27, 2020

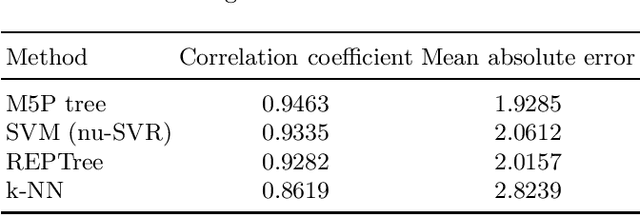

People with Parkinson's disease must be regularly monitored by their physician to observe how the disease is progressing and potentially adjust treatment plans to mitigate the symptoms. Monitoring the progression of the disease through a voice recording captured by the patient at their own home can make the process faster and less stressful. Using a dataset of voice recordings of 42 people with early-stage Parkinson's disease over a time span of 6 months, we applied multiple machine learning techniques to find a correlation between the voice recording and the patient's motor UPDRS score. We approached this problem using a multitude of both regression and classification techniques. Much of this paper is dedicated to mapping the voice data to motor UPDRS scores using regression techniques in order to obtain a more precise value for unknown instances. Through this comparative study of variant machine learning methods, we realized some old machine learning methods like trees outperform cutting edge deep learning models on numerous tabular datasets.