 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplicit Abstention Knobs for Predictable Reliability in Video Question Answering
Dec 31, 2025High-stakes deployment of vision-language models (VLMs) requires selective prediction, where systems abstain when uncertain rather than risk costly errors. We investigate whether confidence-based abstention provides reliable control over error rates in video question answering, and whether that control remains robust under distribution shift. Using NExT-QA and Gemini 2.0 Flash, we establish two findings. First, confidence thresholding provides mechanistic control in-distribution. Sweeping threshold epsilon produces smooth risk-coverage tradeoffs, reducing error rates f
A dual contrastive framework
Dec 13, 2024In current multimodal tasks, models typically freeze the encoder and decoder while adapting intermediate layers to task-specific goals, such as region captioning. Region-level visual understanding presents significant challenges for large-scale vision-language models. While limited spatial awareness is a known issue, coarse-grained pretraining, in particular, exacerbates the difficulty of optimizing latent representations for effective encoder-decoder alignment. We propose AlignCap, a framework designed to enhance region-level understanding through fine-grained alignment of latent spaces. Our approach introduces a novel latent feature refinement module that enhances conditioned latent space representations to improve region-level captioning performance. We also propose an innovative alignment strategy, the semantic space alignment module, which boosts the quality of multimodal representations. Additionally, we incorporate contrastive learning in a novel manner within both modules to further enhance region-level captioning performance. To address spatial limitations, we employ a General Object Detection (GOD) method as a data preprocessing pipeline that enhances spatial reasoning at the regional level. Extensive experiments demonstrate that our approach significantly improves region-level captioning performance across various tasks
The Streetscape Application Services Stack (SASS): Towards a Distributed Sensing Architecture for Urban Applications
Nov 29, 2024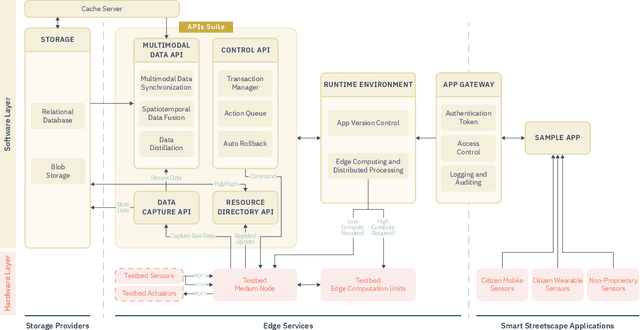

As urban populations grow, cities are becoming more complex, driving the deployment of interconnected sensing systems to realize the vision of smart cities. These systems aim to improve safety, mobility, and quality of life through applications that integrate diverse sensors with real-time decision-making. Streetscape applications-focusing on challenges like pedestrian safety and adaptive traffic management-depend on managing distributed, heterogeneous sensor data, aligning information across time and space, and enabling real-time processing. These tasks are inherently complex and often difficult to scale. The Streetscape Application Services Stack (SASS) addresses these challenges with three core services: multimodal data synchronization, spatiotemporal data fusion, and distributed edge computing. By structuring these capabilities as clear, composable abstractions with clear semantics, SASS allows developers to scale streetscape applications efficiently while minimizing the complexity of multimodal integration. We evaluated SASS in two real-world testbed environments: a controlled parking lot and an urban intersection in a major U.S. city. These testbeds allowed us to test SASS under diverse conditions, demonstrating its practical applicability. The Multimodal Data Synchronization service reduced temporal misalignment errors by 88%, achieving synchronization accuracy within 50 milliseconds. Spatiotemporal Data Fusion service improved detection accuracy for pedestrians and vehicles by over 10%, leveraging multicamera integration. The Distributed Edge Computing service increased system throughput by more than an order of magnitude. Together, these results show how SASS provides the abstractions and performance needed to support real-time, scalable urban applications, bridging the gap between sensing infrastructure and actionable streetscape intelligence.
Rapid Review of Generative AI in Smart Medical Applications
Jun 08, 2024With the continuous advancement of technology, artificial intelligence has significantly impacted various fields, particularly healthcare. Generative models, a key AI technology, have revolutionized medical image generation, data analysis, and diagnosis. This article explores their application in intelligent medical devices. Generative models enhance diagnostic speed and accuracy, improving medical service quality and efficiency while reducing equipment costs. These models show great promise in medical image generation, data analysis, and diagnosis. Additionally, integrating generative models with IoT technology facilitates real-time data analysis and predictions, offering smarter healthcare services and aiding in telemedicine. Challenges include computational demands, ethical concerns, and scenario-specific limitations.
Optimizing Autonomous Driving for Safety: A Human-Centric Approach with LLM-Enhanced RLHF
Jun 06, 2024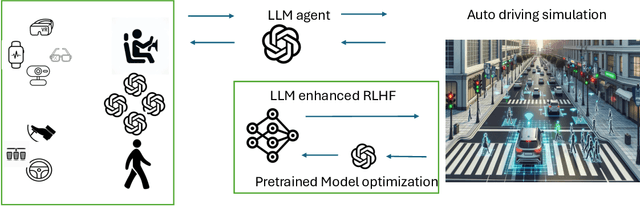

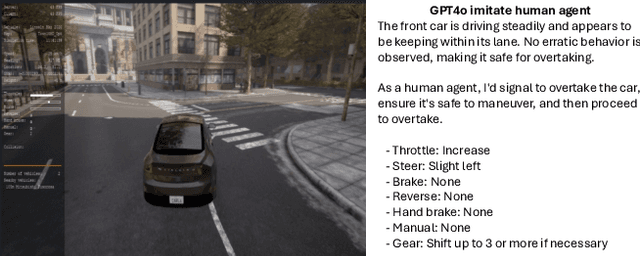

Reinforcement Learning from Human Feedback (RLHF) is popular in large language models (LLMs), whereas traditional Reinforcement Learning (RL) often falls short. Current autonomous driving methods typically utilize either human feedback in machine learning, including RL, or LLMs. Most feedback guides the car agent's learning process (e.g., controlling the car). RLHF is usually applied in the fine-tuning step, requiring direct human "preferences," which are not commonly used in optimizing autonomous driving models. In this research, we innovatively combine RLHF and LLMs to enhance autonomous driving safety. Training a model with human guidance from scratch is inefficient. Our framework starts with a pre-trained autonomous car agent model and implements multiple human-controlled agents, such as cars and pedestrians, to simulate real-life road environments. The autonomous car model is not directly controlled by humans. We integrate both physical and physiological feedback to fine-tune the model, optimizing this process using LLMs. This multi-agent interactive environment ensures safe, realistic interactions before real-world application. Finally, we will validate our model using data gathered from real-life testbeds located in New Jersey and New York City.
Comparing AI Algorithms for Optimizing Elliptic Curve Cryptography Parameters in Third-Party E-Commerce Integrations: A Pre-Quantum Era Analysis
Oct 10, 2023



This paper presents a comparative analysis between the Genetic Algorithm (GA) and Particle Swarm Optimization (PSO), two vital artificial intelligence algorithms, focusing on optimizing Elliptic Curve Cryptography (ECC) parameters. These encompass the elliptic curve coefficients, prime number, generator point, group order, and cofactor. The study provides insights into which of the bio-inspired algorithms yields better optimization results for ECC configurations, examining performances under the same fitness function. This function incorporates methods to ensure robust ECC parameters, including assessing for singular or anomalous curves and applying Pollard's rho attack and Hasse's theorem for optimization precision. The optimized parameters generated by GA and PSO are tested in a simulated e-commerce environment, contrasting with well-known curves like secp256k1 during the transmission of order messages using Elliptic Curve-Diffie Hellman (ECDH) and Hash-based Message Authentication Code (HMAC). Focusing on traditional computing in the pre-quantum era, this research highlights the efficacy of GA and PSO in ECC optimization, with implications for enhancing cybersecurity in third-party e-commerce integrations. We recommend the immediate consideration of these findings before quantum computing's widespread adoption.
GeXSe (Generative Explanatory Sensor System): An Interpretable Deep Generative Model for Human Activity Recognition in Smart Spaces
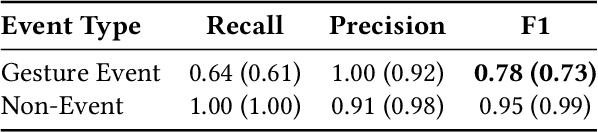
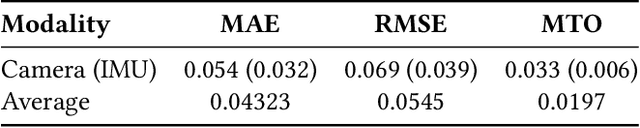
Jun 28, 2023We introduce GeXSe (Generative Explanatory Sensor System), a novel framework designed to extract interpretable sensor-based and vision domain features from non-invasive smart space sensors. We combine these to provide a comprehensive explanation of sensor-activation patterns in activity recognition tasks. This system leverages advanced machine learning architectures, including transformer blocks, Fast Fourier Convolution (FFC), and diffusion models, to provide a more detailed understanding of sensor-based human activity data. A standout feature of GeXSe is our unique Multi-Layer Perceptron (MLP) with linear, ReLU, and normalization layers, specially devised for optimal performance on small datasets. It also yields meaningful activation maps to explain sensor-based activation patterns. The standard approach is based on a CNN model, which our MLP model outperforms.GeXSe offers two types of explanations: sensor-based activation maps and visual domain explanations using short videos. These methods offer a comprehensive interpretation of the output from non-interpretable sensor data, thereby augmenting the interpretability of our model. Utilizing the Frechet Inception Distance (FID) for evaluation, it outperforms established methods, improving baseline performance by about 6\%. GeXSe also achieves a high F1 score of up to 0.85, demonstrating precision, recall, and noise resistance, marking significant progress in reliable and explainable smart space sensing systems.
Cadence: A Practical Time-series Partitioning Algorithm for Unlabeled IoT Sensor Streams
Dec 06, 2021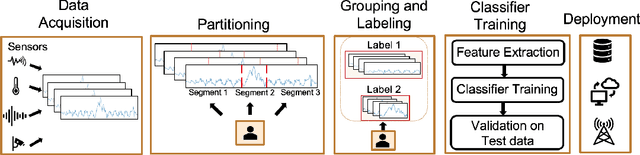
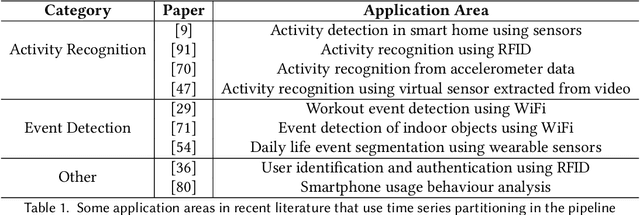
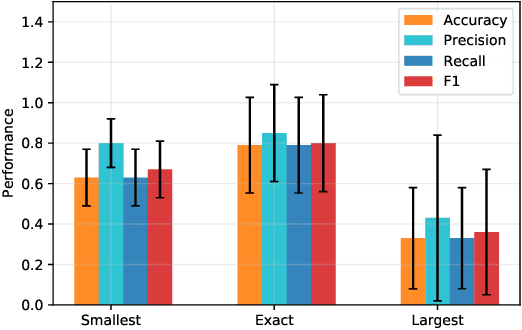
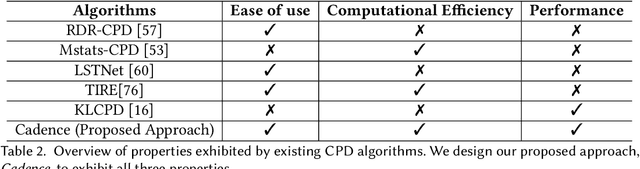
Timeseries partitioning is an essential step in most machine-learning driven, sensor-based IoT applications. This paper introduces a sample-efficient, robust, time-series segmentation model and algorithm. We show that by learning a representation specifically with the segmentation objective based on maximum mean discrepancy (MMD), our algorithm can robustly detect time-series events across different applications. Our loss function allows us to infer whether consecutive sequences of samples are drawn from the same distribution (null hypothesis) and determines the change-point between pairs that reject the null hypothesis (i.e., come from different distributions). We demonstrate its applicability in a real-world IoT deployment for ambient-sensing based activity recognition. Moreover, while many works on change-point detection exist in the literature, our model is significantly simpler and matches or outperforms state-of-the-art methods. We can fully train our model in 9-93 seconds on average with little variation in hyperparameters for data across different applications.
A Review of the Non-Invasive Techniques for Monitoring Different Aspects of Sleep
Apr 27, 2021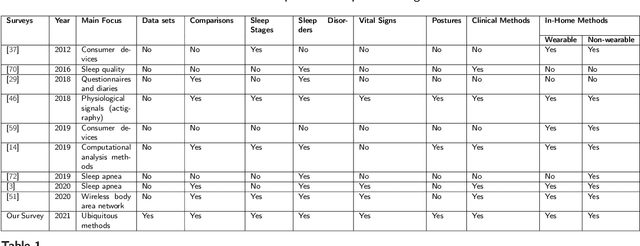
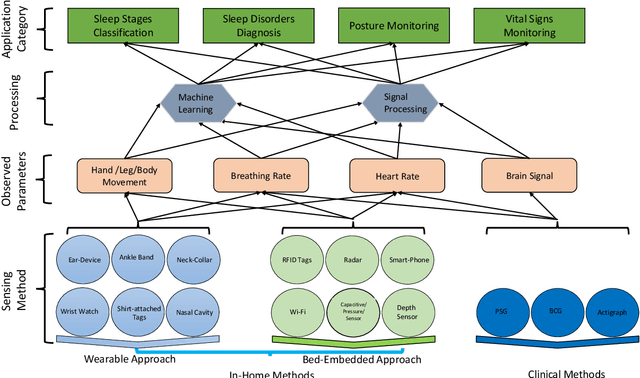
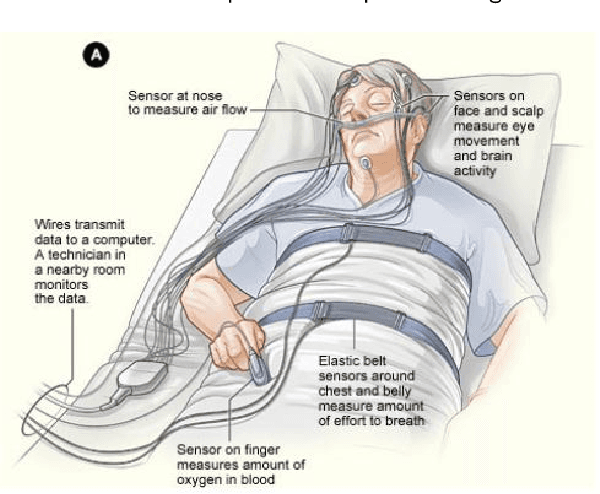
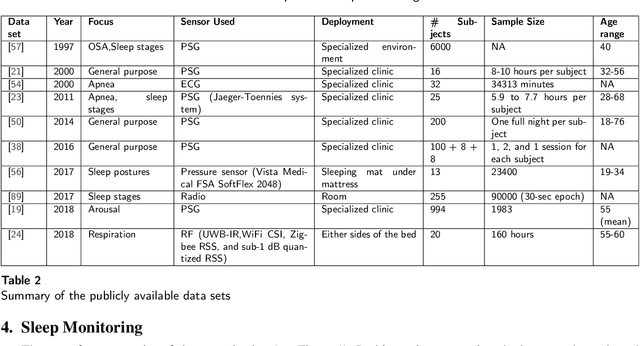
Quality sleep is very important for a healthy life. Nowadays, many people around the world are not getting enough sleep which is having negative impacts on their lifestyles. Studies are being conducted for sleep monitoring and have now become an important tool for understanding sleep behavior. The gold standard method for sleep analysis is polysomnography (PSG) conducted in a clinical environment but this method is both expensive and complex for long-term use. With the advancements in the field of sensors and the introduction of off-the-shelf technologies, unobtrusive solutions are becoming common as alternatives for in-home sleep monitoring. Various solutions have been proposed using both wearable and non-wearable methods which are cheap and easy to use for in-home sleep monitoring. In this paper, we present a comprehensive survey of the latest research works (2015 and after) conducted in various categories of sleep monitoring including sleep stage classification, sleep posture recognition, sleep disorders detection, and vital signs monitoring. We review the latest works done using the non-invasive approach and cover both wearable and non-wearable methods. We discuss the design approaches and key attributes of the work presented and provide an extensive analysis based on 10 key factors, to give a comprehensive overview of the recent developments and trends in all four categories of sleep monitoring. We also present some publicly available datasets for different categories of sleep monitoring. In the end, we discuss several open issues and provide future research directions in the area of sleep monitoring.
RLAD: Time Series Anomaly Detection through Reinforcement Learning and Active Learning
Mar 31, 2021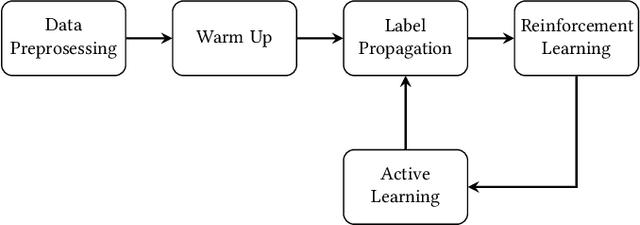
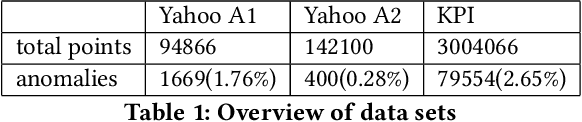
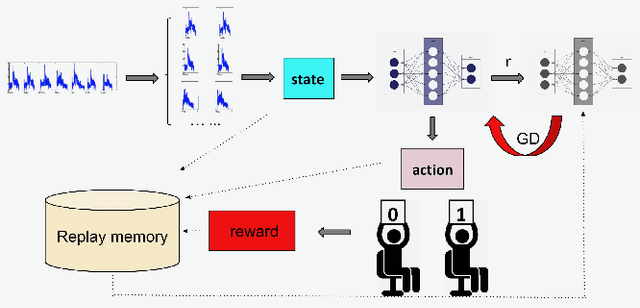
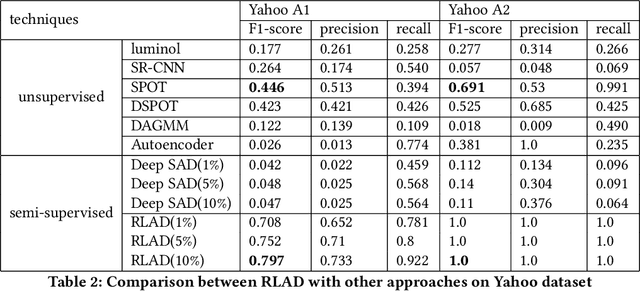
We introduce a new semi-supervised, time series anomaly detection algorithm that uses deep reinforcement learning (DRL) and active learning to efficiently learn and adapt to anomalies in real-world time series data. Our model - called RLAD - makes no assumption about the underlying mechanism that produces the observation sequence and continuously adapts the detection model based on experience with anomalous patterns. In addition, it requires no manual tuning of parameters and outperforms all state-of-art methods we compare with, both unsupervised and semi-supervised, across several figures of merit. More specifically, we outperform the best unsupervised approach by a factor of 1.58 on the F1 score, with only 1% of labels and up to around 4.4x on another real-world dataset with only 0.1% of labels. We compare RLAD with seven deep-learning based algorithms across two common anomaly detection datasets with up to around 3M data points and between 0.28% to 2.65% anomalies.We outperform all of them across several important performance metrics.