 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Vision-Based Analysis of Congestion Pricing in New York City
Feb 03, 2026We examine the impact of New York City's congestion pricing program through automated analysis of traffic camera data. Our computer vision pipeline processes footage from over 900 cameras distributed throughout Manhattan and New York, comparing traffic patterns from November 2024 through the program's implementation in January 2025 until January 2026. We establish baseline traffic patterns and identify systematic changes in vehicle density across the monitored region.
Towards Suturing World Models: Learning Predictive Models for Robotic Surgical Tasks
Mar 16, 2025



We introduce specialized diffusion-based generative models that capture the spatiotemporal dynamics of fine-grained robotic surgical sub-stitch actions through supervised learning on annotated laparoscopic surgery footage. The proposed models form a foundation for data-driven world models capable of simulating the biomechanical interactions and procedural dynamics of surgical suturing with high temporal fidelity. Annotating a dataset of $\sim2K$ clips extracted from simulation videos, we categorize surgical actions into fine-grained sub-stitch classes including ideal and non-ideal executions of needle positioning, targeting, driving, and withdrawal. We fine-tune two state-of-the-art video diffusion models, LTX-Video and HunyuanVideo, to generate high-fidelity surgical action sequences at $\ge$768x512 resolution and $\ge$49 frames. For training our models, we explore both Low-Rank Adaptation (LoRA) and full-model fine-tuning approaches. Our experimental results demonstrate that these world models can effectively capture the dynamics of suturing, potentially enabling improved training simulators, surgical skill assessment tools, and autonomous surgical systems. The models also display the capability to differentiate between ideal and non-ideal technique execution, providing a foundation for building surgical training and evaluation systems. We release our models for testing and as a foundation for future research. Project Page: https://mkturkcan.github.io/suturingmodels/
The Streetscape Application Services Stack (SASS): Towards a Distributed Sensing Architecture for Urban Applications
Nov 29, 2024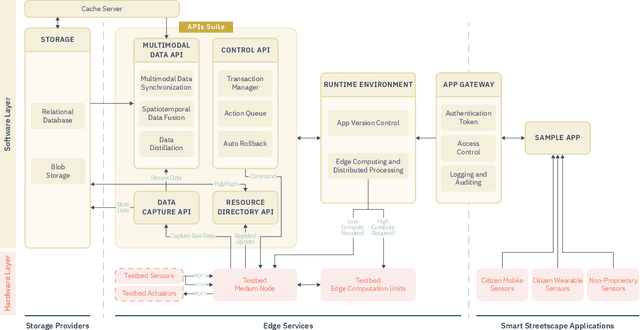
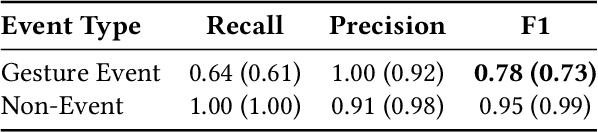

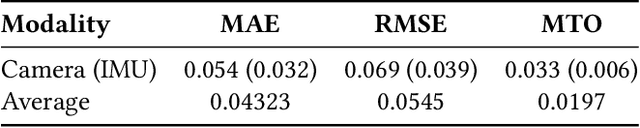
As urban populations grow, cities are becoming more complex, driving the deployment of interconnected sensing systems to realize the vision of smart cities. These systems aim to improve safety, mobility, and quality of life through applications that integrate diverse sensors with real-time decision-making. Streetscape applications-focusing on challenges like pedestrian safety and adaptive traffic management-depend on managing distributed, heterogeneous sensor data, aligning information across time and space, and enabling real-time processing. These tasks are inherently complex and often difficult to scale. The Streetscape Application Services Stack (SASS) addresses these challenges with three core services: multimodal data synchronization, spatiotemporal data fusion, and distributed edge computing. By structuring these capabilities as clear, composable abstractions with clear semantics, SASS allows developers to scale streetscape applications efficiently while minimizing the complexity of multimodal integration. We evaluated SASS in two real-world testbed environments: a controlled parking lot and an urban intersection in a major U.S. city. These testbeds allowed us to test SASS under diverse conditions, demonstrating its practical applicability. The Multimodal Data Synchronization service reduced temporal misalignment errors by 88%, achieving synchronization accuracy within 50 milliseconds. Spatiotemporal Data Fusion service improved detection accuracy for pedestrians and vehicles by over 10%, leveraging multicamera integration. The Distributed Edge Computing service increased system throughput by more than an order of magnitude. Together, these results show how SASS provides the abstractions and performance needed to support real-time, scalable urban applications, bridging the gap between sensing infrastructure and actionable streetscape intelligence.
Boundless: Generating Photorealistic Synthetic Data for Object Detection in Urban Streetscapes
Sep 04, 2024
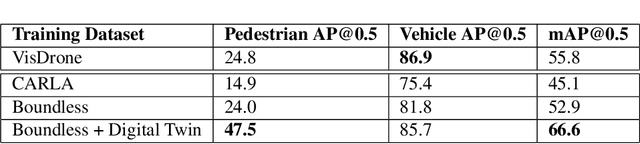

We introduce Boundless, a photo-realistic synthetic data generation system for enabling highly accurate object detection in dense urban streetscapes. Boundless can replace massive real-world data collection and manual ground-truth object annotation (labeling) with an automated and configurable process. Boundless is based on the Unreal Engine 5 (UE5) City Sample project with improvements enabling accurate collection of 3D bounding boxes across different lighting and scene variability conditions. We evaluate the performance of object detection models trained on the dataset generated by Boundless when used for inference on a real-world dataset acquired from medium-altitude cameras. We compare the performance of the Boundless-trained model against the CARLA-trained model and observe an improvement of 7.8 mAP. The results we achieved support the premise that synthetic data generation is a credible methodology for training/fine-tuning scalable object detection models for urban scenes.
Data-Driven Traffic Simulation for an Intersection in a Metropolis
Aug 01, 2024
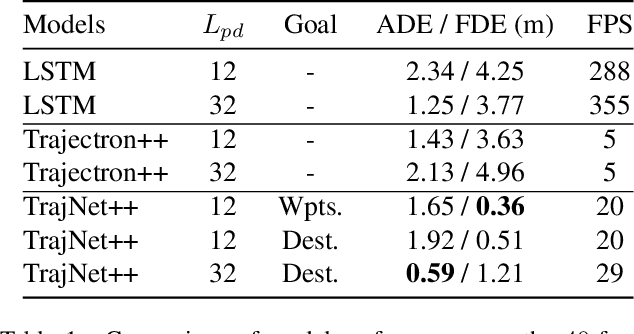
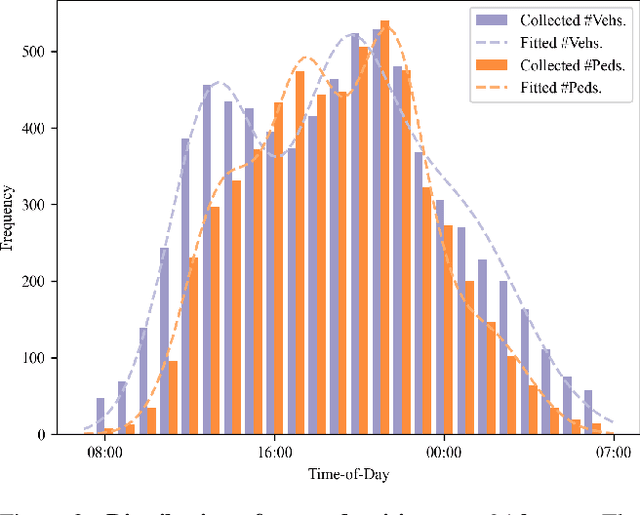
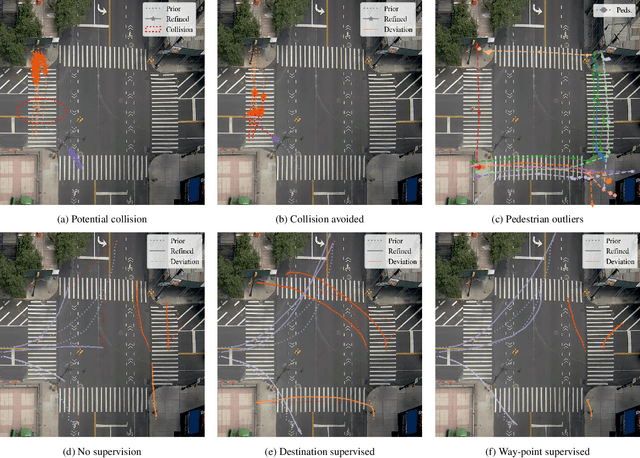
We present a novel data-driven simulation environment for modeling traffic in metropolitan street intersections. Using real-world tracking data collected over an extended period of time, we train trajectory forecasting models to learn agent interactions and environmental constraints that are difficult to capture conventionally. Trajectories of new agents are first coarsely generated by sampling from the spatial and temporal generative distributions, then refined using state-of-the-art trajectory forecasting models. The simulation can run either autonomously, or under explicit human control conditioned on the generative distributions. We present the experiments for a variety of model configurations. Under an iterative prediction scheme, the way-point-supervised TrajNet++ model obtained 0.36 Final Displacement Error (FDE) in 20 FPS on an NVIDIA A100 GPU.
Constellation Dataset: Benchmarking High-Altitude Object Detection for an Urban Intersection
Apr 25, 2024



We introduce Constellation, a dataset of 13K images suitable for research on detection of objects in dense urban streetscapes observed from high-elevation cameras, collected for a variety of temporal conditions. The dataset addresses the need for curated data to explore problems in small object detection exemplified by the limited pixel footprint of pedestrians observed tens of meters from above. It enables the testing of object detection models for variations in lighting, building shadows, weather, and scene dynamics. We evaluate contemporary object detection architectures on the dataset, observing that state-of-the-art methods have lower performance in detecting small pedestrians compared to vehicles, corresponding to a 10% difference in average precision (AP). Using structurally similar datasets for pretraining the models results in an increase of 1.8% mean AP (mAP). We further find that incorporating domain-specific data augmentations helps improve model performance. Using pseudo-labeled data, obtained from inference outcomes of the best-performing models, improves the performance of the models. Finally, comparing the models trained using the data collected in two different time intervals, we find a performance drift in models due to the changes in intersection conditions over time. The best-performing model achieves a pedestrian AP of 92.0% with 11.5 ms inference time on NVIDIA A100 GPUs, and an mAP of 95.4%.
Examining the Influence of Varied Levels of Domain Knowledge Base Inclusion in GPT-based Intelligent Tutors
Sep 16, 2023

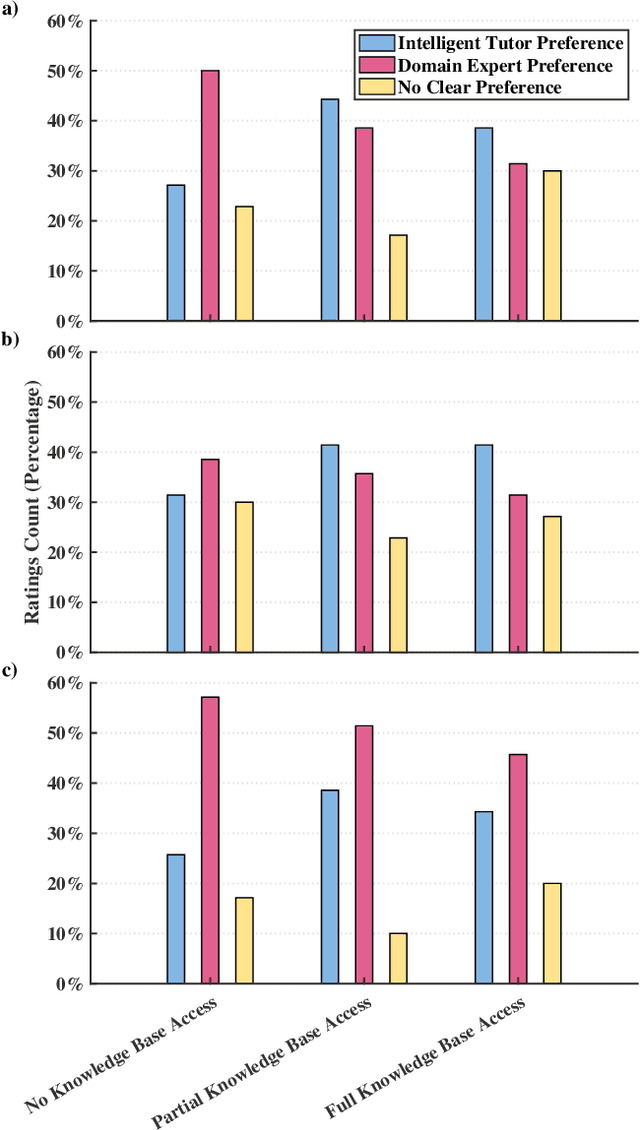
Recent advancements in large language models (LLMs) have facilitated the development of chatbots with sophisticated conversational capabilities. However, LLMs exhibit frequent inaccurate responses to queries, hindering applications in educational settings. In this paper, we investigate the effectiveness of integrating a knowledge base (KB) with LLM intelligent tutors to increase response reliability. To achieve this, we design a scaleable KB that affords educational supervisors seamless integration of lesson curricula, which is automatically processed by the intelligent tutoring system. We then detail an evaluation, where student participants were presented with questions about the artificial intelligence curriculum to respond to. GPT-4 intelligent tutors with varying hierarchies of KB access and human domain experts then assessed these responses. Lastly, students cross-examined the intelligent tutors' responses to the domain experts' and ranked their various pedagogical abilities. Results suggest that, although these intelligent tutors still demonstrate a lower accuracy compared to domain experts, the accuracy of the intelligent tutors increases when access to a KB is granted. We also observe that the intelligent tutors with KB access exhibit better pedagogical abilities to speak like a teacher and understand students than those of domain experts, while their ability to help students remains lagging behind domain experts.