 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Streetscape Application Services Stack (SASS): Towards a Distributed Sensing Architecture for Urban Applications
Nov 29, 2024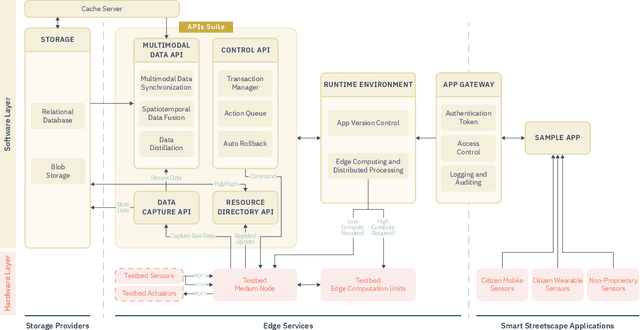
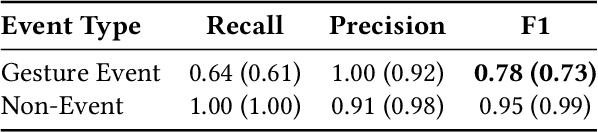

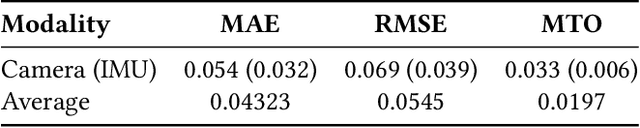
As urban populations grow, cities are becoming more complex, driving the deployment of interconnected sensing systems to realize the vision of smart cities. These systems aim to improve safety, mobility, and quality of life through applications that integrate diverse sensors with real-time decision-making. Streetscape applications-focusing on challenges like pedestrian safety and adaptive traffic management-depend on managing distributed, heterogeneous sensor data, aligning information across time and space, and enabling real-time processing. These tasks are inherently complex and often difficult to scale. The Streetscape Application Services Stack (SASS) addresses these challenges with three core services: multimodal data synchronization, spatiotemporal data fusion, and distributed edge computing. By structuring these capabilities as clear, composable abstractions with clear semantics, SASS allows developers to scale streetscape applications efficiently while minimizing the complexity of multimodal integration. We evaluated SASS in two real-world testbed environments: a controlled parking lot and an urban intersection in a major U.S. city. These testbeds allowed us to test SASS under diverse conditions, demonstrating its practical applicability. The Multimodal Data Synchronization service reduced temporal misalignment errors by 88%, achieving synchronization accuracy within 50 milliseconds. Spatiotemporal Data Fusion service improved detection accuracy for pedestrians and vehicles by over 10%, leveraging multicamera integration. The Distributed Edge Computing service increased system throughput by more than an order of magnitude. Together, these results show how SASS provides the abstractions and performance needed to support real-time, scalable urban applications, bridging the gap between sensing infrastructure and actionable streetscape intelligence.
VCHAR:Variance-Driven Complex Human Activity Recognition framework with Generative Representation
Jul 03, 2024Complex human activity recognition (CHAR) remains a pivotal challenge within ubiquitous computing, especially in the context of smart environments. Existing studies typically require meticulous labeling of both atomic and complex activities, a task that is labor-intensive and prone to errors due to the scarcity and inaccuracies of available datasets. Most prior research has focused on datasets that either precisely label atomic activities or, at minimum, their sequence approaches that are often impractical in real world settings.In response, we introduce VCHAR (Variance-Driven Complex Human Activity Recognition), a novel framework that treats the outputs of atomic activities as a distribution over specified intervals. Leveraging generative methodologies, VCHAR elucidates the reasoning behind complex activity classifications through video-based explanations, accessible to users without prior machine learning expertise. Our evaluation across three publicly available datasets demonstrates that VCHAR enhances the accuracy of complex activity recognition without necessitating precise temporal or sequential labeling of atomic activities. Furthermore, user studies confirm that VCHAR's explanations are more intelligible compared to existing methods, facilitating a broader understanding of complex activity recognition among non-experts.
Optimizing Autonomous Driving for Safety: A Human-Centric Approach with LLM-Enhanced RLHF
Jun 06, 2024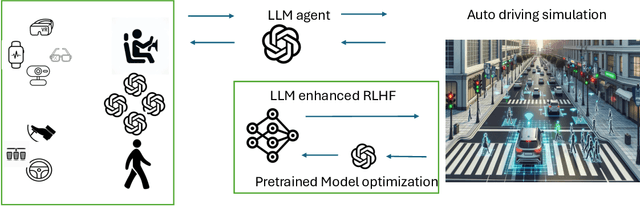

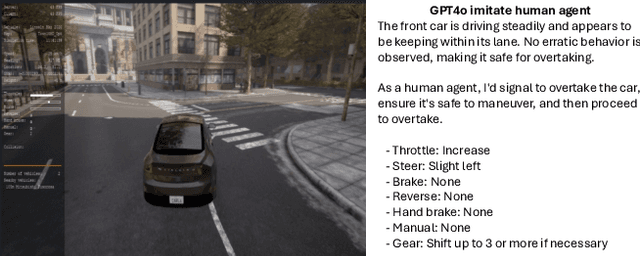

Reinforcement Learning from Human Feedback (RLHF) is popular in large language models (LLMs), whereas traditional Reinforcement Learning (RL) often falls short. Current autonomous driving methods typically utilize either human feedback in machine learning, including RL, or LLMs. Most feedback guides the car agent's learning process (e.g., controlling the car). RLHF is usually applied in the fine-tuning step, requiring direct human "preferences," which are not commonly used in optimizing autonomous driving models. In this research, we innovatively combine RLHF and LLMs to enhance autonomous driving safety. Training a model with human guidance from scratch is inefficient. Our framework starts with a pre-trained autonomous car agent model and implements multiple human-controlled agents, such as cars and pedestrians, to simulate real-life road environments. The autonomous car model is not directly controlled by humans. We integrate both physical and physiological feedback to fine-tune the model, optimizing this process using LLMs. This multi-agent interactive environment ensures safe, realistic interactions before real-world application. Finally, we will validate our model using data gathered from real-life testbeds located in New Jersey and New York City.