 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSECRET: Semantically Enhanced Classification of Real-world Tasks
May 29, 2019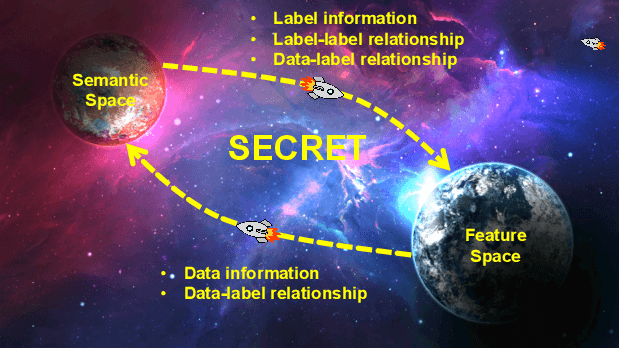
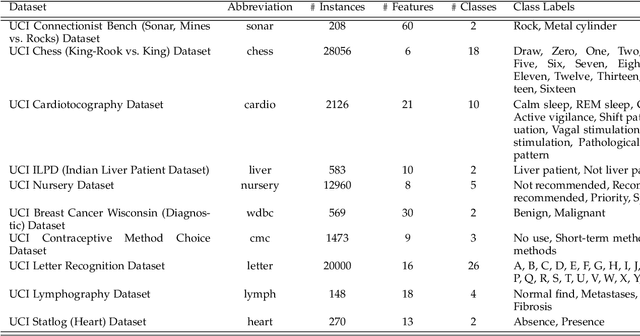
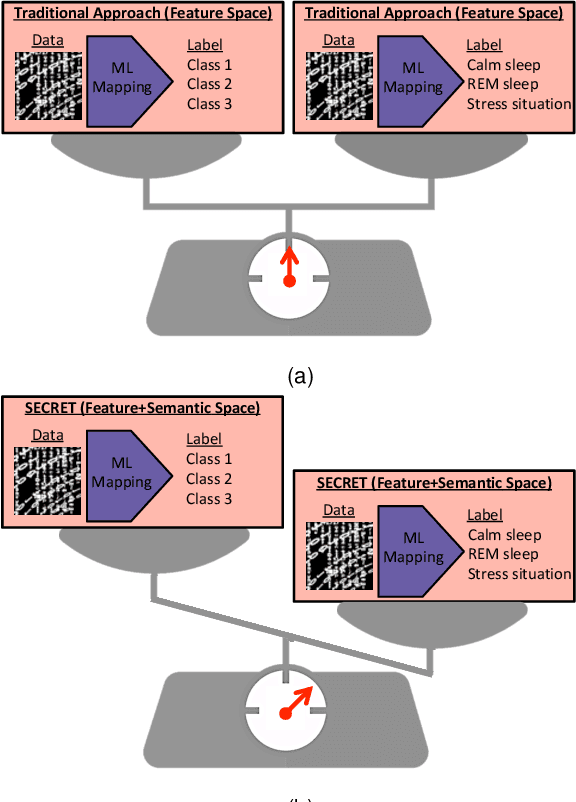
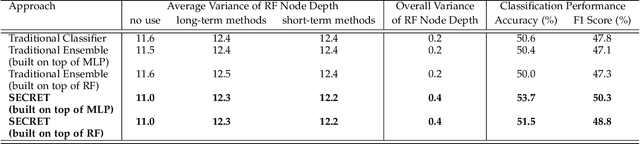
Supervised machine learning (ML) algorithms are aimed at maximizing classification performance under available energy and storage constraints. They try to map the training data to the corresponding labels while ensuring generalizability to unseen data. However, they do not integrate meaning-based relationships among labels in the decision process. On the other hand, natural language processing (NLP) algorithms emphasize the importance of semantic information. In this paper, we synthesize the complementary advantages of supervised ML and natural language processing algorithms into one method that we refer to as SECRET (Semantically Enhanced Classification of REal-world Tasks). SECRET performs classifications by fusing the semantic information of the labels with the available data: it combines the feature space of the supervised algorithms with the semantic space of the NLP algorithms and predicts labels based on this joint space. Experimental results indicate that, compared to traditional supervised learning, SECRET achieves up to 13.9% accuracy and 13.5% F1 score improvements. Moreover, compared to ensemble methods, SECRET achieves up to 12.6% accuracy and 13.8% F1 score improvements. This points to a new research direction for supervised classification by incorporating semantic information.
Time Series Segmentation through Automatic Feature Learning
Jan 26, 2018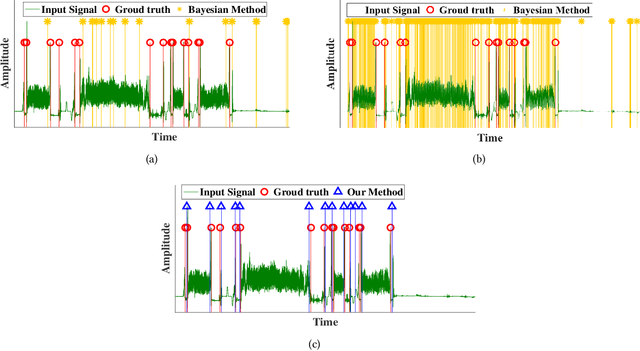
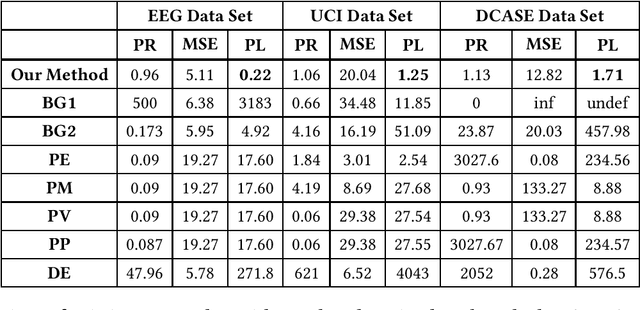
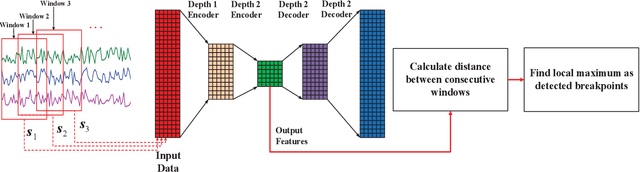
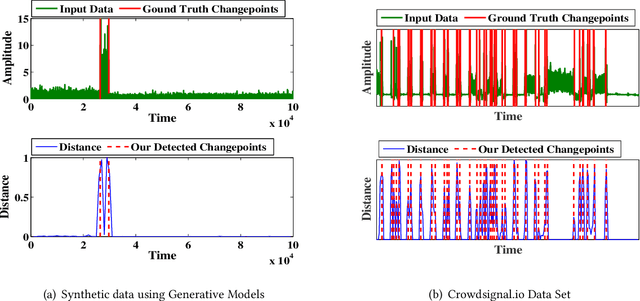
Internet of things (IoT) applications have become increasingly popular in recent years, with applications ranging from building energy monitoring to personal health tracking and activity recognition. In order to leverage these data, automatic knowledge extraction - whereby we map from observations to interpretable states and transitions - must be done at scale. As such, we have seen many recent IoT data sets include annotations with a human expert specifying states, recorded as a set of boundaries and associated labels in a data sequence. These data can be used to build automatic labeling algorithms that produce labels as an expert would. Here, we refer to human-specified boundaries as breakpoints. Traditional changepoint detection methods only look for statistically-detectable boundaries that are defined as abrupt variations in the generative parameters of a data sequence. However, we observe that breakpoints occur on more subtle boundaries that are non-trivial to detect with these statistical methods. In this work, we propose a new unsupervised approach, based on deep learning, that outperforms existing techniques and learns the more subtle, breakpoint boundaries with a high accuracy. Through extensive experiments on various real-world data sets - including human-activity sensing data, speech signals, and electroencephalogram (EEG) activity traces - we demonstrate the effectiveness of our algorithm for practical applications. Furthermore, we show that our approach achieves significantly better performance than previous methods.