 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Customization of LLMs for Enterprise Code Repositories Using Semantic Scopes
Feb 05, 2026Code completion (CC) is a task frequently used by developers when working in collaboration with LLM-based programming assistants. Despite the increased performance of LLMs on public benchmarks, out of the box LLMs still have a hard time generating code that aligns with a private code repository not previously seen by the model's training data. Customizing code LLMs to a private repository provides a way to improve the model performance. In this paper we present our approach for automated LLM customization based on semantic scopes in the code. We evaluate LLMs on real industry cases with two private enterprise code repositories with two customization strategies: Retrieval-Augmented Generation (RAG) and supervised Fine-Tuning (FT). Our mechanism for ingesting the repository's data and formulating the training data pairs with semantic scopes helps models to learn the underlying patterns specific to the repository, providing more precise code to developers and helping to boost their productivity. The code completions of moderately sized customized models can be significantly better than those of uncustomized models of much larger capacity. We also include an analysis of customization on two public benchmarks and present opportunities for future work.
Domain Adaptation of a State of the Art Text-to-SQL Model: Lessons Learned and Challenges Found
Dec 09, 2023


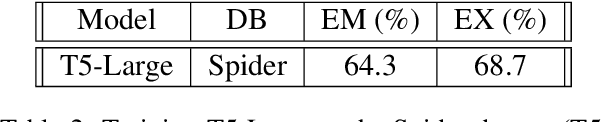
There are many recent advanced developments for the Text-to-SQL task, where the Picard model is one of the the top performing models as measured by the Spider dataset competition. However, bringing Text-to-SQL systems to realistic use-cases through domain adaptation remains a tough challenge. We analyze how well the base T5 Language Model and Picard perform on query structures different from the Spider dataset, we fine-tuned the base model on the Spider data and on independent databases (DB). To avoid accessing the DB content online during inference, we also present an alternative way to disambiguate the values in an input question using a rule-based approach that relies on an intermediate representation of the semantic concepts of an input question. In our results we show in what cases T5 and Picard can deliver good performance, we share the lessons learned, and discuss current domain adaptation challenges.
Recognizing and Splitting Conditional Sentences for Automation of Business Processes Management
Apr 01, 2021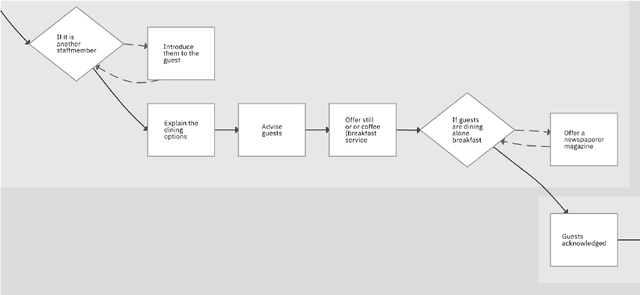


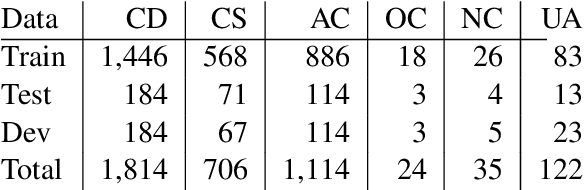
Business Process Management (BPM) is the discipline which is responsible for management of discovering, analyzing, redesigning, monitoring, and controlling business processes. One of the most crucial tasks of BPM is discovering and modelling business processes from text documents. In this paper, we present our system that resolves an end-to-end problem consisting of 1) recognizing conditional sentences from technical documents, 2) finding boundaries to extract conditional and resultant clauses from each conditional sentence, and 3) categorizing resultant clause as Action or Consequence which later helps to generate new steps in our business process model automatically. We created a new dataset and three models solve this problem. Our best model achieved very promising results of 83.82, 87.84, and 85.75 for Precision, Recall, and F1, respectively, for extracting Condition, Action, and Consequence clauses using Exact Match metric.
SECRET: Semantically Enhanced Classification of Real-world Tasks
May 29, 2019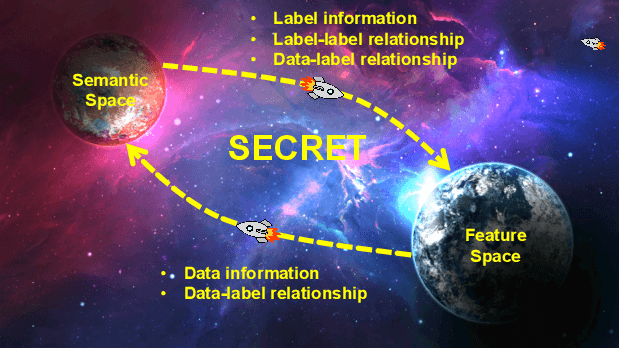
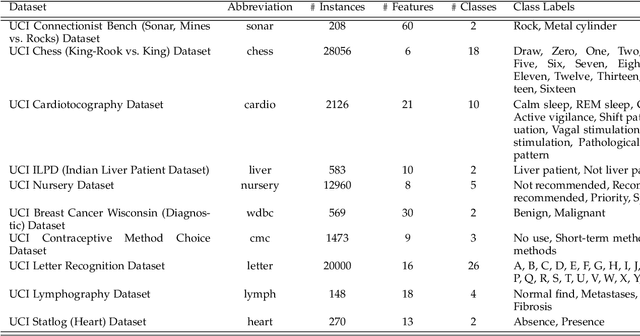
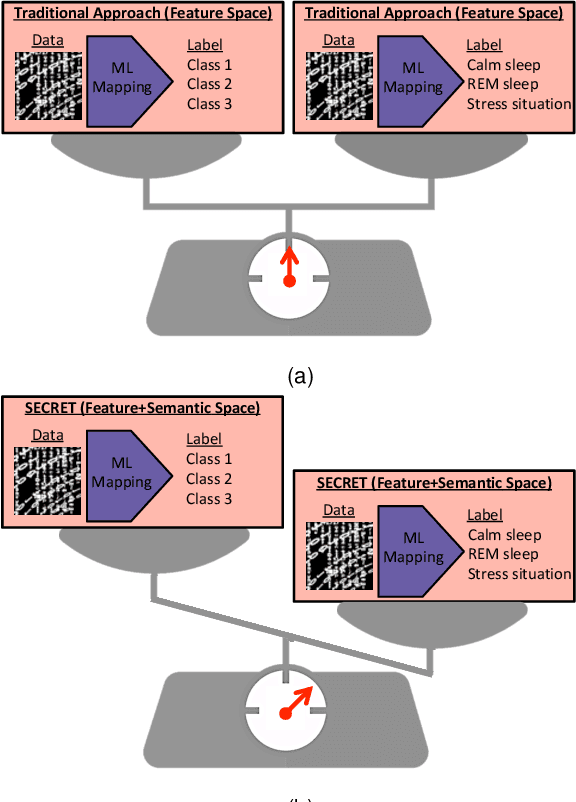
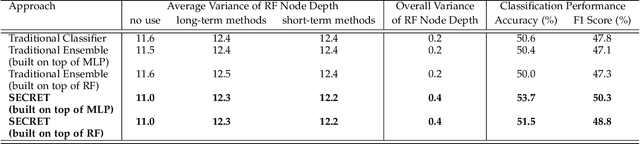
Supervised machine learning (ML) algorithms are aimed at maximizing classification performance under available energy and storage constraints. They try to map the training data to the corresponding labels while ensuring generalizability to unseen data. However, they do not integrate meaning-based relationships among labels in the decision process. On the other hand, natural language processing (NLP) algorithms emphasize the importance of semantic information. In this paper, we synthesize the complementary advantages of supervised ML and natural language processing algorithms into one method that we refer to as SECRET (Semantically Enhanced Classification of REal-world Tasks). SECRET performs classifications by fusing the semantic information of the labels with the available data: it combines the feature space of the supervised algorithms with the semantic space of the NLP algorithms and predicts labels based on this joint space. Experimental results indicate that, compared to traditional supervised learning, SECRET achieves up to 13.9% accuracy and 13.5% F1 score improvements. Moreover, compared to ensemble methods, SECRET achieves up to 12.6% accuracy and 13.8% F1 score improvements. This points to a new research direction for supervised classification by incorporating semantic information.